






 本文探讨了如何利用大数据和知识图谱技术提升酒店推荐系统的准确性、个性化和效率,提出一种基于Spark的处理框架和知识图谱的融合方案,以解决传统推荐方法的局限。研究还涉及数据采集、用户画像构建、个性化算法和大数据可视化等方面。
本文探讨了如何利用大数据和知识图谱技术提升酒店推荐系统的准确性、个性化和效率,提出一种基于Spark的处理框架和知识图谱的融合方案,以解决传统推荐方法的局限。研究还涉及数据采集、用户画像构建、个性化算法和大数据可视化等方面。
云南经济管理学院2024届本科毕业论文(设计)开题报告(理科类)
学院:信息与智能工程 专业:大数据管理与应用
| 论文(设计)题目 | 基于大数据的酒店推荐系统 | |||||
| 学生姓名 | 班级 | 学号 |
| |||
| 指导教师 |
| 职称 |
| 学历学位 |
| |
| 研究目的(选题的意义和预期应用价值) 意义 随着旅游业的快速发展,酒店行业的竞争越来越激烈。在如此激烈的市场竞争中,如何提供个性化、精准的酒店推荐服务成为了一个重要的问题。知识图谱是一种以图形化的方式呈现出来的知识库,它能够将不同来源、不同类型的数据融合在一起,并通过自然语言处理、机器学习等技术进行处理,从而提供更加精准、个性化的推荐服务。基于Spark的分布式计算和处理能力,可以处理大规模的数据,提高系统的运行效率,使得推荐系统能够在短时间内给出准确的推荐结果。总之,如下:
预期应用价值
| ||||||
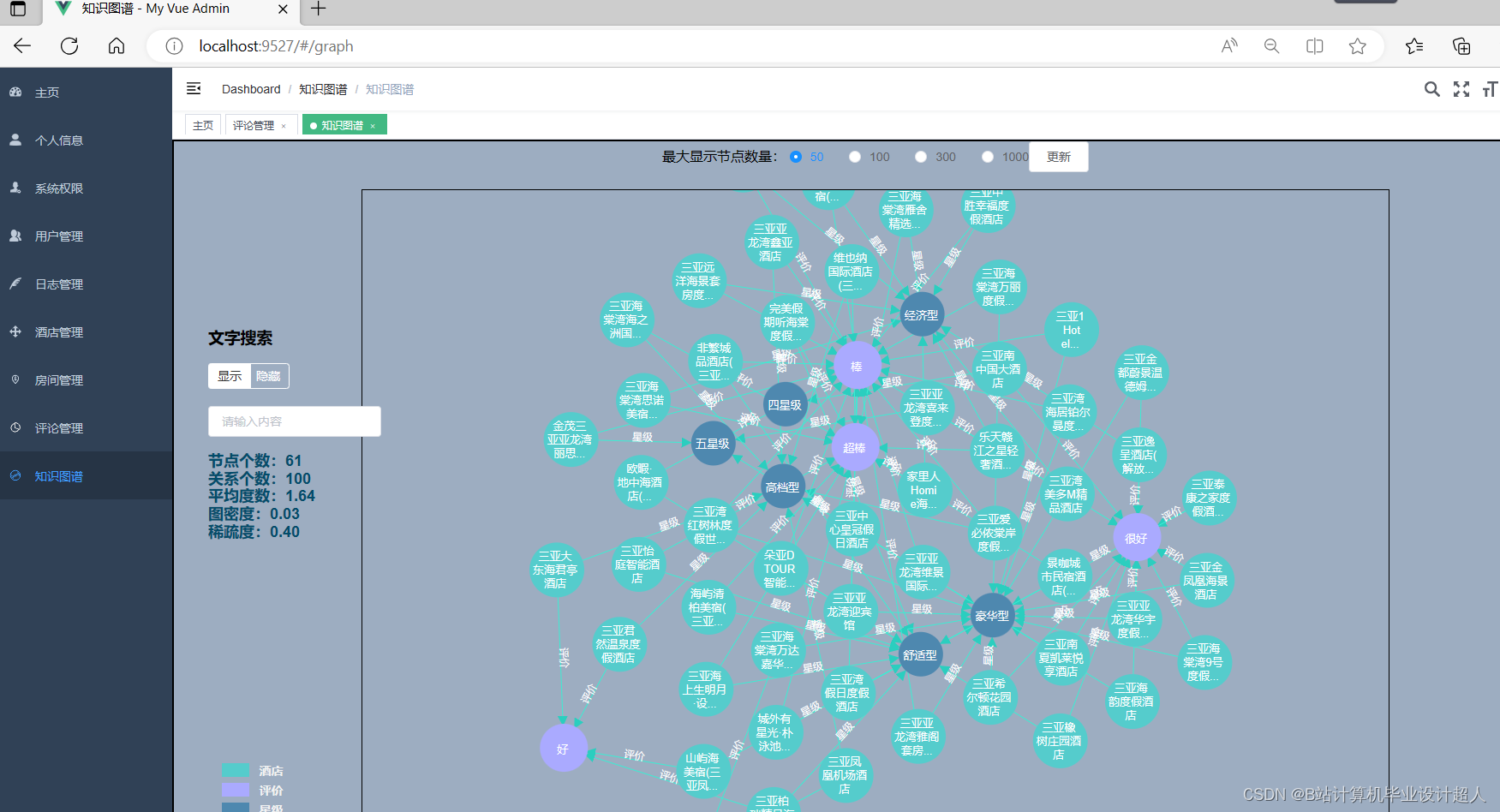
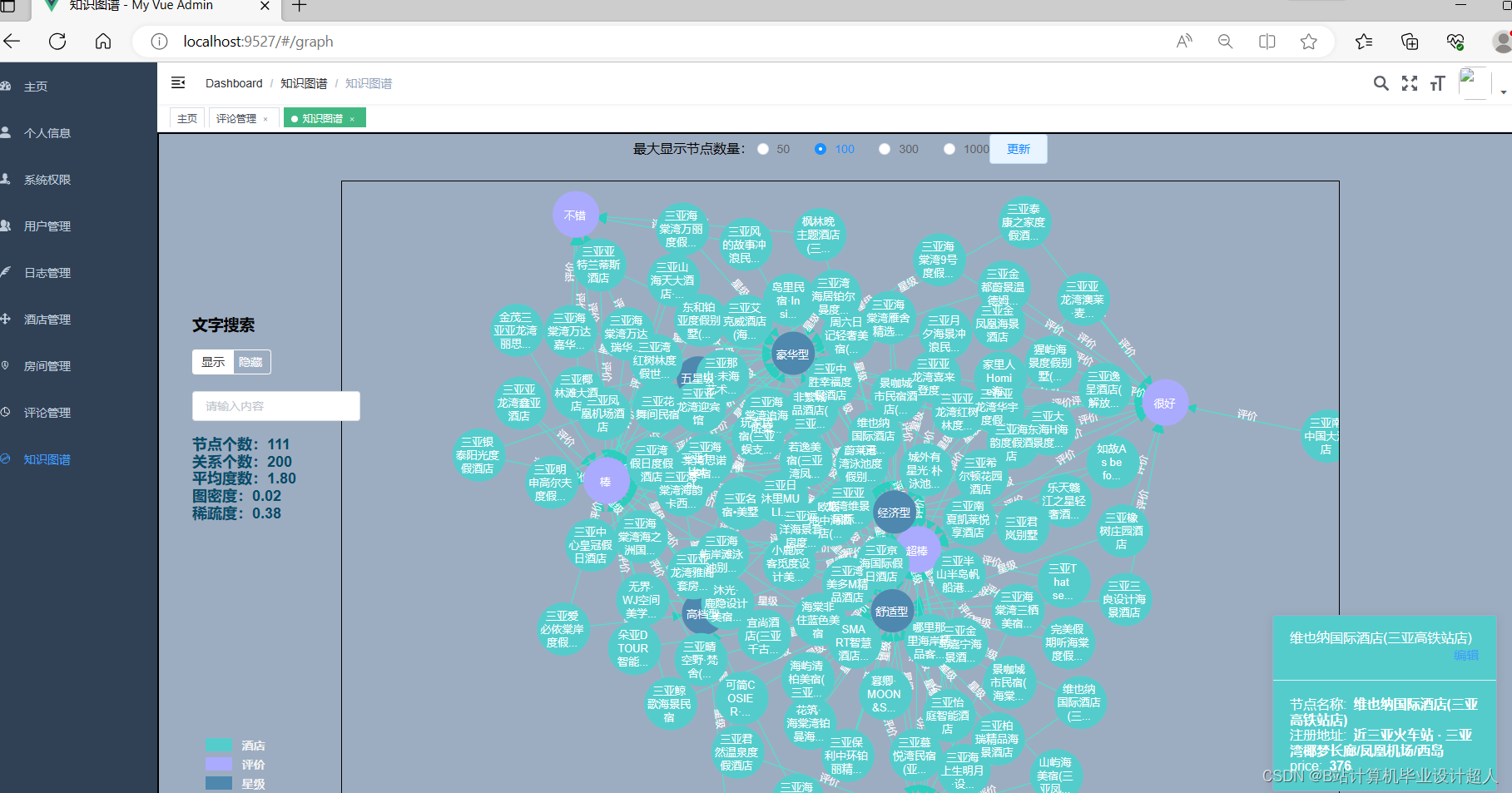
| 与本课题相关的国内外研究现状(文献综述),预计可能创新的方面 国内外研究现状(文献综述) 研究现状 酒店推荐系统是一种基于用户偏好和需求的语言学习系统,能够为用户提供个性化的酒店推荐服务。近年来,研究者们在酒店推荐系统方面进行了广泛的研究。其中,基于协同过滤的方法和基于内容的方法是最为常见的。 基于协同过滤的方法主要是通过分析用户的历史行为和其他用户的行为,找出与目标用户兴趣相似的其他用户,然后根据这些相似用户的行为推荐酒店。基于内容的方法则是根据用户对酒店的评价和描述,提取出其中的关键词和语义信息,构建一个酒店的内容向量,然后计算目标用户与这些内容向量的相似度,推荐相似度最高的酒店。 然而,传统的推荐方法存在一些不足之处。例如,它们往往只考虑用户历史行为或物品属性,忽略了语义信息。此外,传统的推荐方法难以处理大规模数据,无法实时更新推荐结果。 挑战与不足 酒店推荐系统面临的挑战主要包括如何提高推荐的准确性和个性化程度,如何处理大规模数据,如何提高系统的实时性等。然而,现有的推荐方法在处理这些挑战时存在一些不足。 首先,传统的推荐方法无法有效利用语义信息。现有的推荐方法往往只考虑用户历史行为和酒店属性等较为结构化的数据,忽略了大量的文本评论和描述等语义信息。这些信息对于理解用户需求和酒店特点至关重要。 其次,现有的推荐方法难以处理大规模数据。随着数据的不断增长,传统的推荐方法往往会出现计算速度慢、内存消耗大等问题。此外,传统的推荐方法通常是离线运行的,无法实时更新推荐结果。这使得它们无法及时响应用户需求的变化和酒店信息的更新。 最后,现有推荐方法的个性化程度有限。虽然许多推荐方法声称能够根据用户的偏好和需求提供个性化的服务,但在实际应用中,它们的个性化程度仍显不足。这主要是因为这些方法往往只考虑了用户的历史行为和酒店属性等较为简单的信息,忽略了用户的兴趣爱好、行为习惯等更为深入的信息。 为了解决这些不足,本文提出了一种基于Spark和知识图谱的酒店推荐系统。该系统能够有效利用语义信息、处理大规模数据、提高系统的实时性,并为用户提供更加个性化的服务。 Spark和知识图谱的应用 Spark是一个大规模数据处理框架,具有高效的分布式计算能力,可以处理大规模的数据集。Spark的分布式计算能力可以大大提高酒店推荐系统的处理速度和效率,使其能够处理更多的数据和实现实时的推荐。 知识图谱是一种语义网络技术,能够将各种实体、概念及其之间的关系以图形化的方式呈现出来。在酒店推荐系统中,知识图谱可以用于提取和整合各种酒店和用户信息,提供更加精准的推荐。例如,通过分析酒店的知识图谱,可以获取酒店的类型、设施、价格等信息,从而更加准确地理解用户的需求;通过分析用户的知识图谱,可以了解用户的喜好、行为习惯等信息,从而提供更加个性化的服务。 未来研究方向 尽管本文提出的基于Spark和知识图谱的酒店推荐系统具有一定的创新性和实用性,但仍存在一些不足之处和需要进一步探讨的问题。例如,如何构建更加精准的用户画像、如何更加有效地提取和整合语义信息、如何提高系统的实时性等,将是未来研究的重要方向。 预计可能创新的方面
| ||||||
| 研究的主要内容与可行性分析 主要内容
可行性分析 一、技术可行性 基大数据的酒店推荐系统采用了先进的大数据处理技术和自然语言处理技术,可以高效地处理大规模的数据,并能够从文本中提取出丰富的语义信息。 大数据处理技术 Spark是一个大规模数据处理框架,具有高效的分布式计算能力,可以处理大规模的数据集。使用Spark可以大大提高酒店推荐系统的处理速度和效率,使其能够处理更多的数据和实现实时的推荐。 自然语言处理技术 知识图谱是一种语义网络技术,能够将各种实体、概念及其之间的关系以图形化的方式呈现出来。在酒店推荐系统中,知识图谱可以用于提取和整合各种酒店和用户信息,提供更加精准的推荐。例如,通过分析酒店的知识图谱,可以获取酒店的类型、设施、价格等信息,从而更加准确地理解用户的需求;通过分析用户的知识图谱,可以了解用户的喜好、行为习惯等信息,从而提供更加个性化的服务。 二、经济可行性 基大数据的酒店推荐系统采用了先进的大数据处理技术和自然语言处理技术,可以高效地处理大规模的数据,并能够从文本中提取出丰富的语义信息。相比传统的推荐系统,该系统可以减少人工参与和提高效率,从而降低成本。此外,该系统的实施可以帮助酒店提高用户满意度和提升竞争力,从而带来经济效益。 三、政治可行性 基大数据的酒店推荐系统采用了先进的大数据处理技术和自然语言处理技术,可以高效地处理大规模的数据,并能够从文本中提取出丰富的语义信息。推荐系统在政治方面有着重要的应用价值。通过基于用户行为等数据对用户进行推荐,可以有效地引导用户的消费行为和意识形态。这种推荐方式有可能被一些不法分子所利用,从而对国家政治稳定产生负面影响。因此,在设计和实现基大数据的酒店推荐系统的过程中,需要采取一些措施来确保系统的安全性。例如,可以采用数据加密、权限控制等措施来保护用户隐私和系统安全。此外,对于敏感信息的处理,必须严格遵守国家的法律法规和相关政策,以确保该系统的政治可行性。 四、社会可行性 基大数据的酒店推荐系统采用了先进的大数据处理技术和自然语言处理技术,可以高效地处理大规模的数据,并能够从文本中提取出丰富的语义信息。随着旅游业和酒店业的快速发展,用户对酒店推荐服务的需求越来越高。传统的推荐方法已经无法满足用户的需求。基大数据的酒店推荐系统可以根据用户的兴趣爱好、行为习惯等信息进行个性化推荐,从而提升用户体验和服务质量。此外,该系统的实施可以帮助酒店提高用户满意度和提升竞争力,促进旅游业和酒店业的发展。因此,基大数据的酒店推荐系统具有广泛的社会应用价值和社会效益,是可行的。 总之,基大数据的酒店推荐系统具有广泛的应用前景和实用性。采用先进的大数据处理技术和自然语言处理技术使得该系统在技术上可行;能够减少人工参与和提高效率使得该系统在经济上可行;同时政治可行性和社会可行性也得到了充分保障。因此,设计和实现基大数据的酒店推荐系统是可行的,具有重要的理论意义和实践价值。 | ||||||
| 本课题研究的主要方法和步骤
| ||||||
| 研究进度安排 第1-3周熟悉题目,对的开发流程和使用进行熟悉和分析,完成开题报告、文献综述以及需求分析。 第4-5周完成总体设计,根据系统需要建立数据库。 第6-9周初步完成系统详细设计,实现基本功能。 第10-12周对系统进行细节完善。 第13-16周根据系统设计过程中的记录文挡及其功能编写毕业论文。 | ||||||
| 指导教师意见 指导教师签字: 年 月 日 | ||||||
| 学院本科毕业论文(设计)工作领导小组意见 组长签字: 年 月 日 | ||||||
注:可附页。





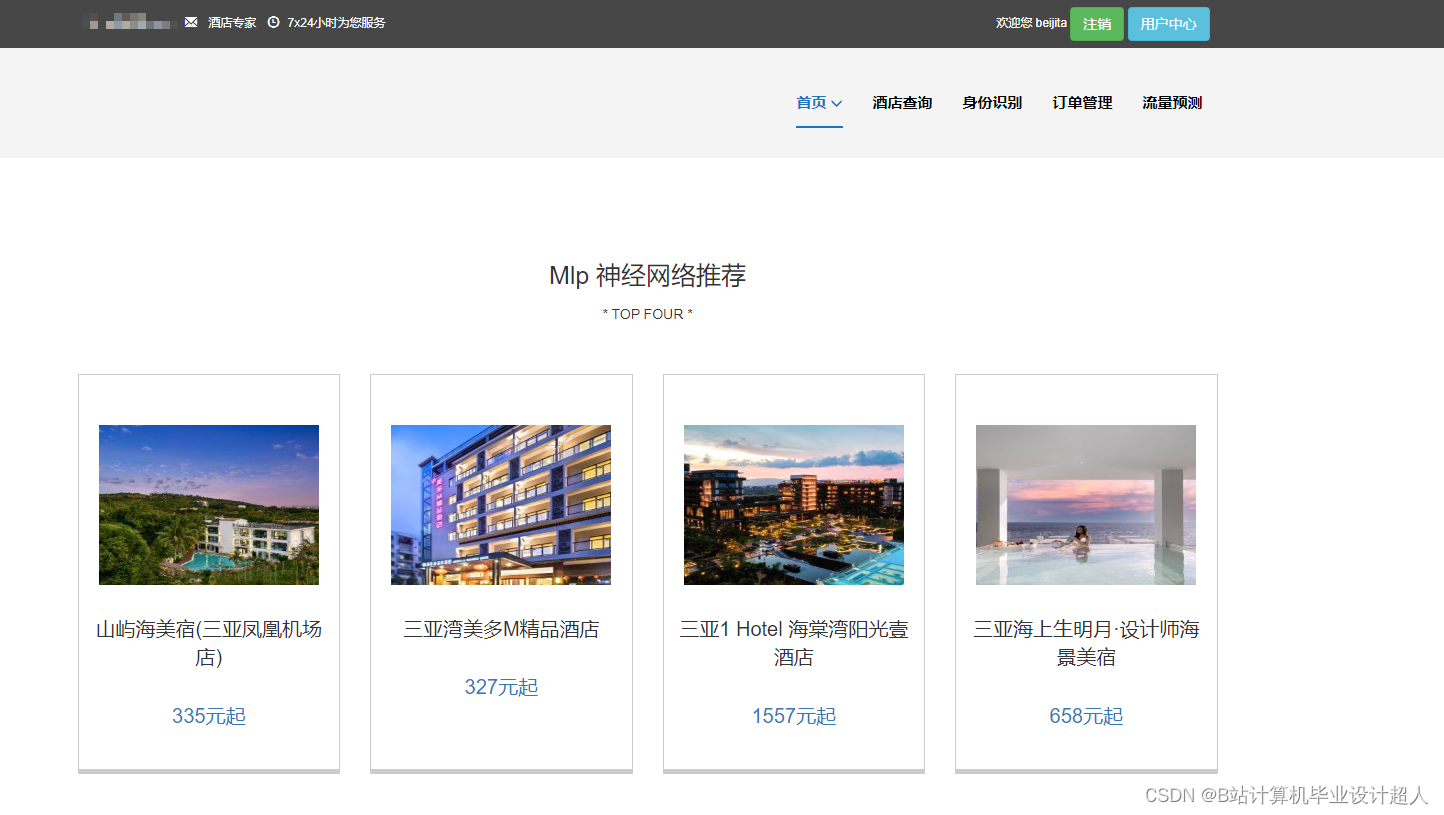
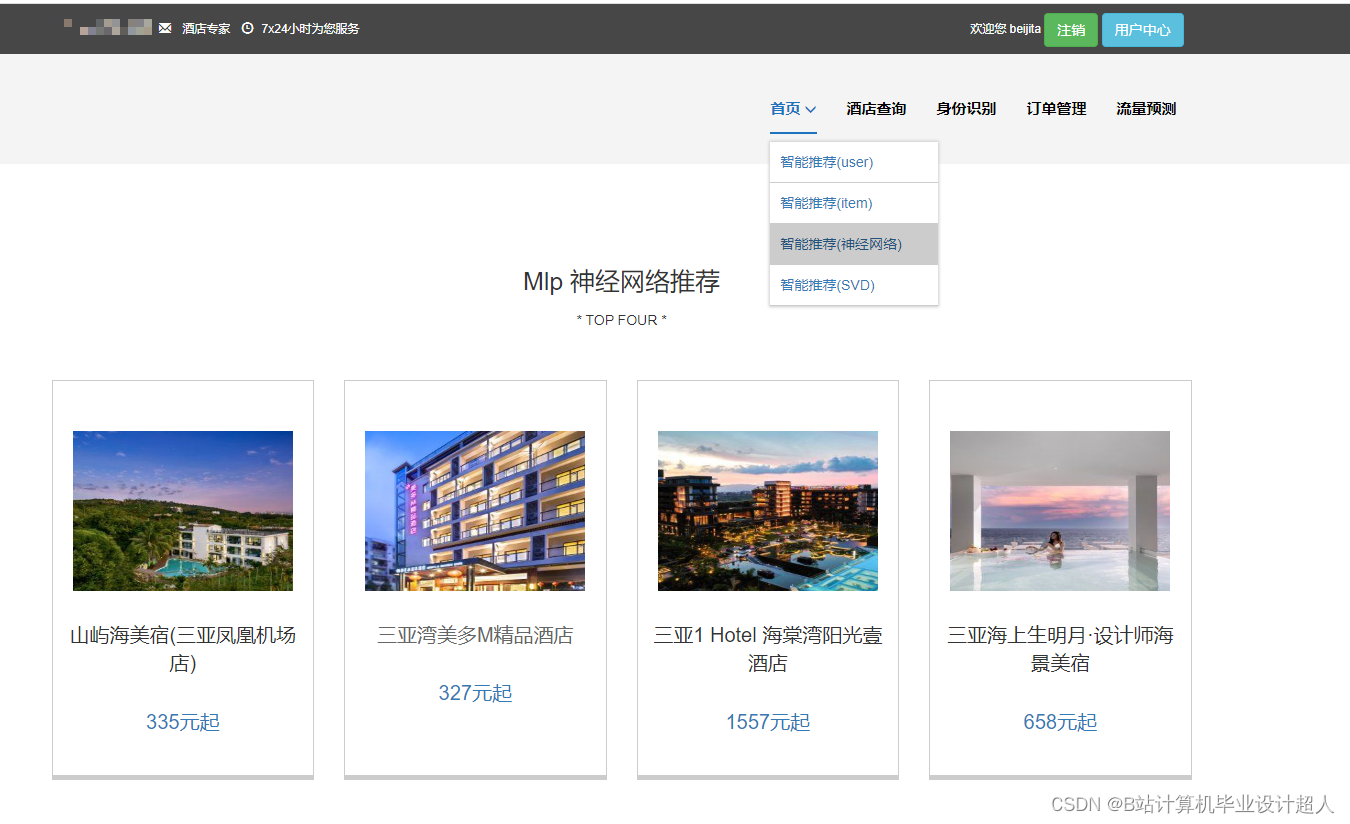
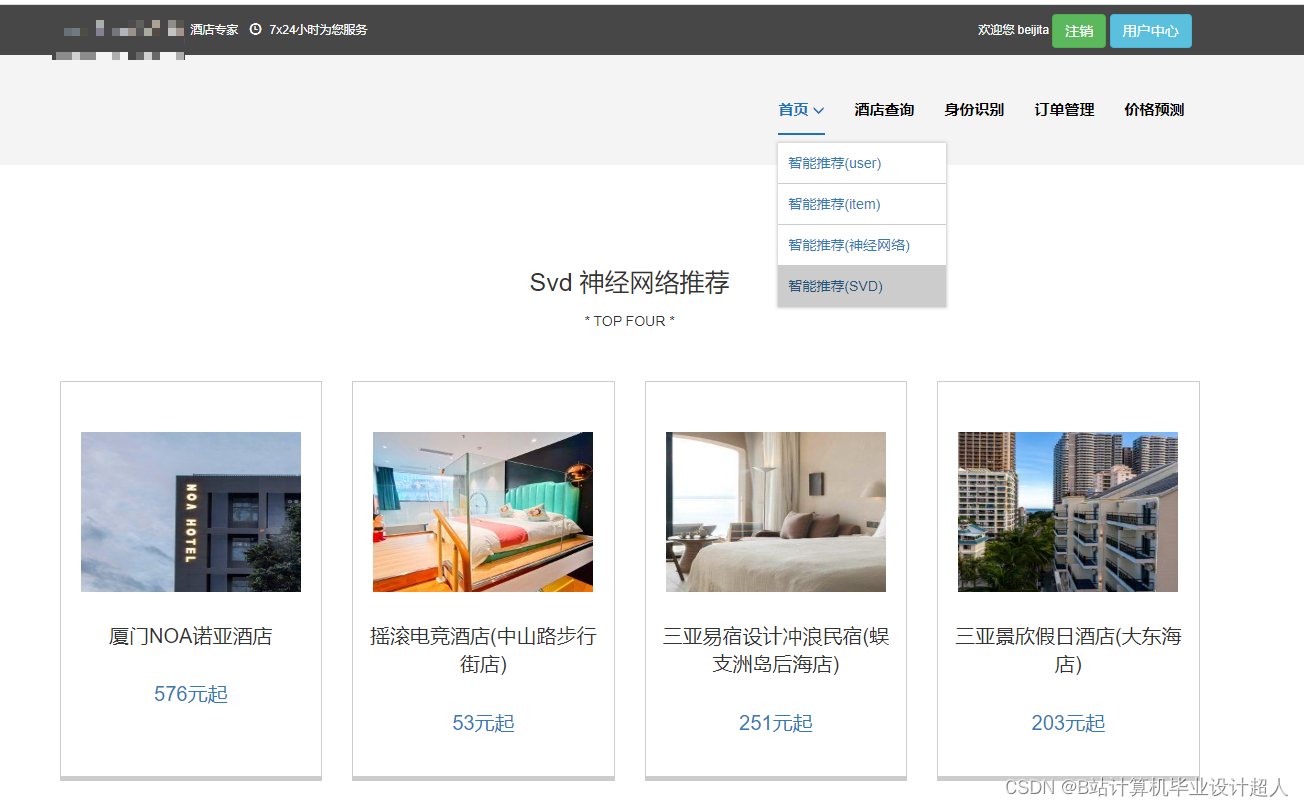
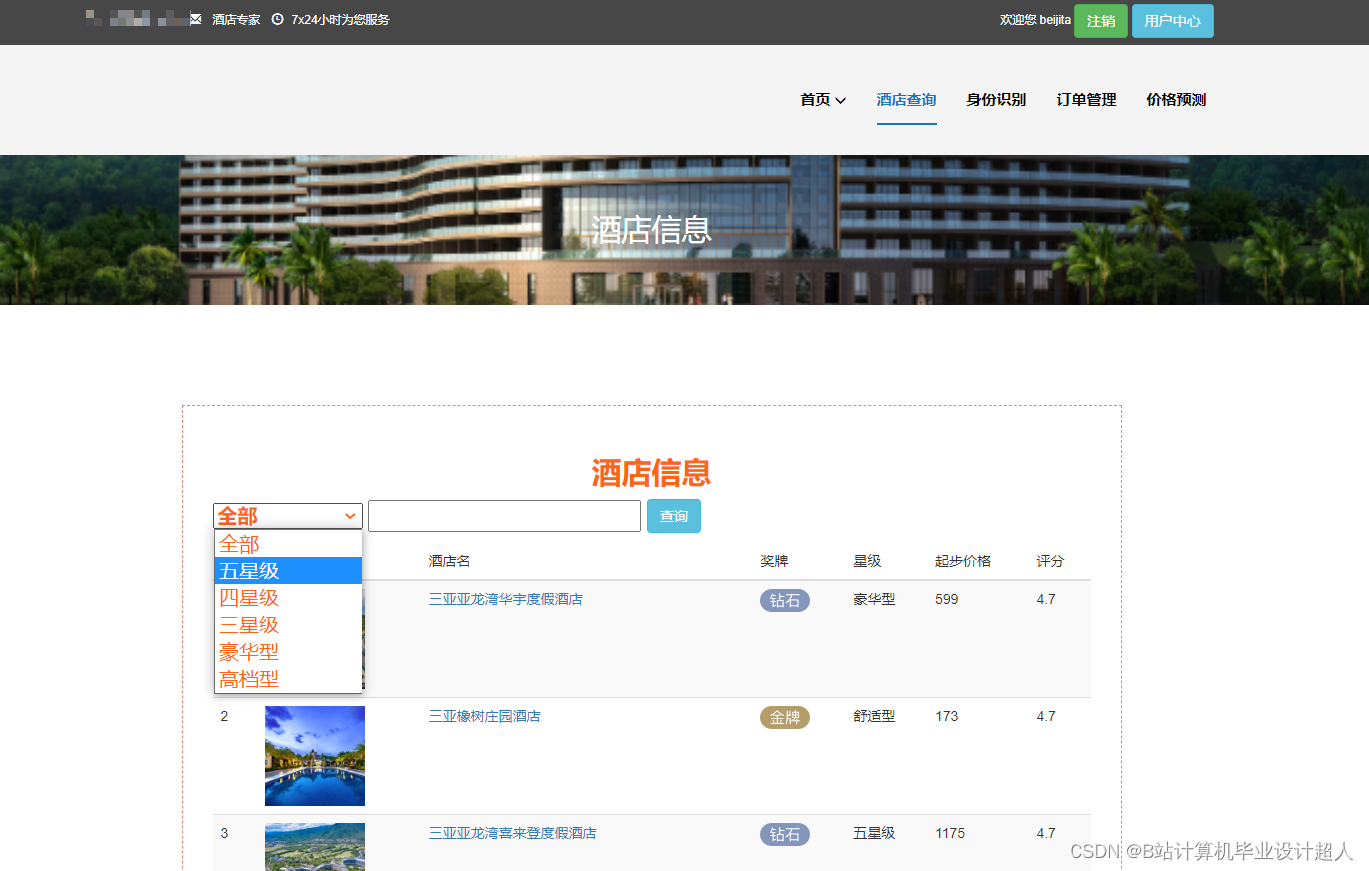
核心算法代码分享如下:
## 启动hadoop
cd /data/hadoop/sbin
sh /data/hadoop/sbin/start-all.sh
## 启动hive
cd /data/hive
nohup hive --service metastore &
nohup hive --service hiveserver2 &
============hive+hadoop离线计算命令无脑复制
mysql数据库命名:hive_hotel
--hive 建库
DROP DATABASE IF EXISTS hive_hotel;
CREATE DATABASE IF NOT EXISTS hive_hotel;
use hive_hotel;
show tables;
--hdfs创建文件夹、上传CSV(linux上上传CSV到/data/hotel2024然后再执行以下命令 -f表示覆盖)
mkdir -p /data/hotel2024
hadoop dfs -mkdir -p /hotel2024/hotels
hadoop dfs -mkdir -p /hotel2024/rooms
hadoop dfs -put -f /data/hotel2024/hotels.csv /hotel2024/hotels
hadoop dfs -put -f /data/hotel2024/rooms.csv /hotel2024/rooms
--hive建表 酒店表 ods_hotels
--参考字段
--code,title,xinji,score,score_desc,comment,price,address,gaode_province,gaode_city,gaode_district
--参考数据
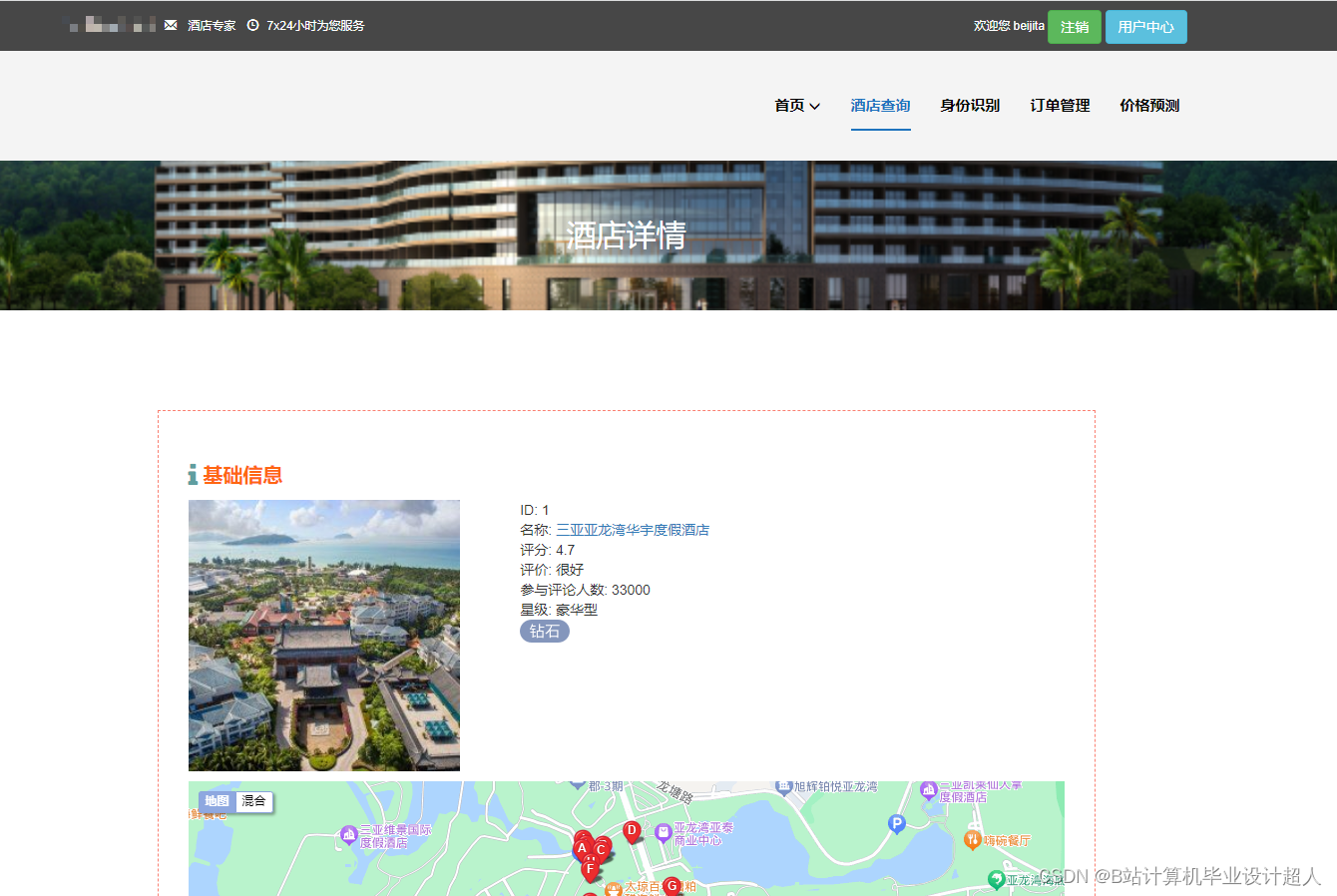
/cn/sanya/dt-1996/,code
三亚亚龙湾华宇度假酒店,title
豪华型,xinji
4.7,score
很好,score_desc
33000,comment
599.0,price
近亚龙湾 · 亚龙湾/热带天堂森林公园/博后村,address
海南省,gaode_province
三亚市,gaode_city
吉阳区,gaode_district
drop table if exists ods_hotels;
create external table ods_hotels(
`code` string COMMENT '酒店去哪儿网ID',
`title` string COMMENT '酒店名字',
`xinji` string COMMENT '星级',
`score` double COMMENT '评分',
`score_desc` string COMMENT '评分描述',
`comment` int COMMENT '评论量',
`price` int COMMENT '价格',
`address` string COMMENT '地址',
`gaode_province` string COMMENT '高德解析——省份',
`gaode_city` string COMMENT '高德解析——城市',
`gaode_district` string COMMENT '高德解析——区域'
)
row format delimited fields terminated by ','
location '/hotel2024/hotels';
select * from ods_hotels limit 1;
select count(1) from ods_hotels ;


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











