







总览:简单分类,以便记忆:
A. 快速排序 其实是 冒泡排序 的升级,它们都属于交换(比较、移动交换)排序类;(增大了数据 比较和移动 的距离,减少了比较次数 和 移动交换次数)
B. 希尔排序 其实是 直接插入排序 的升级,它们都属于插入排序类;(划分增量子序列,在子序列中进行直接插入排序)
C. 堆排序 其实是 选择排序 的升级,它们都属于选择排序类;
1、冒泡排序:
冒泡排序的 基本思想是:两两比较相邻的数据,如果反序,则交换;知道没有反序位置。每一趟都会把一个数字放到最终的位置上!时间复杂度O(N^2)。
// 冒泡排序
/*
* 特别注意内层循环:
*(1)另外一种写法:
for (vector<int>::iterator i = data.begin(); i != data.end() && swapFlag; i++)
for (vector<int>::iterator j = data.end() - 2; j >= i; --j)
if (*j > *(j + 1)) // “j=data.end()-2” 的原因,防止越界
if (j == i) // 第一趟循环时i是begin(),如果不进行特殊处理,--j会造成vector的越界。
break;
*(2)if (j == i)
break;
*/
void bubbleSort(vector<int>& data)
{
if (data.size() == 0)
{
return ;
}
bool swapFlag = true; // 冒泡排序优化:当“某”过程中 未 发生交换时,则停止整个排序过程(因为是相邻数据两两比较)
for (vector<int>::iterator i = data.begin() + 1; i != data.end() && swapFlag; i++) //注意:i = data.begin() + 1
{
swapFlag = false;
for (vector<int>::iterator j = data.end() - 1; j >= i; --j) // end()指向的是最后一个元素的下一个位置
{
if (*j < *(j - 1))
{
std::swap(*j, *(j - 1)); // 升序
swapFlag = true; // 如果有数据交换,则swapFlag为true
}
}
}
}
void bubbleSort2(int *data, int length)
{
bool swapFlag = true; // 冒泡排序优化:当某趟过程中未发生交换,则停止整个排序过程(因为是相邻数据两两比较)
for (int i = 1; i < length && swapFlag; i++) // 注意:i = 1;
{
swapFlag = false;
for (int j = length - 1; j >= i; j--) // j从后往前循环
{
if (data[j] < data[j - 1])
{
std::swap(data[j], data[j - 1]);
swapFlag = true; // 如果有数据交换,则swapFlag为true
}
}
}
}
2、选择排序:
选择排序 的基本思想是:每一趟在 n - i + 1 个记录中选取最小值(n-i次比较),然后和第i个记录交换(有序序列的第i个记录)。时间复杂度O(N^2)。但是减少了交换移动次数。(冒泡排序的思想是在不断地进行交换)
// 选择排序
void selectSort(vector<int>& data)
{
int min = 0;
for (int i = 0; i < data.size(); i++)
{
min = i;
//每一趟在 n - i + 1 个记录中选取最小值(n - i次比较),然后和第 i 个记录交换(即这个最小值作为有序序列的第i个记录)
for (int j = i + 1; j < data.size(); j++)
{
if (data[j] < data[min])
{
min = j; // 选择出最小值的下标
}
}
if (i != min) // 交换
{
std::swap(data[i], data[min]);
}
}
}
3、快速排序
快速排序 其实是 冒泡排序 的升级,它们都属于交换(比较、交换移动)排序,都是通过不断比较和移动交换来实现排序的。但是,快速排序增大了数据 比较和交换移动 的距离(不再是相邻数据两两比较),将关键字较大的记录从前面直接交换移动到后面,关键字较小的记录从后面直接交换移动交换到前面,减少了比较次数 和 交换移动次数。
快速排序 的基本思想:通过一趟排序,将待排记录分割成独立的两部分,其中一部分记录均比另外一部分的记录小。然后对这两部分递归上述步骤,直到整个序列有序。
每一趟都会把基准元素放到最终位置。
快速排序也是基于分治处理的,时间复杂度最好情况下(递归树划分较均匀):O(N * logN),很显然是取决于递归的深度。最坏情况是,待排序列为正序或者逆序,每次划分只得到一个比上一次划分少一个记录的子序列,注意另一个为空(也就是一颗斜树)。
版本1:
//快速排序版本1
void quickSort1(int *data, int left, int right)
{
if (left < right)
{
int low = left;
int high = right;
int key = data[low]; // 基准元素
while (low < high) // 从数据表的两端交替向中间扫描
{
while (low < high && data[high] >= key) // 从右向左找第1个小于基准值的位置high
high--;
if (low < high) // 找到了
{
data[low] = data[high]; // 采用替换而不是交换
low++;
}
while (low < high && data[low] <= key) // 从左向右找第1个大于基准值的位置low
low++;
if (low < high) // 找到了
{
data[high] = data[low]; // 采用替换而不是交换
high--;
}
}
data[low] = key; // 将基准元素放入最终位置,本次划分结束
quickSort1(data, left, low - 1); // 对左半部递归
quickSort1(data, low + 1, right); // 对右半部递归
}
}
版本2:
//快速排序版本2
int partition(int *data, int low, int high)
{
//partition函数就是要把关键字(枢轴)——data[low]放到最终位置上。(使得它左边的值都比它小,右边的值都比它大)
int key = data[low];
while (low < high)
{
while (low < high && data[high] >= key)
high--;
std::swap(data[low], data[high]); // 比枢轴小的记录交换到低端
while (low < high && data[low] <= key)
low++;
std::swap(data[low], data[high]); // 比枢轴大的记录交换到高端
}
return low; // 返回关键字所在位置
}
void quickSortCore(int *data, int low, int high)
{
int pivot;
if (low < high)
{
pivot = partition(data, low, high);
quickSortCore(data, low, pivot - 1);
quickSortCore(data, pivot + 1, high);
}
}
void quickSort2(int *data, int length)
{
quickSortCore(data, 0, length - 1);
}4、直接插入排序:
直接插入排序 的基本思想是:将一个数据插入到前面已经排好序的有序表中,从而得到一个新的、记录数增1的新有序表。每趟保证前面部分有序!时间复杂度O(N^2)。直接插入排序适合于数据表本身基本有序的情况。
// 直接插入排序
void insertSort(int *data, int length)
{
for (int i = 1; i < length; i++)
{
if (data[i] < data[i - 1]) // 优化:如果需要将data[i]插入前面的有序子表,才执行
{
int tmp = data[i]; // 暂存待插元素
int j;
// 将数据插入到前面已经排好序的有序表中,从而得到一个新的、记录数增1的新有序表
for (j = i - 1; j >= 0 && tmp < data[j]; --j)
{
data[j + 1] = data[j]; // 数据后移
}
data[j + 1] = tmp; // 插入到正确位置
}
}
}
5、希尔排序:
我们知道上面的直接插入排序适合于 数据表中数据较少 或者 数据表本身基本有序 的的特殊情况。
希尔排序 的基本思想是:将现实中的大量数据分割成若干子序列,在这些子序列内进行直接插入排序,最后再对全体记录(此时整个序列已经“基本有序”——较小的关键字在前面,不大不小的关键字在中间,较大的关键字在后面)进行一次直接插入排序。
希尔排序的关键在于分割!我们通常采用“跳跃分割策略”——将相距某个“增量”的记录组成一个子序列,这样才能保证在各个子序列内分别进行直接插入排序后,得到的结果是“基本有序”而不是“局部有序”!(初始序列:9,1,5,8,3,7,4,6,2)(局部有序:{1,5,9}、{3,7,8}、{2,4,6})(基本有序:{2,1,3}、{6,4,7}、{5,8,9})
这里的增量子序列的步长是关键问题!也就说希尔排序的子序列并不是随便分组各自排序,而是将相隔某个“增量”的记录组成一个子序列,实现跳跃式的移动,从而提高效率。
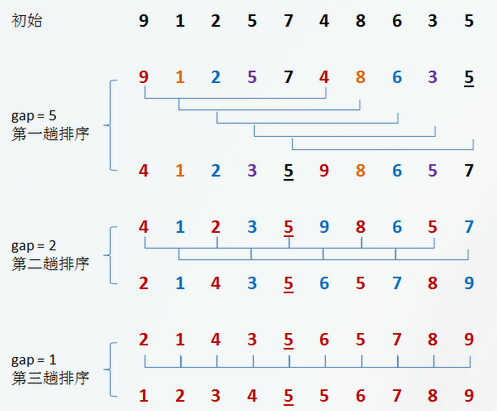
// 希尔排序
void shellSort(int *data, int length)
{
//int num = 1, count = 1;
int disLen = length;
while (disLen > 1)
{
disLen = disLen / 2; // 增量子序列, “增量步长”是 disLen / 2
for (int i = disLen; i < length; i++)
{
if (data[i] < data[i - disLen])
{
int tmp = data[i]; // 待排元素
// 直接插入排序
int j;
for (j = i - disLen; j >= 0 && tmp < data[j]; j -= disLen) // 寻找data[i]的插入位置
{
data[j + disLen] = data[j]; // 数据后移
}
data[j + disLen] = tmp; // 插入
}
/*cout << "第" << num++ << "次排序:";
for (int i = 0; i < length; i++)
{
cout << data[i] << " ";
}
cout << endl;*/
}
/*cout << endl;
cout << "第" << count++ << "趟排序:" <<endl;
for (int i = 0; i < length; i++)
{
cout << data[i] << " ";
}
cout << endl << endl;;*/
}
}
运行:(排序详细过程)
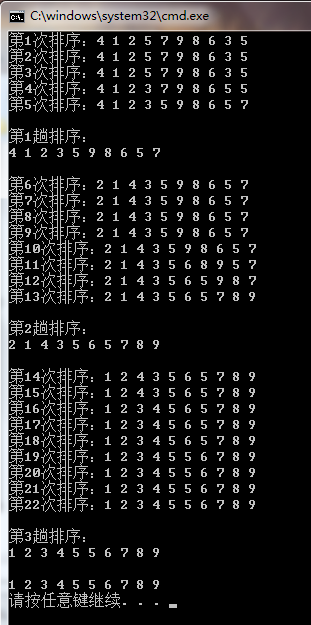
6、归并排序:
归并排序 的基本思想:把待排序列的N个记录看成N个有序的子序列,然后进行两两归并;然后对N/2 个子序列继续两两归并,直到N个记录全部有序。
归并排序也是基于分治的,时间复杂度:O(N * logN)。
//将二个有序数列 a[first...mid] 和 a[mid...last] 合并。
void mergearray(int a[], int first, int mid, int last, int temp[])
{
int i = first, j = mid + 1;
int m = mid, n = last;
int k = 0;
while (i <= m && j <= n)
{
if (a[i] <= a[j])
temp[k++] = a[i++];
else
temp[k++] = a[j++];
}
while (i <= m)
temp[k++] = a[i++];
while (j <= n)
temp[k++] = a[j++];
for (i = 0; i < k; i++)
a[first + i] = temp[i];
}
void mergesortCore(int a[], int first, int last, int temp[])
{
if (first < last)
{
int mid = (first + last) / 2;
mergesortCore(a, first, mid, temp); //左边有序
mergesortCore(a, mid + 1, last, temp); //右边有序
mergearray(a, first, mid, last, temp); //再将二个有序数列合并
}
}
//“分解”——将序列每次折半划分
//“合并”——将划分后的序列段两两合并后排序
bool mergeSort(int a[], int n)
{
int *p = new int[n];
if (p == NULL)
return false;
mergesortCore(a, 0, n - 1, p);
delete[] p;
return true;
}













 1683
1683











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









