







awk就是把需要处理的文本逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行各种分析处理
#man awk 执行结果
在这里可能很奇怪为什么是gawk而不是awk,其实gawk程序是Unix中原awk程序的GNU版本。现在我们平常使用的awk其实就是gawk,可以看一下awk命令存放位置,awk建立一个软连接指向gawk,所以在系统中使用awk或是gawk都一样的

awk [ -F re] [parameter…] [‘prog’] [-f progfile][in_file…]
参数说明:
-F re:允许awk更改其字段分隔符。
parameter: 该参数帮助为不同的变量赋值。
‘prog’: awk的程序语句段。这个语句段必须用单拓号:’和’括起,以防被shell解释。这个程序语句段的标准形式为: ‘pattern {action}’ 。其中pattern参数可以是egrep正则表达式中的任何一个,它可以使用语法/re/再加上一些样式匹配技巧构成。与sed类似,你也可以使用”,”分开两样式以选择某个范围。关于匹配的细节,你可以参考附录,如果仍不懂的话,找本UNIX书学学grep和sed(本人是在学习ed时掌握匹配技术的)。action参数总是被大括号包围,它由一系统awk语句组成,各语句之间用”;”分隔。awk解释它们,并在pattern给定的样式匹配的记录上执行其操作。与shell类似,你也可以使用“#”作为注释符,它使“#”到行尾的内容成为注释,在解释执行时,它们将被忽略。你可以省略pattern和action之一,但不能两者同时省略,当省略pattern时没有样式匹配,表示对所有行(记录)均执行操作,省略action时执行缺省的操作――在标准输出上显示。
-f progfile:允许awk调用并执行progfile指定有程序文件。progfile是一个文本文件,他必须符合awk的语法。
in_file:awk的输入文件,awk允许对多个输入文件进行处理。值得注意的是awk不修改输入文件。如果未指定输入文件,awk将接受标准输入,并将结果显示在标准输出上。awk支持输入输出重定向。
-F fs 指定描绘一行中数据字段的文件分隔符
-f filename 指定读取程序的文件名
-v var=value 定义gawk程序中使用的变量和默认值
-mf N 指定数据文件中要处理的字段的最大数目
-mr N 指定数据文件中的最大记录大小
$0表示整行文本
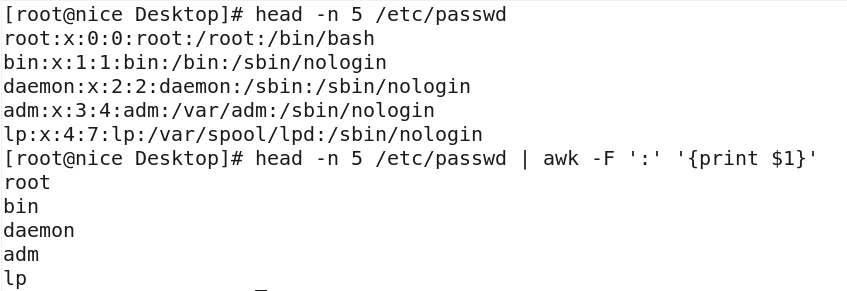
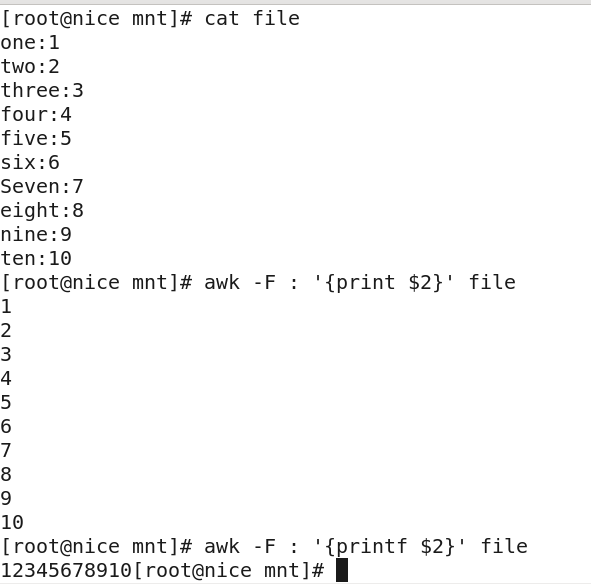
$1表示文本行中的第一个数据字
$2表示文本行中的第二个数据字段
\ $n表示文本行中的第n个数据字段
在 ’ ‘中除了{ },还有BEGIN和END

awk工作流程是这样的:先执行BEGING,然后读取文件,按行逐一执行action,最后执行END操作。
pattern则是匹配条件
格式为 awk ‘/string/’ file

pattern+action的例子如下

在之前例子中{}中都有个print,这里可以使用print也可以使用printf,而printf与C语言中的printf实现几乎是一样的
特殊符号的输出
双引号
awk ‘{print ” \ ” “}’
单引号
awk ‘{print ” ’ \ ’ ’ “}’

在awk中有内置变量
ARGC 命令行参数个数
ARGV 命令行参数排列
ENVIRON 支持队列中系统环境变量的使用
FILENAME awk浏览的文件名
FNR 浏览文件的记录数
FS 设置输入域分隔符,等价于命令行 -F选项
NF 浏览记录的域的个数
NR 已读的记录数
OFS 输出域分隔符
ORS 输出记录分隔符
RS 控制记录分隔符>>>>输出file文件的2到7行内容
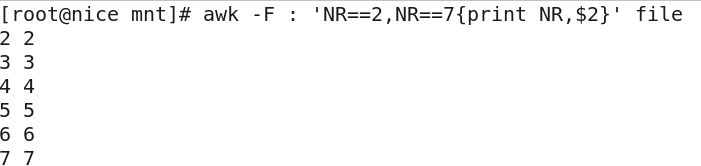
除了有内置变量,还有内置函数,比如说length(),计算字符个数。
>>>求出file文件的字符个数

另外awk中支持if,for,while等语言中的语句
>>>>找出file文件中第一列字符长度小于等于3的行并且只输出其第二列
>>>>找出file文件中从第二行到地起航之间,第一列字符长度小于等于3的行并且只输出其第二列


















 589
589

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









