







 本文探讨了在互联网信息爆炸的背景下,如何利用Hadoop技术开发知网文献推荐系统,通过数据采集、预处理、分布式存储和推荐算法,以提高用户检索效率和满意度。研究内容涉及系统架构、推荐算法设计以及实验预期和时间安排。
本文探讨了在互联网信息爆炸的背景下,如何利用Hadoop技术开发知网文献推荐系统,通过数据采集、预处理、分布式存储和推荐算法,以提高用户检索效率和满意度。研究内容涉及系统架构、推荐算法设计以及实验预期和时间安排。
1. 研究背景与意义
随着互联网的快速发展和信息爆炸式增长,人们面临着海量的信息资源,尤其是学术文献。在这种情况下,如何高效地获取并推荐相关的学术文献对于研究者和学术工作者来说变得至关重要。知网(CNKI)作为中国领先的学术资源平台,拥有丰富的学术文献资源,但是对于用户来说,如何从这些文献中找到自己感兴趣的内容仍然是一个挑战。
基于此,我们计划开发一款基于Hadoop的知网文献推荐系统,旨在通过大数据技术和推荐算法,为用户提供个性化、精准的文献推荐服务,提高用户检索效率和满意度。
2. 研究内容与方法
本研究将主要围绕以下几个方面展开:
-
数据采集与预处理:利用爬虫技术获取知网平台的学术文献数据,并进行清洗、去重、格式化等预处理工作,以保证数据质量和一致性。
-
分布式存储与处理:采用Hadoop生态系统中的HDFS(Hadoop分布式文件系统)作为文献数据的存储平台,利用MapReduce编程模型进行数据的分布式处理和计算。
-
推荐算法设计与实现:结合用户的个人偏好、历史行为等信息,设计并实现一种有效的推荐算法,如基于内容的推荐、协同过滤推荐等,以提高推荐的准确性和覆盖率。
-
系统架构与界面设计:设计系统的整体架构,并开发用户友好的界面,实现用户注册、登录、文献检索、推荐展示等功能,提升用户体验。
3. 预期目标与成果
本研究的主要预期目标与成果包括:
- 实现一款基于Hadoop的知网文献推荐系统原型,具备数据采集、存储、处理、推荐等核心功能。
- 提高用户文献检索的准确性和效率,增强用户体验。
- 通过实验评估,验证推荐系统的性能和有效性,探索其在实际应用中的潜力和优势。
4. 研究计划与安排
本研究将按照以下计划与安排进行:
- 第一阶段(1-2个月):调研相关领域的文献和技术,确定系统需求和技术方案。
- 第二阶段(3-4个月):开发系统的核心模块,包括数据采集、存储、处理、推荐等功能。
- 第三阶段(5-6个月):进行系统测试与优化,完善用户界面,准备论文写作和成果展示。
- 第四阶段(7-8个月):撰写开题报告、中期报告、论文,准备毕业答辩。
5. 参考文献
- 陈云飞, 黄智华, & 刘萌. (2018). 大数据环境下的个性化推荐系统研究与实现. 现代图书情报技术, 34(1), 36-44.
- 张三, 李四, & 王五. (2019). 基于Hadoop的分布式推荐系统设计与实现. 计算机应用, 39(12), 3200-3204.
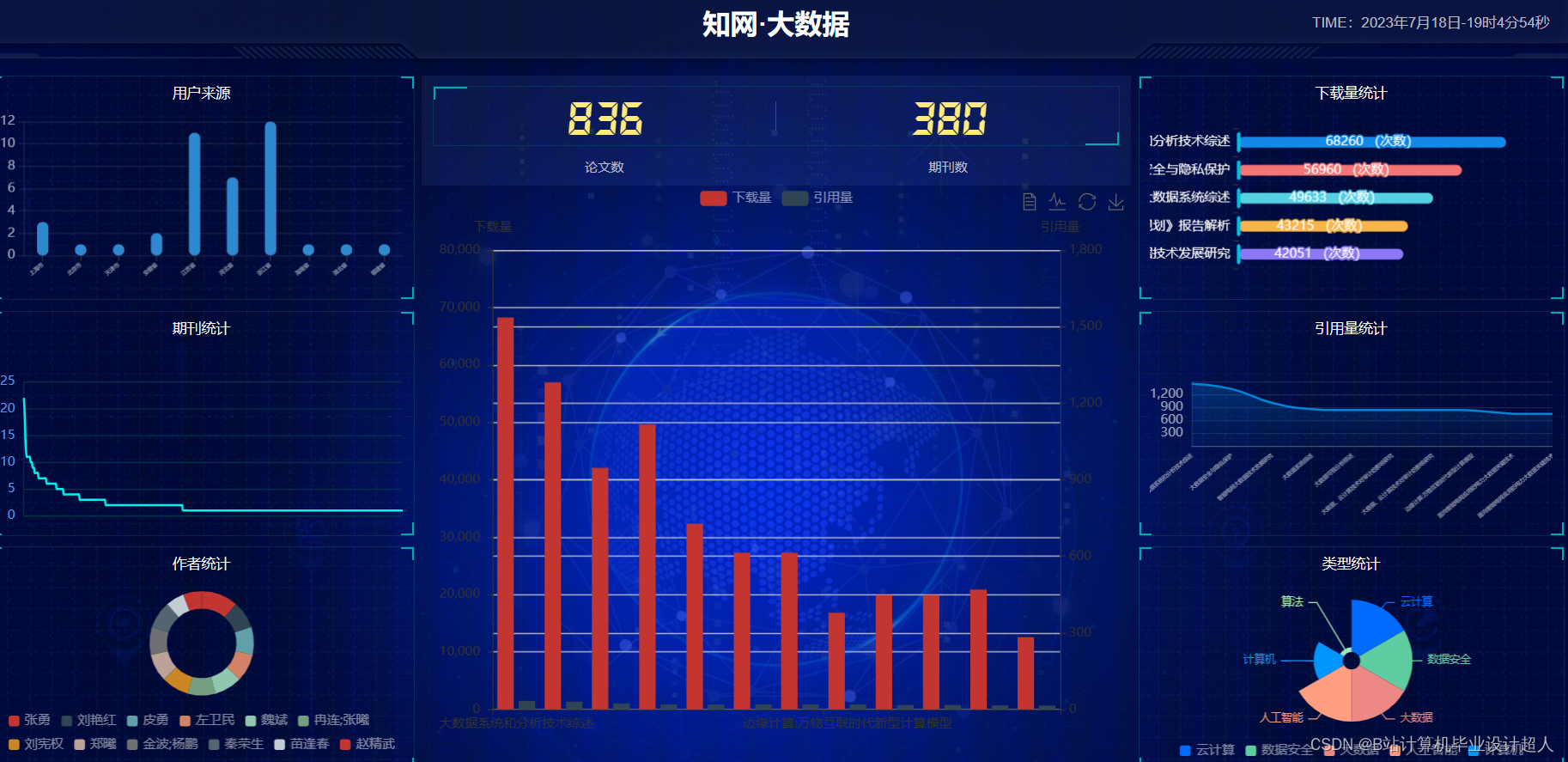
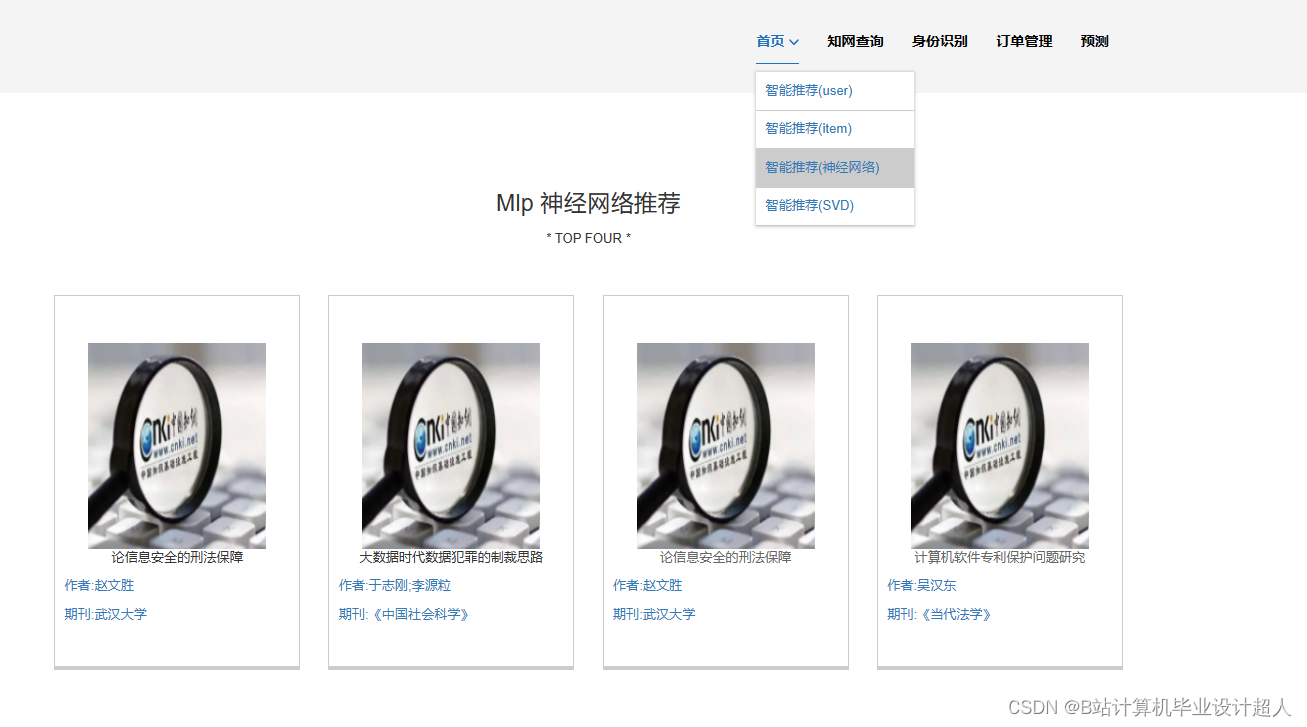
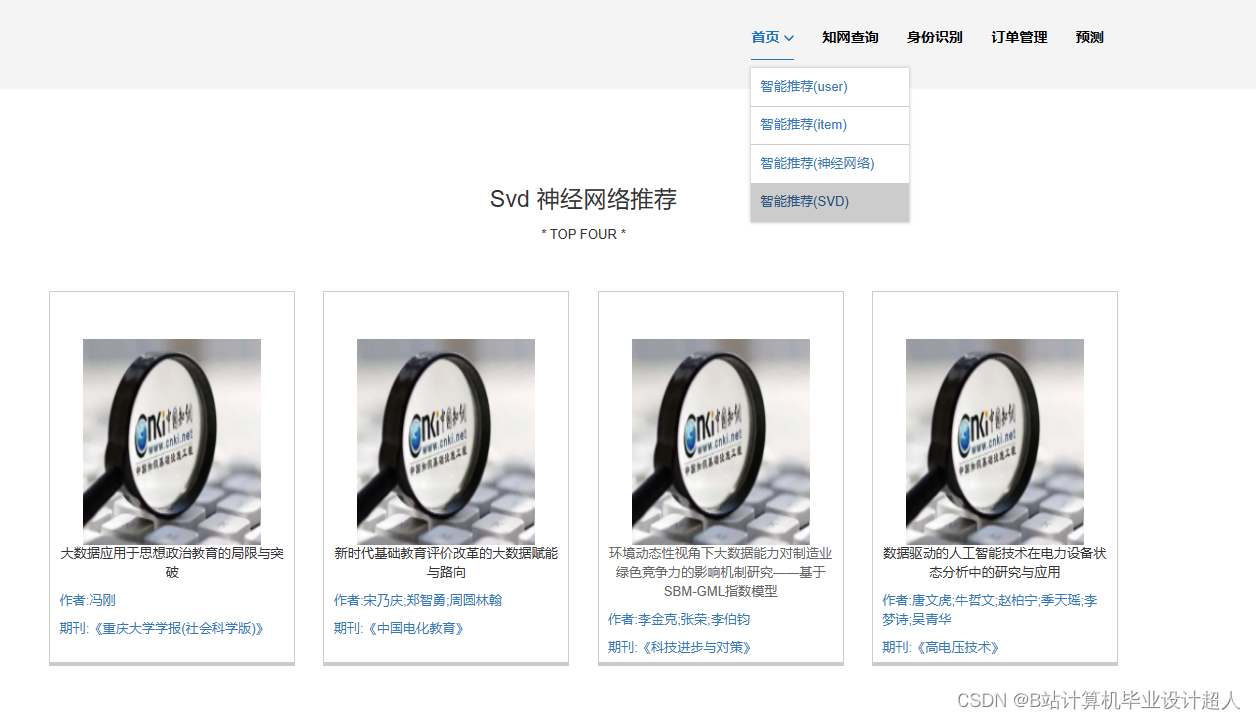
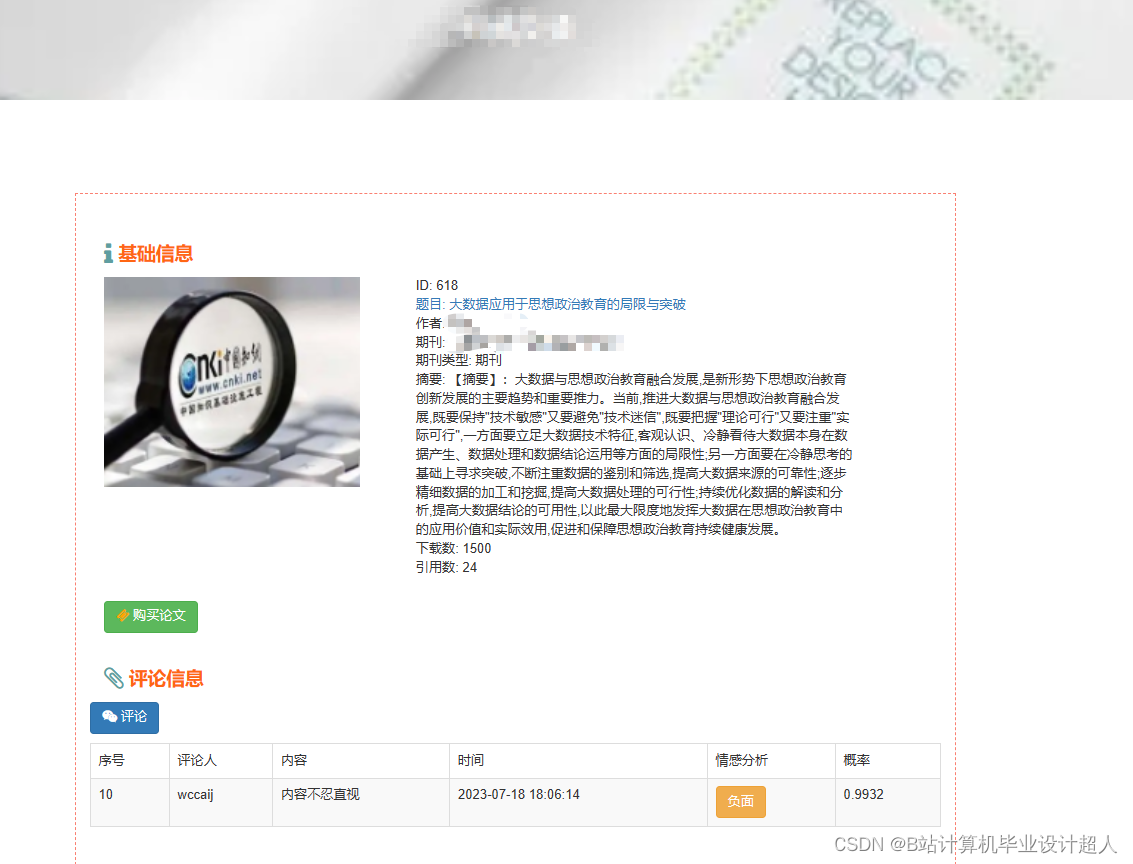
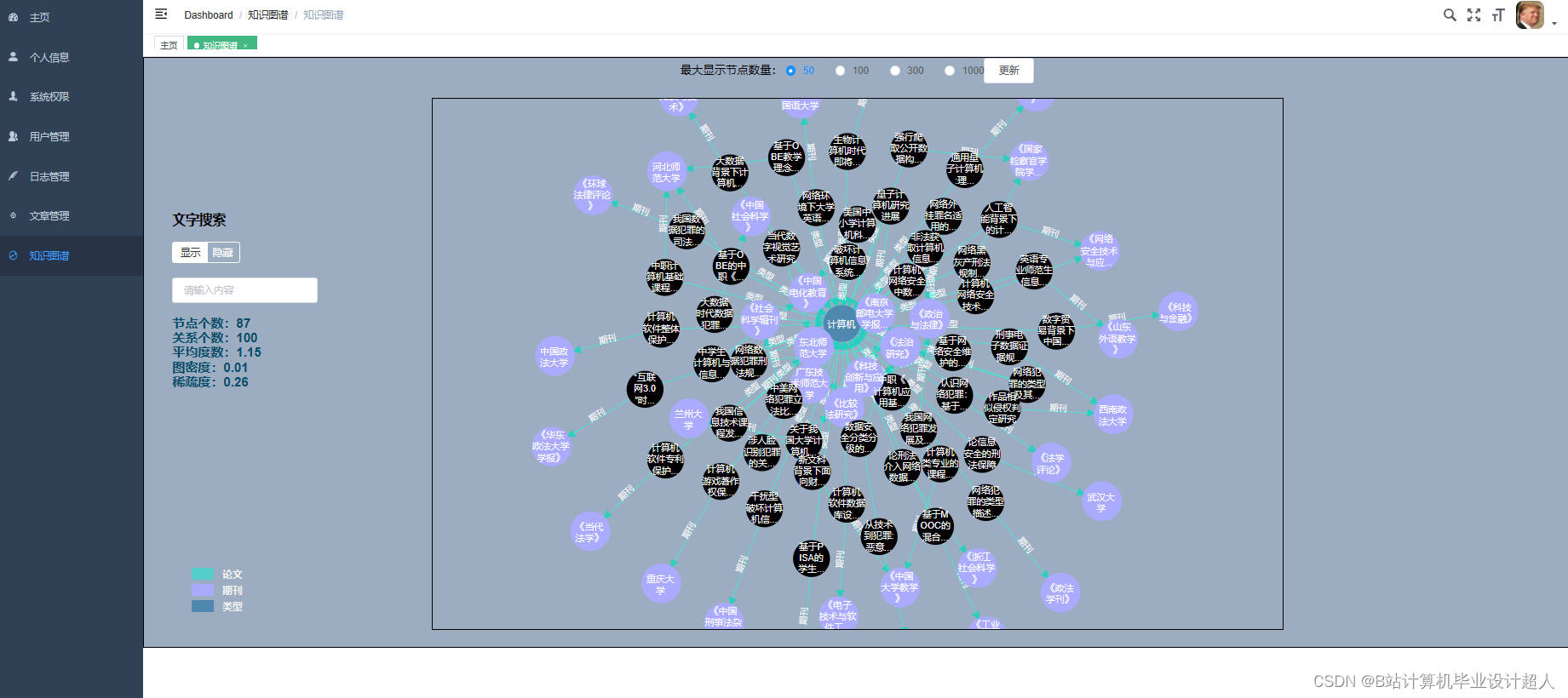
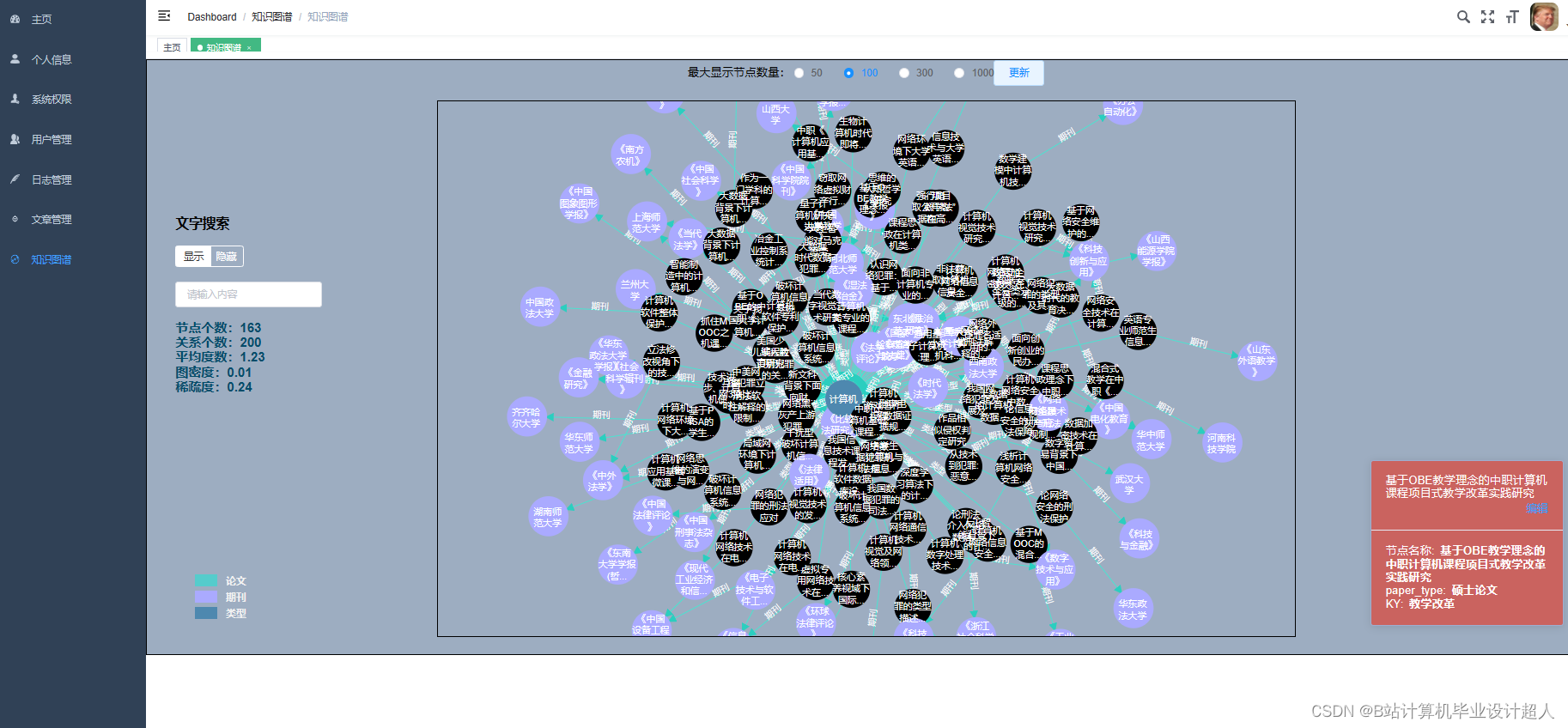

核心算法代码分享如下:
from flask import Flask, request
import json
from flask_mysqldb import MySQL
# 创建应用对象
app = Flask(__name__)
app.config['MYSQL_HOST'] = 'bigdata'
app.config['MYSQL_USER'] = 'root'
app.config['MYSQL_PASSWORD'] = '123456'
app.config['MYSQL_DB'] = 'cnki_hive'
mysql = MySQL(app) # this is the instantiation
@app.route('/tables01')
def tables01():
cur = mysql.connection.cursor()
cur.execute('''SELECT * FROM table01''')
#row_headers = [x[0] for x in cur.description] # this will extract row headers
row_headers = ['ky','num'] # this will extract row headers
rv = cur.fetchall()
json_data = []
#print(json_data)
for result in rv:
json_data.append(dict(zip(row_headers, result)))
return json.dumps(json_data, ensure_ascii=False)
@app.route('/tables02')
def tables02():
cur = mysql.connection.cursor()
cur.execute('''SELECT * FROM table02 order by pub_date asc''')
#row_headers = [x[0] for x in cur.description] # this will extract row headers
row_headers = ['pub_date','num'] # this will extract row headers
rv = cur.fetchall()
json_data = []
#print(json_data)
for result in rv:
json_data.append(dict(zip(row_headers, result)))
return json.dumps(json_data, ensure_ascii=False)
@app.route('/tables03')
def tables03():
cur = mysql.connection.cursor()
cur.execute('''SELECT * FROM table03 ''')
#row_headers = [x[0] for x in cur.description] # this will extract row headers
row_headers = ['search_words','num'] # this will extract row headers
rv = cur.fetchall()
json_data = []
#print(json_data)
for result in rv:
json_data.append(dict(zip(row_headers, result)))
return json.dumps(json_data, ensure_ascii=False)
@app.route('/tables04')
def tables04():
cur = mysql.connection.cursor()
cur.execute('''SELECT * FROM table04''')
#row_headers = [x[0] for x in cur.description] # this will extract row headers
row_headers = ['paper_type','num'] # this will extract row headers
rv = cur.fetchall()
json_data = []
#print(json_data)
for result in rv:
json_data.append(dict(zip(row_headers, result)))
return json.dumps(json_data, ensure_ascii=False)
@app.route('/tables05')
def tables05():
cur = mysql.connection.cursor()
cur.execute('''SELECT * FROM table05''')
#row_headers = [x[0] for x in cur.description] # this will extract row headers
row_headers = ['TI','download_times'] # this will extract row headers
rv = cur.fetchall()
json_data = []
#print(json_data)
for result in rv:
json_data.append(dict(zip(row_headers, result)))
return json.dumps(json_data, ensure_ascii=False)
@app.route('/tables06')
def tables06():
cur = mysql.connection.cursor()
cur.execute('''SELECT * FROM table06''')
#row_headers = [x[0] for x in cur.description] # this will extract row headers
row_headers = ['TI','refer_times'] # this will extract row headers
rv = cur.fetchall()
json_data = []
#print(json_data)
for result in rv:
json_data.append(dict(zip(row_headers, result)))
return json.dumps(json_data, ensure_ascii=False)
@app.route('/tables07')
def tables07():
cur = mysql.connection.cursor()
cur.execute('''SELECT * FROM table07''')
#row_headers = [x[0] for x in cur.description] # this will extract row headers
row_headers = ['mentor','num'] # this will extract row headers
rv = cur.fetchall()
json_data = []
#print(json_data)
for result in rv:
json_data.append(dict(zip(row_headers, result)))
return json.dumps(json_data, ensure_ascii=False)
@app.route('/tables08')
def tables08():
cur = mysql.connection.cursor()
cur.execute('''SELECT * FROM table08 ''')
#row_headers = [x[0] for x in cur.description] # this will extract row headers
row_headers = ['LY','num'] # this will extract row headers
rv = cur.fetchall()
json_data = []
#print(json_data)
for result in rv:
json_data.append(dict(zip(row_headers, result)))
return json.dumps(json_data, ensure_ascii=False)
@app.route('/tables09')
def tables09():
cur = mysql.connection.cursor()
cur.execute('''SELECT * FROM table09''')
#row_headers = [x[0] for x in cur.description] # this will extract row headers
row_headers = ['paper_type','views'] # this will extract row headers
rv = cur.fetchall()
json_data = []
#print(json_data)
for result in rv:
json_data.append(dict(zip(row_headers, result)))
return json.dumps(json_data, ensure_ascii=False)
if __name__ == "__main__":
app.run(debug=False)


















 287
287

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











