






 本文详细解释了索引在数据库中的作用,特别是B+树索引的实现原理,包括B+树的结构特点和在MySQL中的应用。还讨论了何时考虑添加索引以及注意事项,强调索引并非越多越好,需要根据数据特性进行合理选择。
本文详细解释了索引在数据库中的作用,特别是B+树索引的实现原理,包括B+树的结构特点和在MySQL中的应用。还讨论了何时考虑添加索引以及注意事项,强调索引并非越多越好,需要根据数据特性进行合理选择。
一、索引是什么?
索引是一种数据结构,它为了提高数据库查询和数据访问的效率而设立。以图书馆的索引为例,它可以快速帮你找到你需要的书籍。类似地,在数据库中,索引是对数据库表中一列或多列的值进行排序的一种存储结构,它是某个表中一列或若干列值的集合和相应的指向表中物理标识这些值的数据页的逻辑指针清单。索引的实现通常使用B树和变种的B+树(例如,MySQL常用的索引就是B+树)。因此,通过利用索引,我们可以更快速地定位到目标数据,加快数据的查找和访问速度。
二、索引实现的原理
MySQL中的B+树索引实现原理基于B+树这种数据结构,它是一种高效的索引方法,主要用于存储大量数据,并且可以快速定位到所需的记录。其中,每个节点的指针上限为2d而不是2d+1,这意味着每个节点可以有更多的指针,进一步提高了查询效率。
值得一提的是,B+树与B-树的主要区别在于,B+树内部节点只作索引作用而不保存数据,只有叶子节点才保存数据信息。这一设计使得在进行范围查找时,B+树只要找到范围的最小值,然后顺着指针就可以找到所有符合条件的数据,这无疑大大提高了查询效率。
b+树又是什么?
B+树,是一种平衡的多路查找树。与平衡二叉树不同的是,平衡二叉树节点最多有两个子树,而B树每个节点可以有多个子树。
如图是一个4阶的B+树:
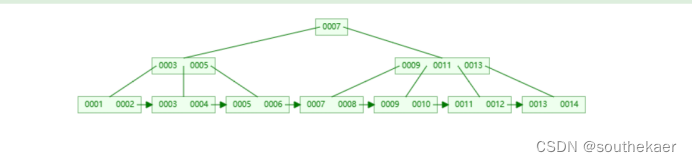
这是一个4阶的b+树,内部节点最多有4个子节点,一个节点内的数据最多有3(4-1)个,当插入数量到4个时候,就会进行分裂操作,当删除节点内的数据时,会进行合并等操作。
对m阶的B+树的主要特点包括:
- 在m阶B+树中,每个节点的子节点最多有m个,每个节点(非根内部节点)关键字个数n的范围是[⌈m/2⌉, m](根节点:[1,m]);
- B+树的根节点和枝节点中都不会存储数据,只有叶子节点才存储数据,这样可以使得每次查找的次数最小;
- B+树的每个叶子节点增加了一个指向相邻叶子节点的指针,它的最后一个数据会指向下一个叶子节点的第一个数据,而下一个节点里面的结构里面又定义了一个指针指向前一个数据的节点,从而形成了一个有序的双向链表的结构;
- 所有的数据均存在于叶子节点,而且数据是按照顺序方式存储。
插入构建一颗4阶的B+树:
开始插入1,直接作为根节点

插入2,与1比较,比1大,放右边

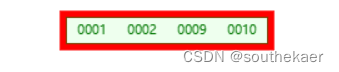
继续插入10,放2后面

插入9,这时,4阶的B+树最多存放3个数据,需要开始分裂操作
分裂操作首先选取一个中间值,这里选9,然后将9放到父节点中,因为这里还没有父节点,那么直接创建一个新的父节点存放9,而原来小于9的那些项作为左子树,原来大于等于9的那些项作为右子树。这里注意下非叶子节点存放的都是关键字,用作索引的,所以父节点存放的9不包括数据,数据仍然存放在右子树叶子节点中。此外,还需要添加指针,使得左子树与右子树相连。
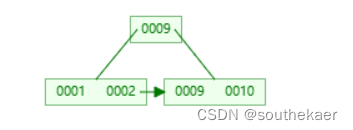
继续插入8,8比9小,放左子树中
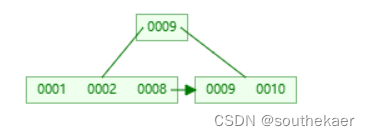
插入7,7比9小,放左子树,此时左子树又是需要进行分裂操作
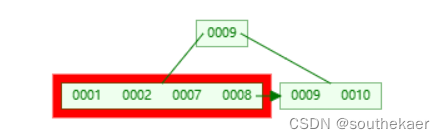
分裂操作,选取待分裂节点中间位置的项7,然后将7放到父节点中,按大小顺序将7放到指定位置,而原来小于7的那些项作为左子树,原来大于等于7的那些项作为右子树,这其中大于7小于9的树放在中间的叶子节点中。父节点存放的7不包括数据,数据仍然存放在中间的叶子节点中。此外,还需要添加指针,使得左右相邻的子树相连。
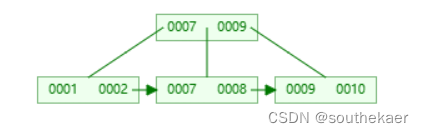
插入5,5比7小,放入左子树中
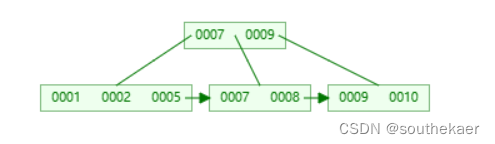
插入6,这时,叶子节点又需要进行分裂
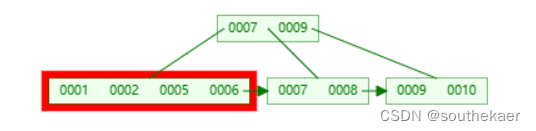
与上面相同,选择中间的5放入父节点中并分裂,而此课b+树的路数已经达到的4,也就是根节点的子节点数以及达到4个
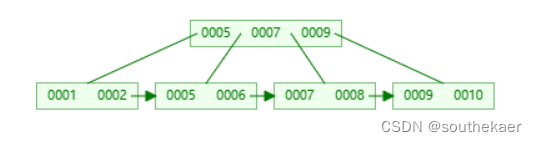
插入3
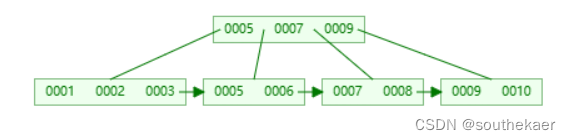
插入4,此时又需要分裂,与之前的分裂方式相同
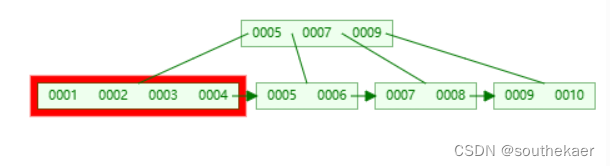
分裂完成后,发现把3加入父节点中,使得父节点有需要分裂
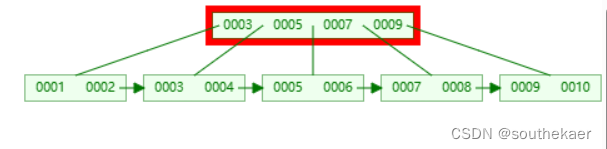
这时,同样是选择一个中间数7当作新的父节点,而小于7的分为左子树,大于7的分为右子树,值得注意的是,与之前不同,分裂的这个节点是非叶子节点,而7的数据保存在叶子节点中,而分裂出来的右子树也是非叶子节点不保存7的数据,所以右子树不需要添加7
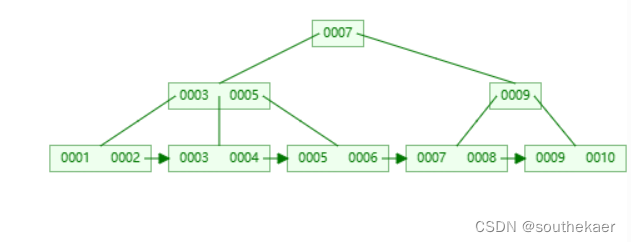
这时候,一颗B+树的插入与创建就完成了
B+树的搜索查找操作:
例如,如果在一个电商网站中需要查询价格在100到200元之间的所有商品,使用B+树索引,只需要找到价格为100元的商品,然后顺着指针就可以找到所有符合条件的商品,而无需逐行扫描数据。
select * from t1 where price>100 and price<200;
举个栗子:
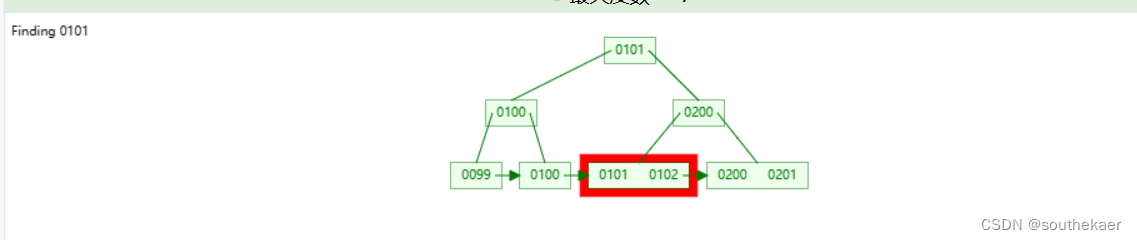
通过索引找到叶子节点100后,叶子节点是通过双向链表(C++具体实现)连在一起,只需向下比较,就能查找到100至200之间的范围值
而叶子节点中的节点数据则包含表中数据的物理地址:
这是这张表中数据在磁盘中的存储位置
Price(PK) name 每一行记录在硬盘上都有物理存储编号
----------------------------------------------------------------------------------
100 book 0x00001000
101 pen 0x00002000
99 desk 0x00003000
200 box 0x00004000
在数据库当中,任何一张表的任何一条记录在实际硬盘存储上都有一个硬盘的物理存储编号,
数据存在block数据块中,数据块也就是磁盘上面的块,我们常说的表空间就是由很多个block数据块组成。
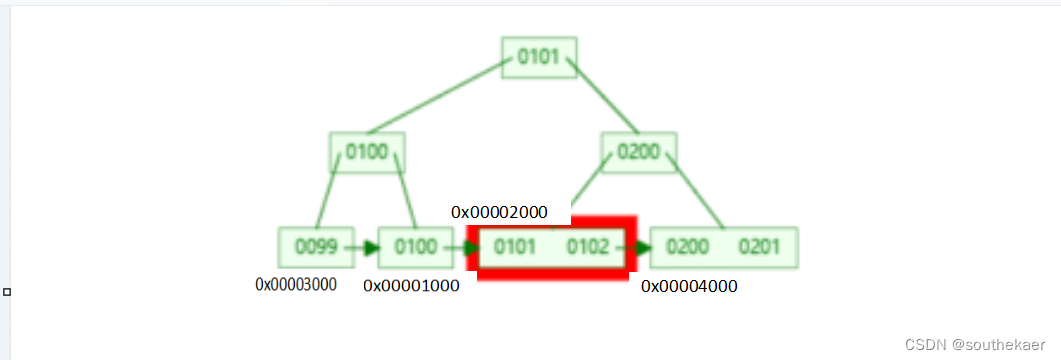
输入的sql语句是:select * from t1 where price = 101;
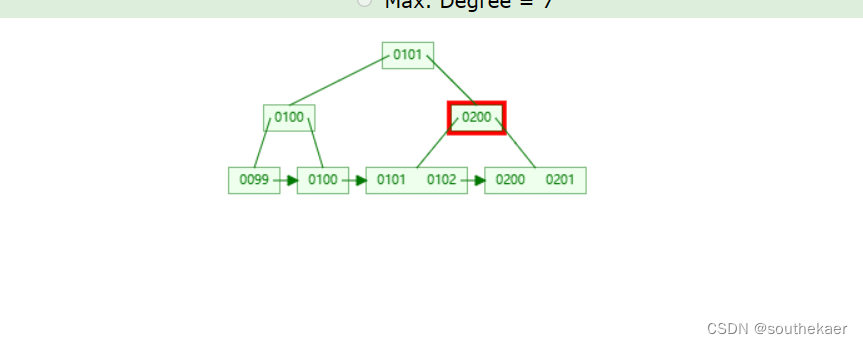
条件是price = 101,数据库底层发现price 字段上有索引对象,所以会通过索引对象进行查找:
101比100大,看右边
101比200小,看左边
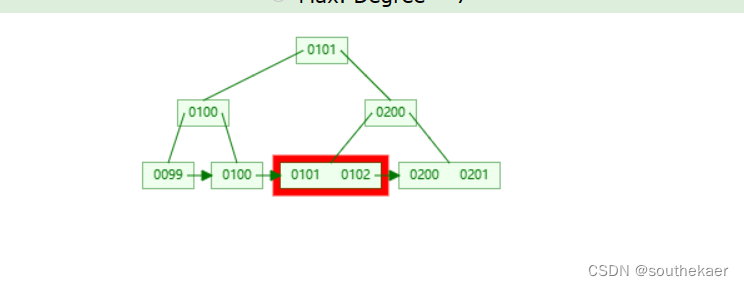
定位到101,通过定位到的101得出对应的物理地址0x00002000,就会转换sql语句成:
select * from t1 where 物理地址 = 0x00002000;
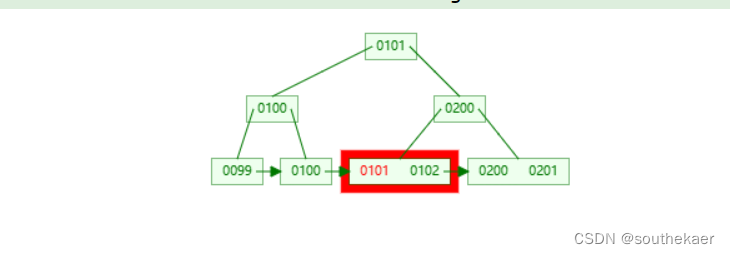
直接通过物理地址0x00002000定位到存储的记录
101 pen 0x00002000
由此,服务端查询完成,返回给客户端。
以下就是一个查询的过程
什么时候考虑添加索引?
在数据库中,我们主要在以下情况下考虑添加索引:
-
在经常需要搜索查询的列上创建索引,这可以加快搜索的速度。例如,如果某个表中经常需要根据用户ID来查找用户的详细信息,select * from t1 where id ****;那么在这个列上创建索引将会大大提高查询效率。
-
在作为主键的列上创建索引,这可以强制该列的唯一性并组织表中数据的排列结构。主键是唯一标识一条记录的字段,所以在这个字段上创建索引非常有意义。
-
在经常用于连接操作的列上创建索引,这些列主要是一些外键,可以加快连接的速度。例如,如果有多个表需要进行连接查询,那么在这些列上创建索引将有助于提高查询性能。
-
当单个索引字段查询数据很多,区分度都不是很大时,则需要考虑建立联合索引来提高查询效率。
在使用索引时,需要注意以下几点:
-
索引并不是越多越好,因为索引会占用磁盘空间,并且在插入和更新数据时会降低性能。因此,我们需要根据实际情况来决定是否添加索引。
-
如果某个列的数据重复率很高,那么在该列上创建索引可能不会带来明显的性能提升。这是因为在搜索时,可能需要扫描大量的重复值,比如一张人口信息表,就不需要在性别那一列上面添加索引。
-
如果某个列的数据频繁变化,经常updata,insert,delete,那么在该列上创建索引可能会影响性能。这是因为每次数据变化时,都需要更新索引,对数据进行重新排序。















 1776
1776











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









