







AI专业术语
-
LLM
Large Language Model
即:大语言模型
-
Token的含义
在不同领域,它被赋予了不同的含义
-
-
在AI领域
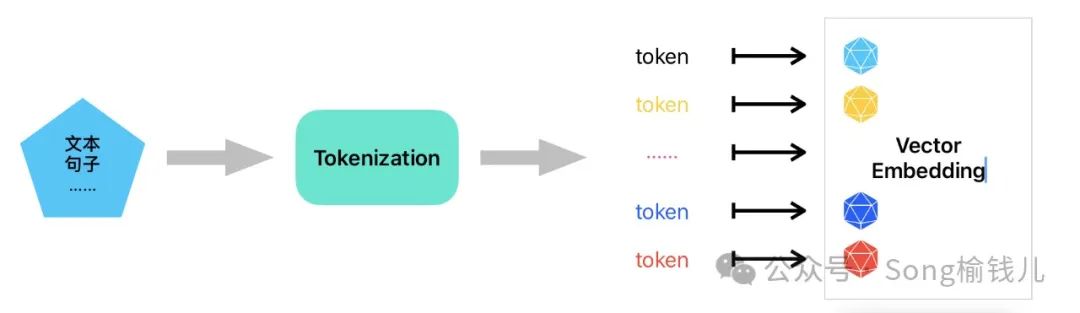
它是指最小单位的“词元”,或者说单词的“片段”,就是不可再拆分的最小语义单位,是通过Tokenization将文本句子分成若干个tokens,再进行向量嵌入……
-
在计算机安全领域
一种用于身份验证和授权的令牌,这种令牌是用于验证用户身份并授予他们访问特定资源或执行特定操作的权限
-
在区块链领域
它代表特定资产或权益的可交易数字标识符,又称“代币”
还有哪些其他领域的不同含义,请大家补充哈
-
-
Vector Embedding(向量嵌入)
把文本的意思嵌入向量里,也就是用向量来表示文本的含义。
当然,向量里面能存的可不仅仅是文本,像音频、视频都是可以用向量表示的。
补充:至于向量的作用,如:用于相似度计算、检索之类的,由于篇幅太长,放到以后介绍了哈,简单提一嘴:比如余弦相似度(Cosine Similarity)、欧氏距离(Euclidean Distance)等等
-
Prompt(提示词)
上一篇文章介绍了Prompt,大家对它已经有所耳闻,就不在此赘述
补充:当前AI是按照token来计算收费的,所以Prompt的长度要注意,省着点用哈
Ta的朋友们
-
关于向量数据库
目前主流的大家常听说是使用PineCone,其他的见下表:
| 名称 | 官网地址 | 是否开源 |
| PineCone | https://www.pinecone.io/ | 否 |
| Milvus | https://milvus.io/ | 是 |
| Qdrant | https://qdrant.tech/ | 是 |
| PGVector | https://github.com/pgvector/pgvector | 是 |
| RediSearch | https://redis.io/ | 是 |
| Weaviate | https://weaviate.io/ | 是 |
| FAISS | https://faiss.ai/ | 是 |
-
关于“外挂”知识库
试一试:若Siri(或小爱)自身所带的知识内容无法回答你的问题时,它们会怎么办?借助搜索引擎 或其他方式,姑且称之为:“外挂”
题外话:这种方式主要解决了两方面的问题:LLM模型数据存在outdated、专有领域数据安全无法让通用LLM来训练(垂直领域)
-
-
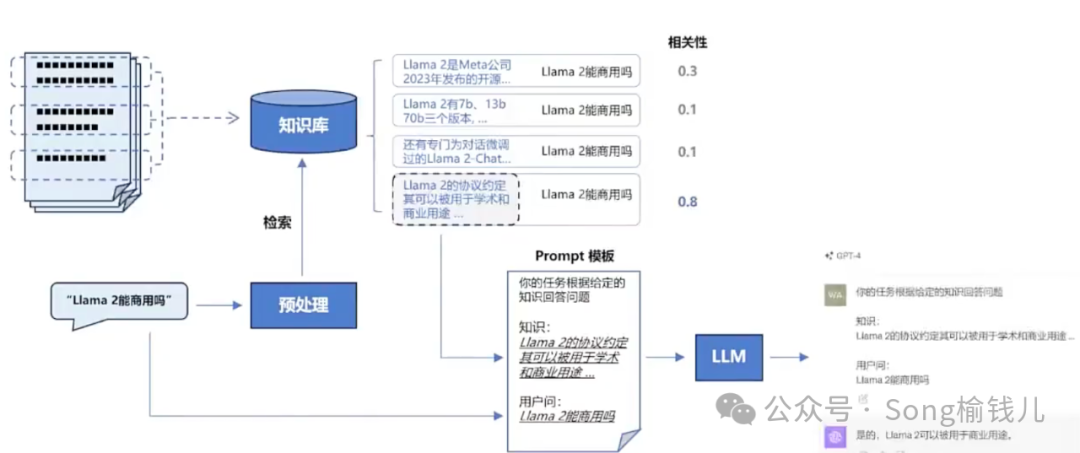
RAG(Retrieval Augmented Generation)
-
通过检索的方法来增强生成模型的能力,主要是通过检索来增强模型在外部信息和数据获取能力
-
-
Function Calling
通过函数调用的方式使模型能够执行外部操作,例如:API、RPC调用,或访问外部服务
通过Fine-tuning特定领域微调,完成行业专有模型
-
-
关于“工具”
不用复杂编码即可实现小助手,但需要action和schema的东东,可自行查阅,不赘述
-
-
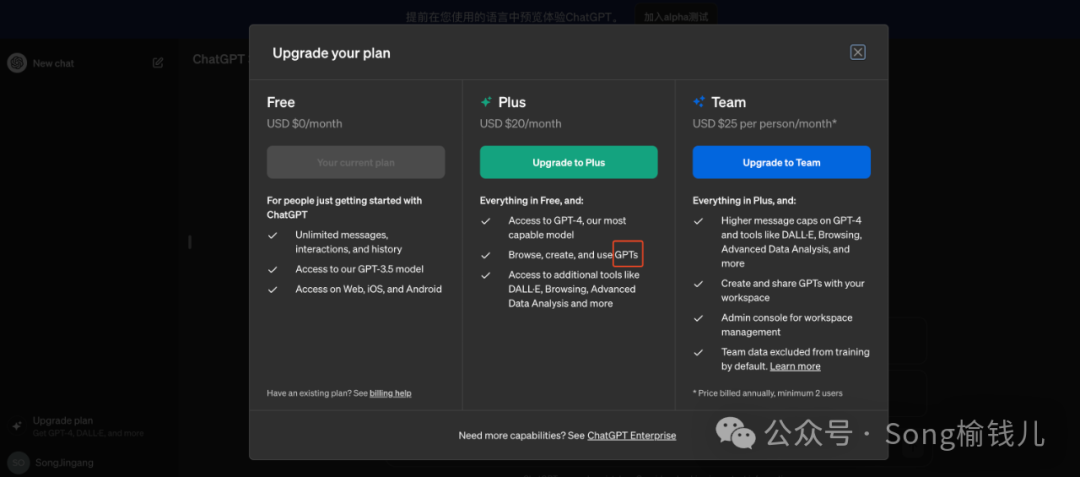
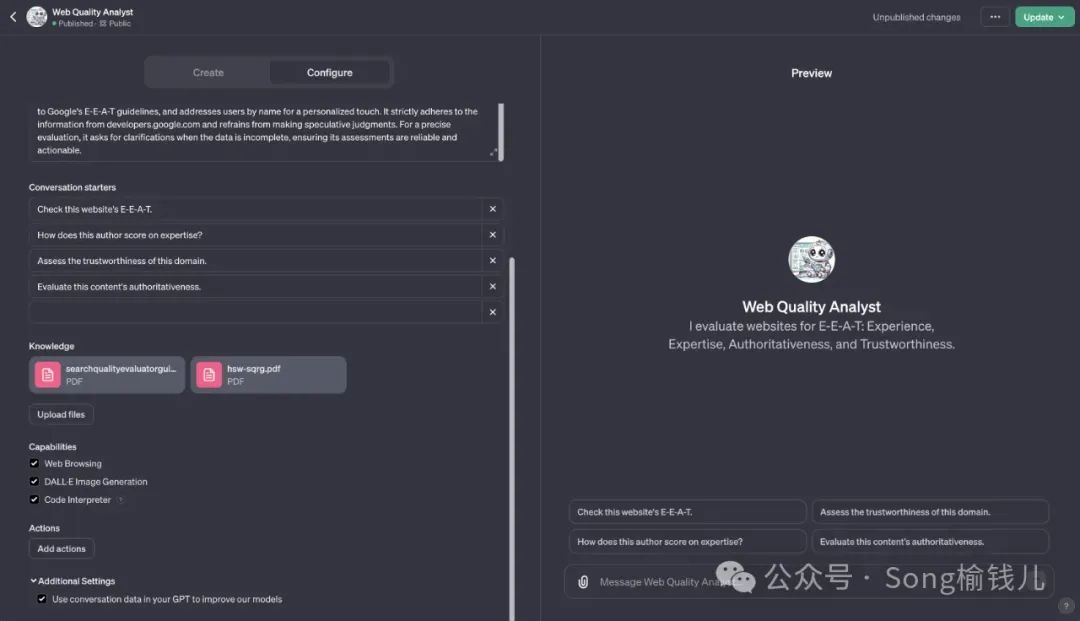
GPTs(Generative Pre-trained Transformers)
-
它是ChatGPT推出GPTs功能的简称,这是一个为初学者和开发者提供的平台,使他们能够方便地使用GPT系列模型。
通过这个平台,用户可以根据自己的需求选择合适的GPT模型,并利用它们完成各种任务。无论是文本生成、情感分析还是图像识别,GPTs都能为用户提供强大的支持。
-
-
两款平替产品(偷懒就不截图了)
-
Coze
免费使用GPT-4等OpenAI的服务
-
-
官网:https://www.coze.com/
-
-
-
Dify
开源,中国公司开发
可本地部署
https://dify.ai/
-
-
-
关于开发框架
| 开发框架 | 官网 | 作者 |
| Semantic Kernel | https://learn.microsoft.com/en-us/semantic-kernel/overview/ | 微软出品 |
| LangChain | https://www.langchain.com/ | Harrison Chase |
先介绍到这里,下一篇会介绍有趣的知识,可以关注、敬请期待


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









