







转载自:http://blog.csdn.net/map_lixiupeng/article/details/42296087
数据仓库之前的文章也说过已经从支持战略决策到支持战略决策和战术决策。对应战术是基本是现在企业对应数据价值的最大的挖掘,战术可以是局部数据的战术和全局数据的战术。
ok,说到这里我们建设数据仓库的目的也就明确了,简单来说就是支持数据挖掘+数据统计。数据挖掘我们是指对细粒度的数据的价值的提取,数据统计是将数据从细粒度数据变成粗粒度的数据,好让咱们分析师、老板、运营、产品等人直接从数据快速的进行分析和总结。
数据从细粒度到粗粒度的变化其价值也是在不断的减小。
数据仓库数据分为离线和在线实时数据。这两部分的数据仓库是分开单独建立的。
1、离线数据仓库是进行了数据的分层建模,数据是从细粒度---》粗粒度转变,更加便于信息价值提取,但是总体数据价值在减少。目前我们采用的方案是数据资源池+关系型数据仓库的设计进行解决的。即Hadoop+Hive+greenplum+MySQL解决方案。
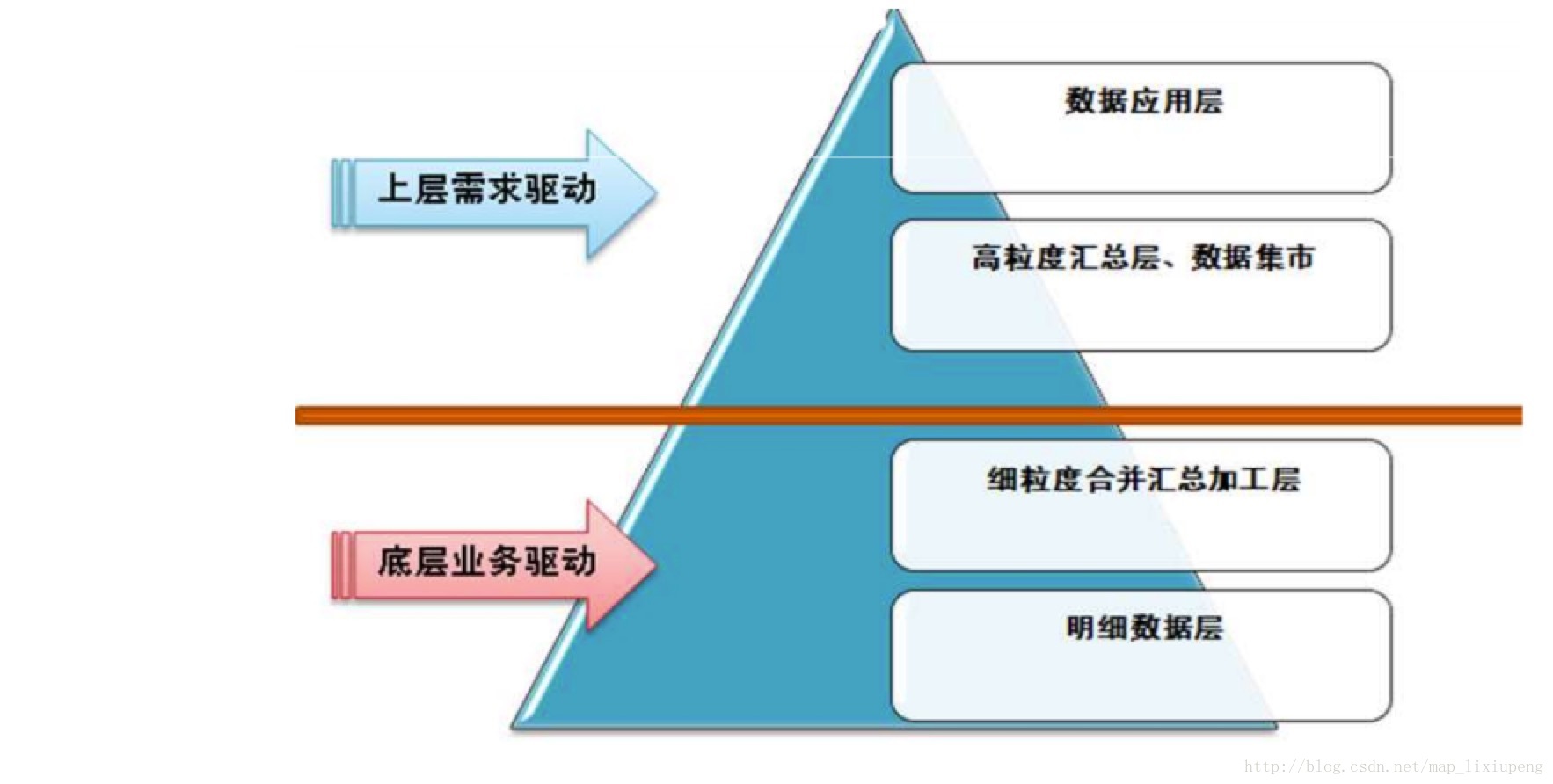
2、实时数据仓库,设计即个难点就是数据仓库的设计,窗口设计的大小也就是数据计算量的增加的倍数。使用到得技术主要是队列、分布式流式计算、存储问题。我们的解决方案是storm+Spark streaming+hbase+kafka
整体数据仓库的架构如下图所示:
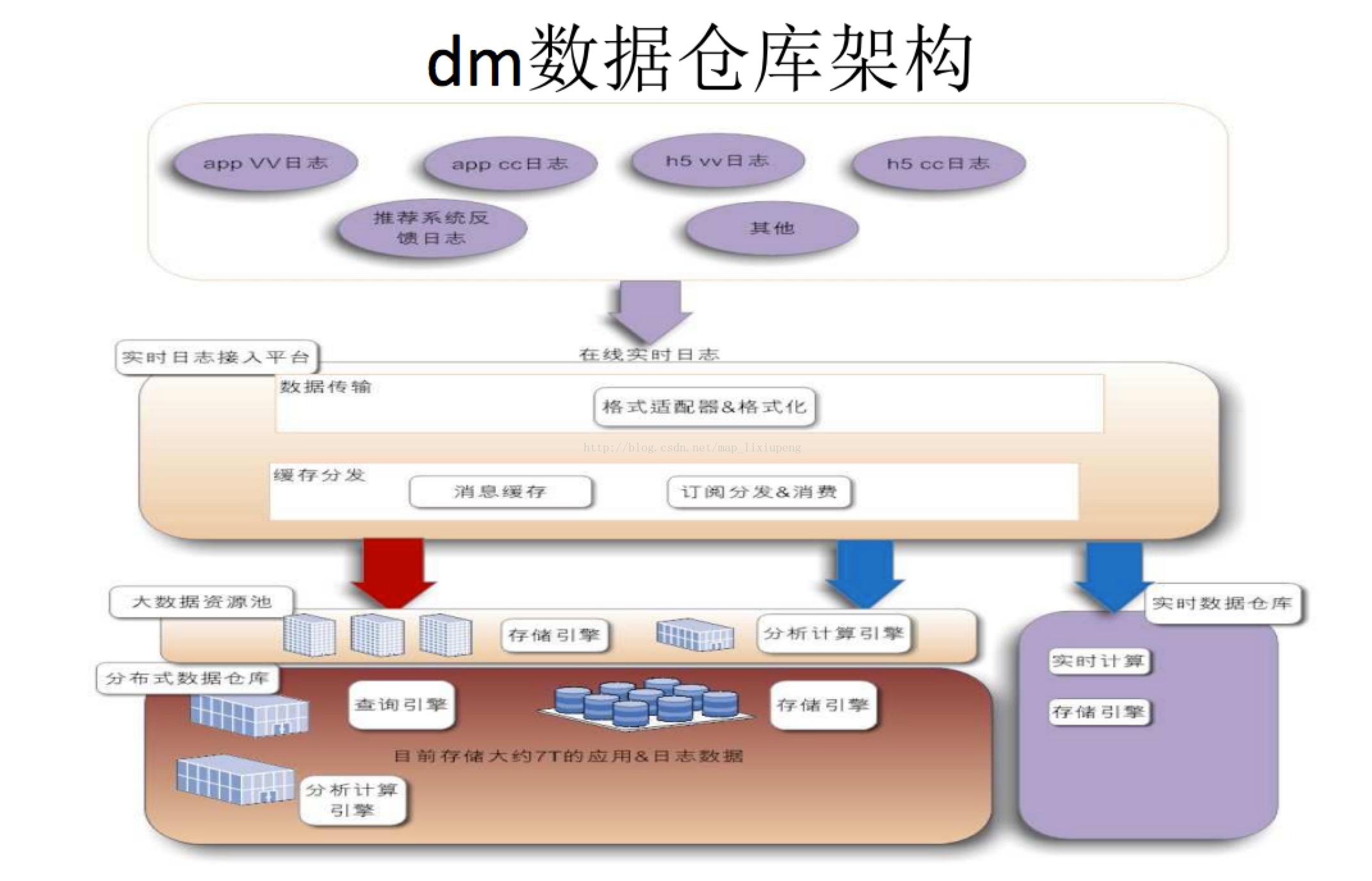
我们产出了什么尼?离线和实时简单分别简单举例所一个产品吧。
1、 实时其中一个窗口就是关于一个视频最近四天行为合并成一个窗口。
2、 离线窗口说一个数据产品,咱们就提目前比较热得用户画像。
这里的数据我就不展示了,如有兴趣交流的话,欢迎发送邮件到vocadata@foxmail.com
我们是数据挖掘组,目前的产品主要有相关推荐、美剧个性化、猜你喜欢产品等。目前我们这边又个原则就是天下武功为快不破,给大家看看我们内部门面,如下图所示。我们今年下半年主要发力在推荐系统,我主要负责推荐系统数据流程存储和计算架构。我们组奉行“天下武功 唯快不破”的原则。在我设计实时主动型的数据仓库,我认为实时内容的有效性、易用性和满足业务需要的设计是我一直在思考的问题,我之前也做过机器学习方面的工作,对应上层数据挖掘程序开发对数据的需要又一定的理解,所以设计其他比较得心应手。架构设计中我感觉最困难就是在做选择题和对未来的规划。
说得内容比较乱,大家简单理解下得,2014年最后一天上班了。今天就简单写到这里,今天就早点下班。呵呵,大家新年愉快~~~
















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









