







转载:原文链接
简述HashTable的原理
HashTable是一种数据结构,通过key可以直接的到value,查找值时间总为常数级别O(1)。
原理
HashTable底层是使用了数组实现的。数组只要知道了索引,查找值的速度是很快的,为常数级别O(1)。数组的索引为数组,HashTable通过一个Hash函数,把key(字符串、数字等可哈希的对象)变成数组的索引。然后就像操作数组一样来查值和找值。
我使用的是time33哈希函数,这个函数的原理在这里我就不再叙述了。
用C代码实现为:
unsigned int time33(char *key){
unsigned int hash = 5381;
while(*key){
hash += (hash << 5 ) + (*key++);
}
return (hash & 0x7FFFFFFF) % MAX_SIZE;
}
值得注意的是:return (hash & 0x7FFFFFFF) % MAX_SIZE;。正常情况下(hash & 0x7FFFFFFF)输出的数字范围是非常广的,这就会导致HashTable底层的数组需要非常大的长度。(如果Hash函数输出范围是0-10,那么底层数组的长度就需要10,如果数组长度不够则会导致溢出。比如,你输入某个值,计算的索引为8,但你的数组长度只有5,很明显你无法对数组索引为8的值合法的操作。)
所以,这里使用了求余%,限定了输出值的大小必定小于MAX_SIZE。
其次,还需要注意的是哈希冲突。比如对于两个不相同的key计算出了相同的hash。这种事情是绝对会发生的,因为你将一个大的集合映射到小的集合上。解决冲突的方法有很多,这里使用的是链表法。也就是,数组上没一个索引下的值实际上存储的是一个链表。链表的节点才是真正的记录了key和value的容器。
使用图来说明就是:
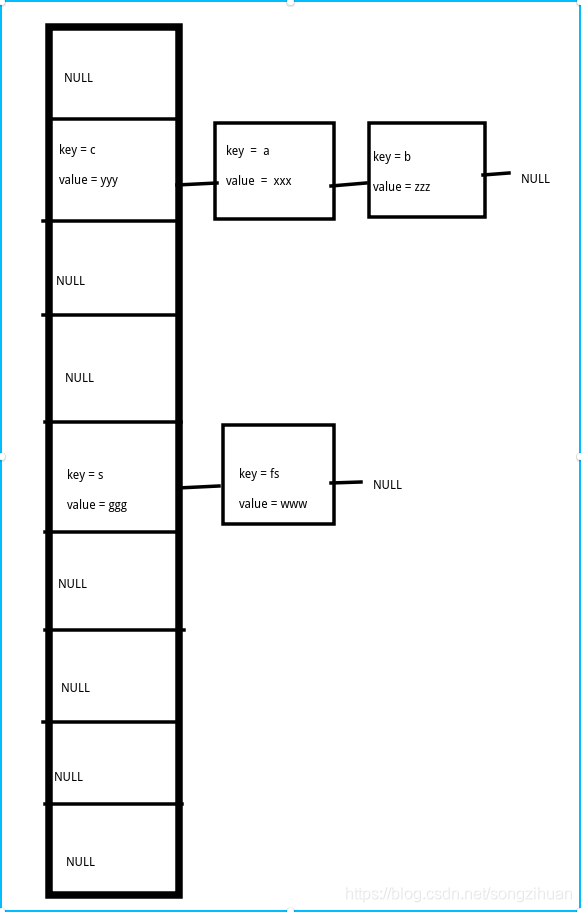
使用C语言的实现
“table.h”
#ifndef MAX_SIZE
#define MAX_SIZE (1024 ^ 2)
// 定义哈系表的范围(也就是通过time_33哈系后的值在跟MAX_SIZE整除,从而限定了范围)
// 一个捅,由key和value组成,同时next为链表所用[解决哈系冲突]
typedef struct HashNode
{
char *key;
char *value;
struct HashNode *next; // Hash冲突
} HashNode;
// 一张哈希表,由一个指针组成,该指针起数组作用,内部存储捅的指针
typedef struct HashTable{
struct HashNode **HashNode; // 这是一个指针数组
} HashTable;
HashTable *make_HashTable();
HashNode *make_HashNode(char *key, char *value);
int login_node(HashTable *ht, HashNode *hn);
HashNode *find_node(HashTable *ht, char *key);
#endif
在头文件中,我定义了HashNode,也就是链表的节点。以及HashTable,本质上是存储一个以HashNode的指针为值的数组。
HashNode也就是前文所属的桶,或者称他为链表的节点。HashTable也就是前文所属的哈希表,底层由一个数组实现。
“main.c”
#include <stdio.h>
#include "table.h"
#include <stdlib.h>
int main(){
HashTable *ht = make_HashTable();
HashNode *tmp1 = make_HashNode("YY","Hello"), *tmp2 = make_HashNode("ZZ","World");
login_node(ht, tmp1);
login_node(ht, tmp2);
printf("YY = %s, ZZ = %s\n", find_node(ht, "YY")->value, find_node(ht, "ZZ")->value);
return 0;
}
HashTable *make_HashTable(){ // 生成并初始化
HashTable *tmp = NULL;
size_t size = sizeof(HashNode) * MAX_SIZE;
tmp = malloc(sizeof(HashTable));
tmp->HashNode = malloc(size);
for(int i = 0; i < MAX_SIZE; i++){
tmp->HashNode[i] = NULL; // 初始化
}
return tmp;
}
HashNode *make_HashNode(char *key, char *value){ // 生成并初始化
HashNode *tmp = NULL;
tmp = malloc(sizeof(HashNode));
tmp->key = key;
tmp->value = value;
tmp->next = NULL;
return tmp;
}
// 使用time33算法,把key换算成为索引,生成索引的范围在0-MAX_SIZE上[因为有 % MAX_SIZE]
unsigned int time33(char *key){
unsigned int hash = 5381;
while(*key){
hash += (hash << 5 ) + (*key++);
}
return (hash & 0x7FFFFFFF) % MAX_SIZE;
}
// 添加一个桶
int login_node(HashTable *ht, HashNode *hn){
// 检查数据是否合法
if(hn == NULL){
return 1;
}
else if(ht == NULL){
return 1;
}
// 计算下标
unsigned int index = time33(hn->key);
HashNode *base_node = ht->HashNode[index]; // 根据下标拿base节点
if(base_node == NULL){
ht->HashNode[index] = hn; // 无冲突
}
else{
// 有冲突
while(1){
if(base_node->next == NULL){ // 迭代找到最后一个节点
break;
}
base_node = base_node->next; // 迭代
}
base_node->next = hn; // 给链表赋值
}
return 0;
}
HashNode *find_node(HashTable *ht, char *key){
// 检查数据是否合法
if(ht == NULL){
return NULL;
}
// 计算索引
unsigned int index = time33(key);
HashNode *base_node = ht->HashNode[index]; // 根据下标拿base节点
if(base_node == NULL){ // 没有节点
return NULL; // 返回NULL表示无数据
}
else{
while(1){
if(!strcmp(base_node->key, key)){ // 比较字符串的值,不可以直接使用 == [char *是指针,==只是比较俩字符串的指针是否一致]
return base_node;
}
else if(base_node->next == NULL){ // 迭代找到最后一个节点,依然没有节点
return NULL;
}
base_node = base_node->next;
}
}
return NULL;
}
make_HashTable和make_HashNode用于初始化HashNode和HashTable。先请求内存,然后赋默认值。知道注意的是,HashTable需要提前向分配好数组大小。注意,MAX_SIZE一旦改变,所有的值都需要重新hash。也就是HashTable在扩张的时候,首先要申请一个更大的内存,然后把原本数组上的值重新计算hash,然后填入新的数组中。最后记得要是释放原来的数组。
login_node是往HashTable中添加一个HashNode,首先计算HashNode的key的索引。如果数组该索引下的值为NULL,则把HashNode作为链表根节点,把它的地址保存在数组中。否则,则迭代整个链表到末尾,再追加这个节点。
find_node是从HashTable中根据key读取HashNode。原理其实同login_node一样,先计算key的hash,然后读取数组索引下的值。若为NULL,则表示这个key不存在,否则就迭代链表,对比每个节点的key是否为目标key。
Hash函数
一个好的Hash函数应该具有:运算快速、并且分布均匀的特点。
何为分布均匀?就是输出值要尽量均匀分布,从而减短链表的长度。[如果说,我输入1w个值,输出值总是在100-200的这个范围,而0-100这个范围却很少,那么就说明这个Hash函数可能不是很好的Hash函数]
这里使用了time33算法,是一个不错的Hash函数。
特别提示:这个Demo没有实现删除功能也没有释放内存,不建议直接使用。















 541
541











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











