







 本文介绍了AUC、KS评价指标、洛伦兹曲线、Gini系数、Lift曲线和Gain曲线在机器学习中的作用。AUC是ROC曲线下的面积,衡量二分类模型的性能;KS关注模型风险区分能力;洛伦兹曲线和Gini系数用于评估坏样本分布;Lift和Gain曲线分别反映模型相对于随机选择的提升和整体精准度。这些指标有助于评估和选择模型。
本文介绍了AUC、KS评价指标、洛伦兹曲线、Gini系数、Lift曲线和Gain曲线在机器学习中的作用。AUC是ROC曲线下的面积,衡量二分类模型的性能;KS关注模型风险区分能力;洛伦兹曲线和Gini系数用于评估坏样本分布;Lift和Gain曲线分别反映模型相对于随机选择的提升和整体精准度。这些指标有助于评估和选择模型。
文章目录
关于AUC、KS评价指标、洛伦兹曲线、Gini系数、Lift曲线和Gain曲线。在别人的博客里看到下面的一个小故事:
故事是这样的:
首先,混淆矩阵是个元老,年龄最大也资历最老。创建了两个帮派,一个夫妻帮,一个阶级帮。
之后,夫妻帮里面是夫妻两个,一个Lift曲线,一个Gain曲线,两个人不分高低,共用一个横轴。
再次,阶级帮里面就比较混乱。
1.帮主是ROC曲线。
2.副帮主是KS曲线,AUC面积。
3.AUC养了一个小弟,叫GINI系数。
1.AUC
AUC为ROC曲线下的面积,用于作为二分类模型的评价指标。
要理解AUC,首先得明白混淆矩阵。
1.1.混淆矩阵
混淆矩阵如下:
| 真 | 实 | ||
|---|---|---|---|
| 1(真) | 0(假) | ||
| 预 | 1(阳) | TP(真阳) | FP(伪阳) |
| 测 | 0(阴) | FN(伪阴) | TN(真阴) |
真阳率(召回率) T P R = T P T P + F N TPR=\frac{TP}{TP+FN} TPR=TP+FNTP,表示的是,所有真实类别为1的样本中,预测类别为1的比例。TPR越大,表示越有可能是对的。
伪阳率 F P R = F P F P + T N FPR=\frac{FP}{FP+TN} FPR=FP+TNFP,表示的是,所有真实类别为0的样本中,预测类别为1的比例。
1.2.ROC曲线
横轴为FPR,纵轴为TPR。目的是希望FPR尽可能小,TPR尽可能大。
画出来的图一般如下图所示:
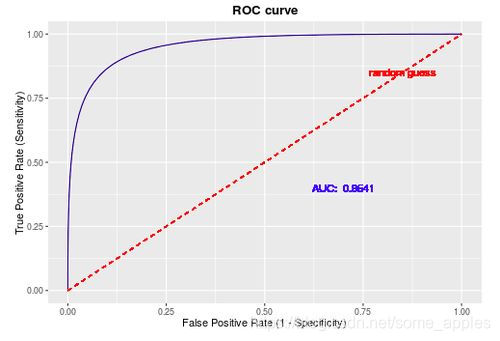
通过模型预测得到各样本的预测值(如0.6、0.7等),则通过选择归于正类的阈值来判断各个样本的类别,之后则可以计算对应的TPR和FPR。常常将得到的各个样本值对应的预测值作为阈值,并计算对应的TPR和FPR。之后将得到的各点与(0,0)和(1,1)相连,则得到了ROC曲线。之后,计算ROC曲线下的面积则有AUC值。
1.3.关于AUC值
AUC值在[0.5,1]中,0.5代表模型并无分类效果。若小于0.5则表示还不如随机猜测,但是此时如若反向预测,则得到的模型优于随机猜测。AUC值越高越好。
此外,AUC值相比于准确率这一指标好的优势在于对数据不平衡的数据集构建的模型有更好的评价意义。
例:在反欺诈场景中,0占99.9%,1占0.1%。若此时有个模型将样本全预测为0,则准确率为99.9%。虽然看起来拥有很高的准确率,但全预测为0无异于瞎猜,这样的模型并没有实际的区分能力。而当我们计算这个模型的AUC值时,就会发现,该模型的AUC值为0.5,表示并没有分类能力。这就是AUC的优势😉
2.KS评价指标
通过衡量好坏样本的累计分布的差值来评估模型的风险区分能力。
定义: K S = M A X ( T P R − F P R ) KS=MAX(TPR-FPR) KS=MAX(TPR−FPR)
KS与AUC均使用TPR、FPR两个指标,区别在于:
-
KS取的是TPR与FPR的差的max,可通过此找到最优阈值;
-
AUC评价的是模型整体的效果,并没给出好的切分阈值。
得到KS曲线如下图所示:
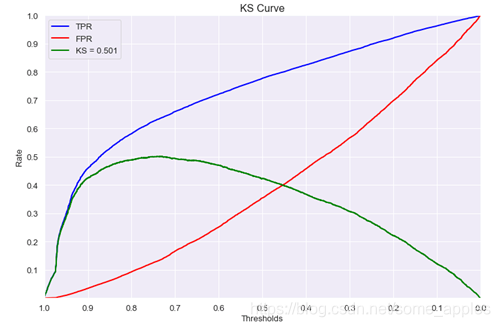
前期TPR提升越快,模型效果越好。KS取值范围 模型效果 KS<0.2 无区分能力
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 199
199

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









