









语音文字转换 (STT) 系统就像它名字所蕴含的意思那样,是一种将说出的单词转换为文本文件以供后续使用的方法。
-- Simon James
语音文字转换技术非常有用。它可以用到许多应用中,例如自动转录,使用自己的声音写书籍或文本,用生成的文本文件和其他工具做复杂的分析等。
在过去,语音文字转换技术以专有软件和库为主导,要么没有开源替代品,要么有着严格的限制,也没有社区。这一点正在发生改变,当今有许多开源语音文字转换工具和库可以让你随时使用。
这里我列出了 5 个。
1. DeepSpeech 项目
该项目由 Firefox 浏览器的开发组织 Mozilla 团队开发。它是 100% 的自由开源软件,其名字暗示使用了 TensorFlow 机器学习框架实现其功能。
换句话说,你可以用它训练自己的模型获得更好的效果,甚至可以用它来转换其它的语言。你也可以轻松的将它集成到自己的 Tensorflow 机器学习项目中。可惜的是项目当前默认仅支持英语。
它也支持许多编程语言,例如 Python(3.6)。可以让你在数秒之内完成工作:
-
pip3 install deepspeech
-
deepspeech --model models/output_graph.pbmm --alphabet models/alphabet.txt --lm models/lm.binary --trie models/trie --audio my_audio_file.wav
你也可以通过 npm
-
npm install deepspeech
项目主页
https://github.com/mozilla/DeepSpeech
https://github.com/mozilla/DeepSpeech/releases/tag/v0.7.4
2. Kaldi

Kaldi 是一个用 C++ 编写的开源语音识别软件,并且在 Apache 公共许可证下发布。它可以运行在 Windows、macOS 和 Linux 上。它的开发始于 2009。
Kaldi 超过其他语音识别软件的主要特点是可扩展和模块化。社区提供了大量的可以用来完成你的任务的第三方模块。Kaldi 也支持深度神经网络,并且在它的网站上提供了出色的文档。
虽然代码主要由 C++ 完成,但它通过 Bash 和 Python 脚本进行了封装。因此,如果你仅仅想使用基本的语音到文字转换功能,你就会发现通过 Python 或 Bash 能够轻易的实现。
项目主页
3. Julius

它可能是有史以来最古老的语音识别软件之一。它的开发始于 1991 年的京都大学,之后在 2005 年将所有权转移到了一个独立的项目组。
Julius 的主要特点包括了执行实时 STT 的能力,低内存占用(20000 单词少于 64 MB),能够输出最优词N-best word和词图Word-graph,能够作为服务器单元运行等等。这款软件主要为学术和研究所设计。由 C 语言写成,并且可以运行在 Linux、Windows、macOS 甚至 Android(在智能手机上)。
它当前仅支持英语和日语。软件应该能够从 Linux 发行版的仓库中轻松安装。只要在软件包管理器中搜索 julius 即可。
4. Wav2Letter++
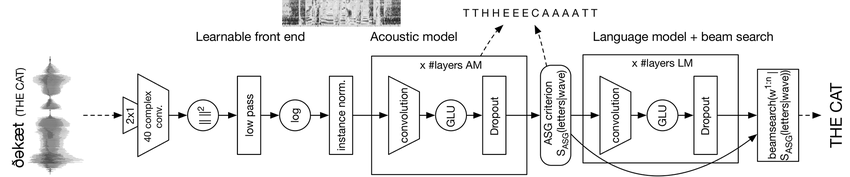
如果你在寻找一个更加时髦的,那么这款一定适合。Wav2Letter++ 是一款由 Facebook 的 AI 研究团队发布的开源语言识别软件。代码在 BSD 许可证下发布。
Facebook 描述它的库是“最快、最先进state-of-the-art的语音识别系统”。构建它时的理念使其默认针对性能进行了优化。Facebook 最新的机器学习库 FlashLight 也被用作 Wav2Letter++ 的底层核心。
Wav2Letter++ 需要你先为所描述的语言建立一个模型来训练算法。没有任何一种语言(包括英语)的预训练模型,它仅仅是个机器学习驱动的文本语音转换工具,它用 C++ 写成,因此被命名为 Wav2Letter++。
项目主页
https://github.com/facebookresearch/wav2letter
5. DeepSpeech2
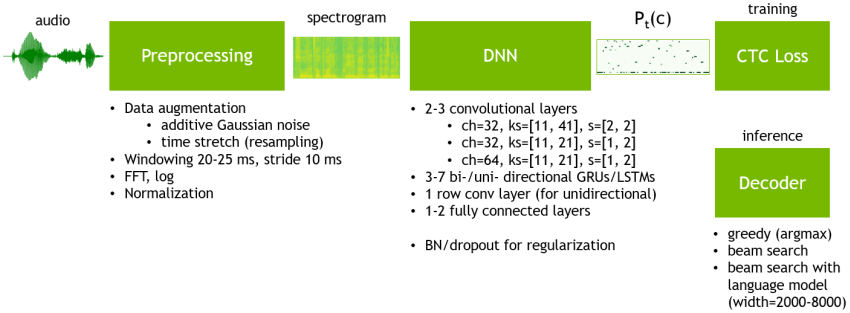
中国软件巨头百度的研究人员也在开发他们自己的语音文字转换引擎,叫做“DeepSpeech2”。它是一个端对端的开源引擎,使用“PaddlePaddle”深度学习框架进行英语或汉语的文字转换。代码在 BSD 许可证下发布。
该引擎可以在你想用的任何模型和任何语言上训练。模型并未随代码一同发布。你要像其他软件那样自己建立模型。DeepSpeech2 的源代码由 Python 写成,如果你使用过就会非常容易上手。
项目主页
https://github.com/PaddlePaddle/DeepSpeech
6. 总结
语音识别领域仍然主要由专有软件巨头所占据,比如 Google 和 IBM(它们为此提供了闭源商业服务),但是开源同类软件很有前途。这 5 款开源语音识别引擎应当能够帮助你构建应用,随着时间推移,它们会不断地发展。在几年之后,我们希望开源成为这些技术中的常态,就像其他行业那样。

















 1923
1923

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









