







毕业设计(论文)开题报告
| 一.研究目的及意义 意义:随着医疗技术的发展和医院规模的扩大,各大医院每天都会产生大量的数据,包括门诊挂号信息、各科室病人信息、医护人员信息等,这些数据对于疾病的预防、诊断和治疗等都具有重要的价值,因此,医院数据分析可视化系统有助于提高医务人员效率、促进医学研究和创新、提升医院管理水平,对提高医院的数据处理效率、提升医疗服务质量、推动医疗技术的发展具有重要的意义。 目的:传统的数据处理方式已经无法满足医院对数据处理和分析的需求,数据处理效率低下,无法处理大规模的数据,所以本课题旨在开发一种基于Hadoop的医院数据可视化分析系统,通过对医院数据的快速处理和分析,并提供数据可视化效果,以此深入挖掘数据的深层次信息和知识,提高医院的数据处理效率,从而提高医院的管理水平和医疗服务质量。 二.国内外研究进展 在国外,医院数据统计可视化分析系统的研究已经取得了显著的进展。一些医疗机构已经开始使用系统来监控和分析病人的医疗记录等数据,以发现医疗过程中的问题和改进的空间。同时,一些国外的科技公司也致力于开发更先进的数据分析和可视化工具。 相比之下,国内在这方面研究起步晚,但近年来也取得了不少进展。例如Yang Y等人[1]已经实现了对医疗大数据资源共享机制的分析与可视化,康敏等人[2] 运用信息可视化软件VOS viewer绘制2005年以来国内外医院大数据信息知识图谱,罗在文等人[3]搭建的分布式智慧医疗信息服务管理系统提高了Hadoop分布式智慧医疗信息系统的医疗业务信息管理质量,邢洪波[4]基于Hadoop对医疗数据存储进行研究,贾斐等人[5]总结了大数据技术在智慧医疗领域多种应用,都对医疗数据进行了分析或可视化研究。 另外,一些数据分析和可视化技术也有助于医院数据分析可视化系统的完成,例如李威等人[6]基于Hadoop对电商大数据进行可视化,汤梦瑶等人[7]基于Spark设计的地震数据分析与可视化系统,以及周正宇等人[8]基于Spark的数据分析可视化平台等,都为医疗系统提供了技术支持。 此外,国内的一些医疗机构和科技公司开始投入大量资源进行医疗大数据的分析和可视化研究,推出了一些具有自主知识产权的系统和产品。这些系统不仅可以对医疗数据进行分类、处理,还可以将结果以直观、易懂的方式呈现出来,帮助医疗专业人员更好地了解病人的病情和整体情况。 | |
毕业设计(论文)开题报告
| 1.解决的问题:本课题是医院数据统计可视化分析系统,主要功能是对数据分析处理后,实现对门诊和各科室病人、医护人员情况,以及医疗设备、手术用品使用情况等的可视化。 2.开发环境:Windows10、JDK1.8、Hadoop3、Spark3、MySql8 3.开发技术:Hadoop、SQL、JavaScript 4.开发与设计工具:VM虚拟机、Xftp7,Xshell7、Idea2021、Echarts 5.实现步骤: (1)运行环境搭建:首先准备好虚拟机环境,安装JDK、Hadoop,并配置环境变量和集群,之后启动和测试集群,完成Hadoop完全分布式集群搭建。 (2)数据采集和处理:首先从数据源获取医院相关数据,包括医院门诊和各科室病人数量、医护人员数量、手术室器具使用情况等,之后利用MapReduce的并行处理能力将数据清洗,处理完后上传至HDFS分布式系统。 (3)数据分析:首先下载安装Spark,配置环境变量,启动并测试集群,之后将数据加载到spark集群,对数据进行探索,分析出门诊大厅日均流动人数、门诊日均挂号人数、各科室每日接纳病人数量、各科室间人员流动情况、小大型手术室每日收拾用品使用情况等。 (4)数据可视化:首先在MySQL中创建存放数据的数据库和数据库表,将分析后的数据保存至数据库,之后在IDEA中连接MySQL数据库,通过SQL查询语句从数据库中导出数据,最后使用ECharts的Javascript语言进行数据可视化,并运行调试。 |
毕业设计(论文)开题报告
| 四.工作进度安排
五.主要参考文献 [1] YANG Y,CHEN T. Analysis and visualization implementation of medical big data resource sharing mechanism based on deep learning [J].IEEE Access,2019,7:156077-156088. [2]康敏,吴聪丽,吴本清等.大数据时代医院统计信息数据分析中的研究热点与可视化分析[J].中国卫生统计,2023,40(02):219-223. [3]罗在文,宁思华,王腾飞.大数据技术在智慧医疗中的应用研究[J].信息与电脑(理论版),2023,35(17):97-100. [4]邢洪波.基于Hadoop的医疗数据存储的研究[D].沈阳:沈阳工业大学,2023. [5]贾斐,任九选,冯天宜.大数据技术在智慧医疗中的应用[J].通信管理与技术,2022(04):11-13. [6]李威,邱永峰.基于Hadoop的电商大数据可视化设计与实现[J].现代信息科技,2023,7(17):46-49. [7]汤梦瑶,程斐斐.基于Spark的地震数据分析与可视化系统设计与实现[J].现代信息科技,2023,7(18):20-24. [8]周正宇,康华夏,刘文军等.基于Spark的数据分析可视化平台设计与实现[J].电脑知识与技术,2022,18(24):72-74. |
毕业设计(论文)任务书
毕业设计(论文)题目: 基于Hadoop的医院数据统计可视化分析系统
系部: 理学系 专业: 数据科学与大数据技术 学号: 202088108
学生: 周晓渊 指导教师(含职称): 王晋明(高级工程师)柴立臣(讲师)
1.课题意义及目标
通过本次毕业设计,学生运用所学过的基础理论知识,对系统进行Hadoop集群搭建、Spark集群和Spark数据分析、MySQL数据库设计等设计、开发与交付等多个核心环节,通过运用先进的数据挖掘和分析算法,系统将能够提供实时、准确的数据,为构建智慧医疗体系提供有力支持,并为学生在毕业后从事大数据开发或大数据运维打下坚实的基础。
2.主要任务
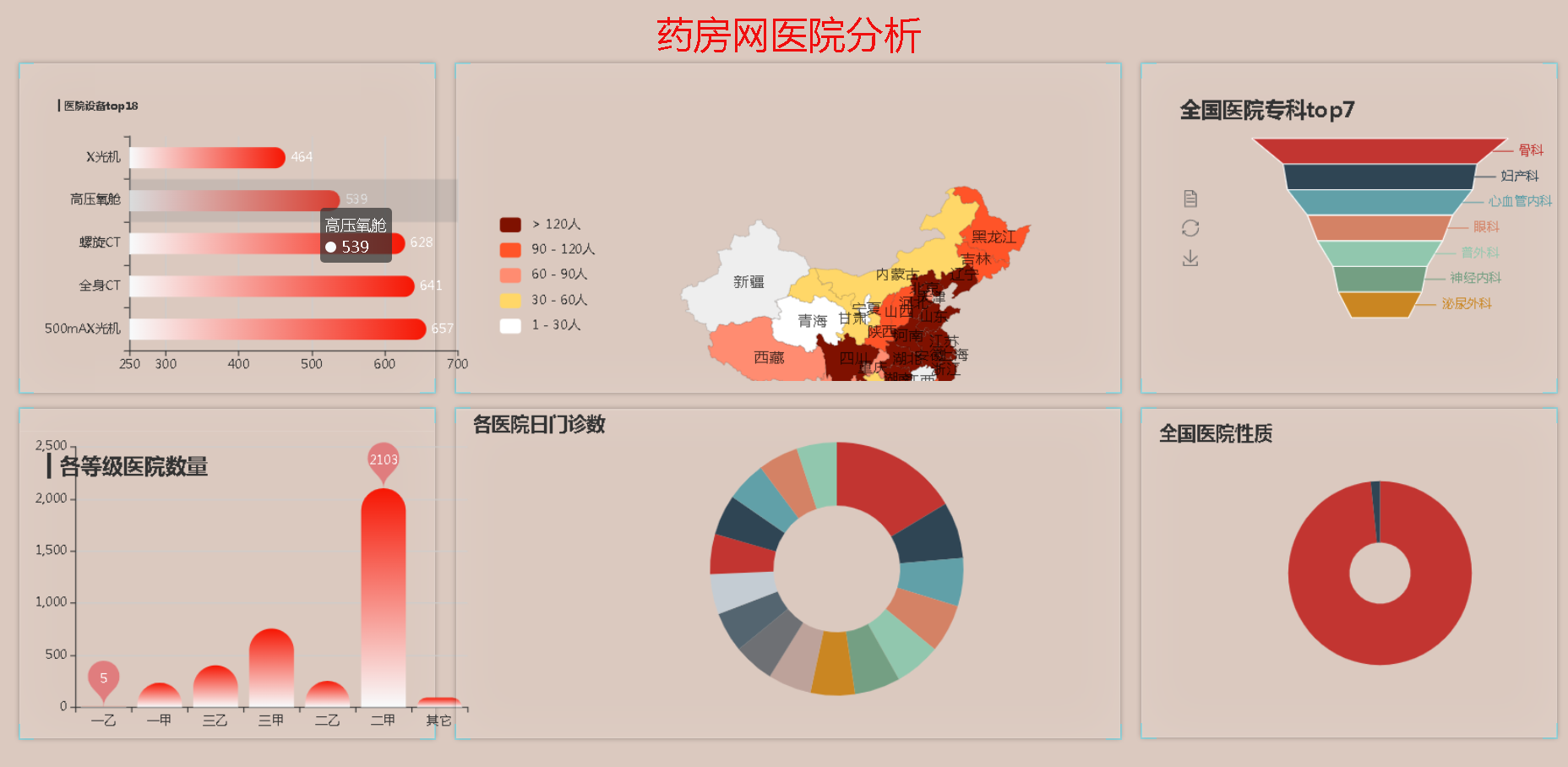
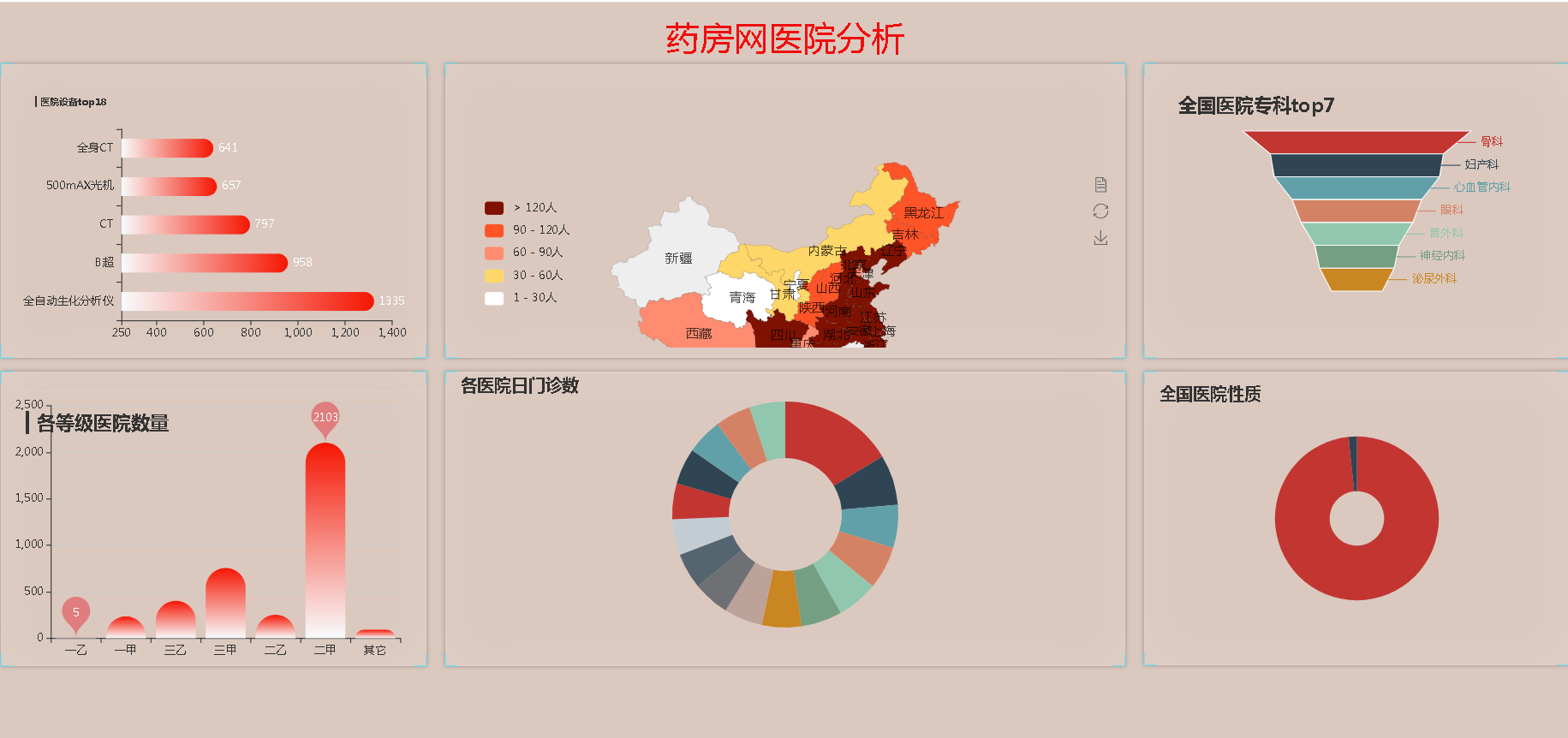
(1)制作医院数据统计可视化分析系统,能直观展示门诊和各科室病人、医护人员的情况,以及医疗设备、手术用品的使用情况等。
(2)确定课题任务,准备医院相关数据,准备运行环境。
(3)完成Hadoop完全分布式集群搭建,并对数据进行数据清洗后,上传至HDFS分布式系统。
(4)将上传的数据利用spark集群进行数据分析,通过MySql进行数据库中表的设计,将数据存储在不同表中。
(5)最后将MySql中的数据可视化在Web页面上,完成医院数据可视化分析系统。
3.主要参考资料
[01] 王瑞梅. 网络招聘数据可视化分析系统的设计与实现[D].河北师范大学,2020.
[02] 李威,邱永峰.基于Hadoop的电商大数据可视化设计与实现[J].现代信息科技,2023
[03] 胡雪洁.基于Hive的电商数据分析平台的实现与应用[D].汕头大学,2021.
[04] 黄东军.Hadoop大数据实战权威指南[M].电子工业出版社:201908.320.
4.进度安排
| 设计(论文)各阶段名称 | 起 止 日 期 | |
| 1 | 任务书下达和毕设项目准备 | 2023年12月25日~2024年02月29日 |
| 2 | 毕业设计(论文)开题答辩 | 2024年03月01日~2024年03月10日 |
| 3 | 环境的搭建、数据的采集和处理 | 2024年03月11日~2024年03月31日 |
| 4 | 根据数据维度进行数据分析 | 2024年04月01日~2024年04月20日 |
| 5 | 毕业设计(论文)中期检查 | 2024年04月21日~2024年04月30日 |
| 6 | 数据可视化展示 | 2024年05月01日~2024年05月19日 |
| 7 | 完成毕业设计(论文)全文电子档及查重 | 2024年05月20日~2024年06月02日 |
| 8 | 完成毕业论文及答辩工作 | 2024年06月03日~2024年06月20日 |
审核人: 年 月 日
2024 届本科毕业设计(论文)中期进展情况检查表
| 学生姓名 | 周晓渊 | 学号 | 202088108 | 专业 | 数据科学与大数据技术 | 填表日期 | 2024.04.26 | |||
| 毕业设计(论文)题目 | 基于Hadoop的医院数据统计可视化分析系统 | |||||||||
| 已 完 成 的 任 务 | 1、完成对医院数据统计可视化大屏的需求分析; 2、完成整个项目所需要的MySQL数据库和表设计:患者信息表、诊断表、费用记录表、药物使用表等; 3、完成项目设计与开发前的运行环境准备:Hadoop完全分布式环境; 4、完成项目的部分前端界面设计与开发; | |||||||||
| 是否符合任务书要求进度 | 是 | |||||||||
| 尚 须 完 成 的 任 务 | 1、对项目不足的地方进行优化; 2、利用Spark对MySQL数据库里的数据进行有规律的分析,并得到新表数据或新数据文件; 3、对以上分析后得到的数据通过前端的Echarts进行大数据可视化展示,制作出医院可视化大屏; 4、编写毕业设计(论文)全文电子档; | |||||||||
| 能否按期完成任务 | 能 | |||||||||
| 存 在 的 问 题 和 解 决 办 法 | 存在的问题 | 1、目前项目中的图片加载不出来; 2、数据库中表与表之间的关系需要优化; 3、利用Spark进行数据分析时数据较多; 4、数据可视化展示; | ||||||||
| 拟采取的办法 | 1、增加数据库中表的外键,各数据表间联系起来; 2、使用Spark的并行处理能力,将大数据分成小块处理; 3、在IDEA中连接Mysql数据库,并使用Echarts等生成图表,完成可视化; | |||||||||
| 指导教师意见 | 教师签名: | |||||||||
| 专家组意见 | 组长签名: | |||||||||
| 教学主任意见 | 教学主任签名: | |||||||||
检查日期: 年 月 日
核心算法代码分享如下:
package com.imust.mr.clean;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class Driver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
Configuration config = new Configuration();
Job job = Job.getInstance(config);
job.setJarByClass(Driver.class);
job.setMapperClass(ClMapper.class);
job.setReducerClass(ClReducer.class);
job.setMapOutputKeyClass(Map_Car.class);
job.setMapOutputValueClass(NullWritable.class);
job.setOutputKeyClass(Map_Car.class);
job.setOutputValueClass(NullWritable.class);
FileSystem fs = FileSystem.get(config);
Path outPath = new Path("D:\\hadoop_spark_hive_hospital2024\\output");
if (fs.exists(outPath)) {
fs.delete(outPath, true);
}
FileInputFormat.setInputPaths(job, new Path("d:\\hadoop_spark_hive_hospital2024\\input\\data.csv"));
FileOutputFormat.setOutputPath(job, outPath);
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}


















 2863
2863

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











