







背景:平台性能瓶颈,内存32G
做通做对 - 做大做深 - 做精做好
阶段一:做通做对
阶段意义:对方案的有效性与合理性进行验证探索。一般资源很少,如果顺利解决了核心问题,那系统将初具业务价值
阶段二:做大做深
阶段意义:开始在初版的基础上,去做边界的探索。通过接入更多的场景,更大范围的解决业务问题,来打磨方案,拓宽能力边界并摸索沉淀下最优实践。
阶段三:做精做好
阶段意义:这是做减法和重构的过程,通过前面的探索,清晰的定义下系统的边界,并对交互和性能等方面做更深的耕耘。

数据流向图
定位和目标
旨在提供数据端到端实时处理能力(毫秒级/秒级/分钟级延迟),可以对接多数据源进行实时数据抽取,可以为多数据应用场景提供实时数据消费。让实时数据应用开发门槛更低、迭代更快、质量更好、运行更稳、运维更简、能力更强,为实现数据驱动公司发展打下坚实基础!
整体设计
-
数据应用:是否考虑典型业务场景?(数据驱动场景,数据分析场景,数据交换场景)
-
数据服务:数据挖掘,数据可视化,日常管理运营
-
数据存储:数仓建设模型选型与搭建,数据分类,数据存储模式(HDFS)
-
数据加工:内部数据(flink),外部数据(多为离线场景,spark?)
-
数据采集:内部数据(flinkcdc+kafka),外部数据(爬虫?接口?)
-
数据源:结构化数据,日志数据,其他数据形式(excel?)
具体问题和思路
-
功能考量
-
流式处理平台和计算服务平台就形成了计算闭环
-
ETL复杂逻辑场景的处理
-
高TPS查询场景:历史、实时数据分开处理与合并
-
-
质量考量
-
从技术架构层面保证数据质量
-
-
稳定考量
-
高可用HA:整个实时链路都应该选取高可用组件,确保理论上整体高可用;在数据关键链路上支持数据备份和重演机制;在业务关键链路上支持双跑融合机制
-
SLA保障:支持动态扩容和数据处理流程自动漂移
-
监控预警:集群设施层面,物理层面,数据逻辑层面的多方面监控预警能力
-
自动运维:能够捕捉并存档缺失数据和处理异常,并具备定期自动重试机制修复问题数据
-
上游元数据变更抗性:兼容性元数据变更,自动处理
-
-
成本考量
-
人力成本:降低开发门槛
-
资源成本:支持动态资源利用降低静态资源占用造成的资源浪费
-
运维成本:支持自动运维/高可用/弹性机制降低运维成本
-
试错成本:支持敏捷开发/快速迭代降低试错成本
-
-
敏捷考量
-
配置化,SQL化
-
-
管理考量
-
元数据管理和数据安全管理
-
数据处理:实时数据和历史数据分离(高TPS要求的场景)
监控系统:搭建大数据监控体系,输出《大数据监控管理规范》
数据挖掘:
数据分析:
-
配置WEB数据查询平台(参考开源的项目),通过自编写SQL的形式由各业务/部门查询常用数据及指标。
-
优点:
-
通过角色权限分配,确保数据查询权限。
-
为各部门提供简易数仓,并提供数仓结构图,简化ETL过程,部分需求可下放至数据分析部门。
-
各部门各根据自身需要编写简单SQL去查询、下载数据,以供日常数据分析汇报使用,较少数据部门取数需求。
-
所有的基础数据及业务宽表由数据部门提供,保证数据产出的一致性。
-
基于该平台提供的简单可视化工具,做一些重要业务的预警机制(sql)
-
-
缺点:
-
各部门/业务人员需要了解简单的SQL语法
-
数仓建设需要规范化,需要研究通用数仓模型,以便后续更好地维护各业务数仓体系
-
需要提供规范化的SQL编写标准
-
大量的查询需求进来时,会造成资源紧张,需做好资源监控及预警机制
-
-
混合云
云上数仓:提供稳定高可用数据服务
云下计算存储:数据同步、实时计算、元数据存储
平台模块精细化管理
-
数据服务模块
-
离线计算模块
-
实时计算模块
-
数据同步模块
-
数据存储模块
当前平台不足
-
受限于虚拟机存在性能瓶颈:(1) 内存单机只能32G (2)虚拟机无法使用AVX指令集
-
缺乏一套数据开发IDE来管理整个数据开发环节
-
大数据组件开发要求高,如Flink代码开发,Debezium\DataX\Canal\FlinkCDC\FlinkX使用
-
需要维护两套计算模型批计算和流计算,难以上手开发,需要提供一套流批统一的SQL
-
缺乏公司层面的元数据体系规划,同一条数据实时和离线难以复用计算,每次开发任务都要各种梳理
解决方案
-
配置升级:采购物理机,单机内存可达256G,可以指令集加速计算,发挥向量化引擎优势
-
统一集群:打通云上云下,cdh与DataWorks开发工具集成一体,AliCloud和IDC混合部署,提高资源利用率
-
降低开发门槛
-
推广FlinkCDC统一数据集成方式
-
探索并应于FlinkSql,实现流批统一的SQL
-
-
全面管理:建设数管平台,结合数据治理,做好元数据管理
时效、易用、安全可靠和降本增效
-
时效
-
FlinkCDC + Kafka 实现元数据实时入仓
-
-
易用
-
一站式开发
-
流批统一SQL
-
-
安全可靠
-
角色权限管理,表级别授权
-
操作日志审计
-
容灾管理、数据热备
-
-
降本增效
-
固定资源 + 弹性资源混合部署架构
-
物理机服务器:固定任务负载固定
-
阿里云+虚拟机:峰值任务弹性伸缩
-
-
拓扑图
待补充:大数据平台v2.0拓扑图,硬件规划
大数据平台v1.0拓扑图
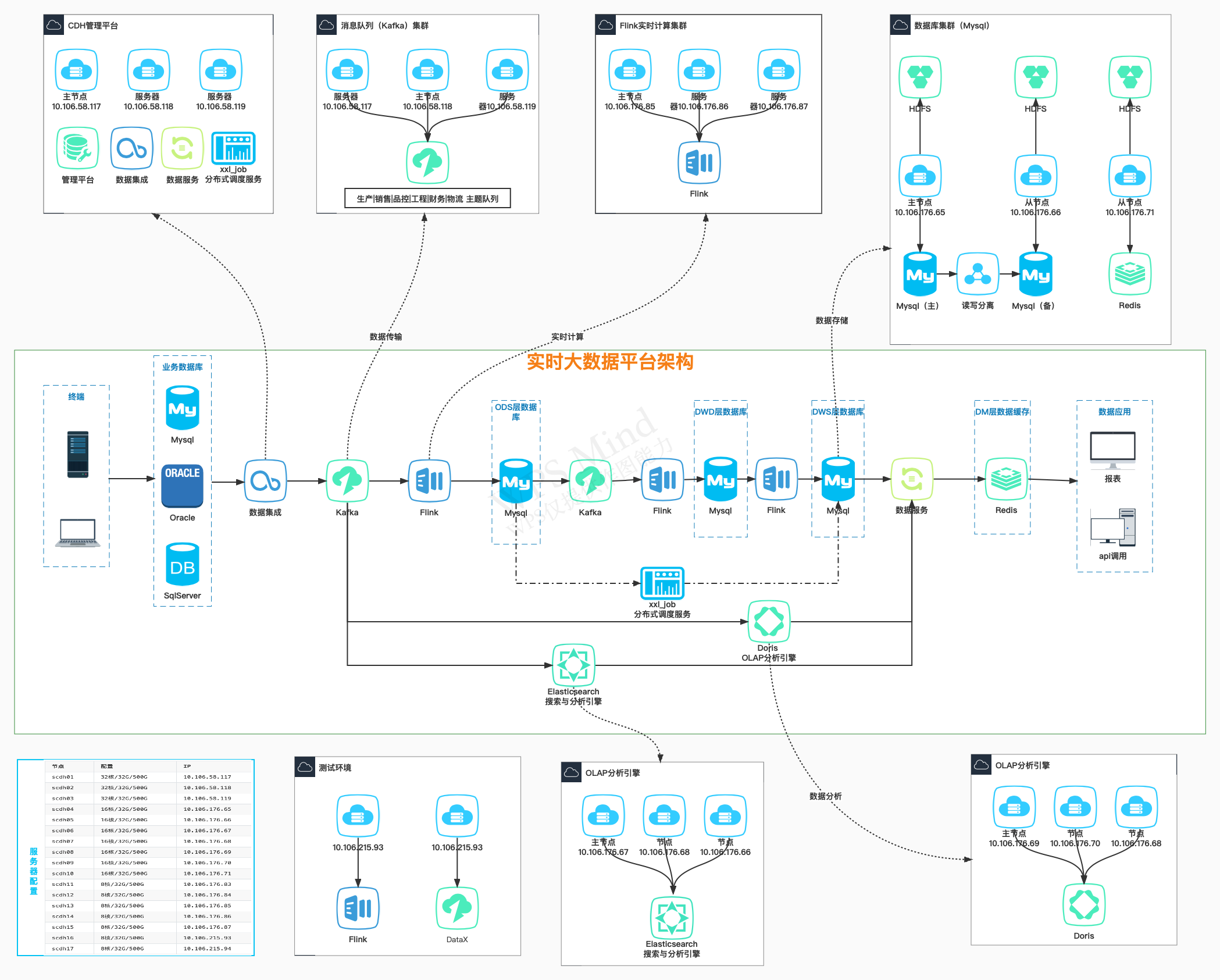
















 687
687











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











