







课程推荐系统开题报告
一、研究背景与意义
随着在线教育的快速发展,越来越多的学习者选择通过网络平台获取学习资源。然而,面对海量的在线课程,学习者往往难以快速找到符合自己兴趣和需求的课程。因此,开发一个高效、智能的课程推荐系统,对于提升学习者的学习体验、提高课程资源的利用效率具有重要意义。
课程推荐系统能够通过对学习者的历史行为、学习偏好等数据进行分析,为学习者推荐符合其兴趣和需求的课程。这不仅能够帮助学习者节省寻找课程的时间,提高学习效率,还能够为在线教育平台提供有价值的数据支持,优化课程资源的配置和推荐策略。
二、研究目的与目标
本研究的主要目的是开发一个高效、智能的课程推荐系统,具体目标包括:
- 数据收集与预处理:收集学习者的历史行为数据、学习偏好等信息,并进行预处理,以便后续分析。
- 特征提取与学习者画像构建:从预处理后的数据中提取关键特征,构建学习者的画像,为推荐算法提供精准的用户特征。
- 推荐算法研究:研究并应用先进的推荐算法,如协同过滤、深度学习等,根据学习者画像和课程资源信息为学习者推荐合适的课程。
- 系统设计与实现:设计并实现课程推荐系统的功能模块,包括用户管理、课程资源管理、推荐算法模块等,确保系统的稳定性和易用性。
三、研究内容与方法
本研究将围绕课程推荐系统的设计与实现展开,具体研究内容包括:
- 数据收集与预处理:通过在线教育平台收集学习者的历史行为数据、学习偏好等信息,并进行数据清洗、去重、标准化等预处理操作。
- 特征提取与学习者画像构建:从预处理后的数据中提取关键特征,如学习者的年龄、性别、学习领域偏好、学习时长等,构建学习者的画像。
- 推荐算法研究:研究并应用协同过滤、深度学习等先进的推荐算法,通过实验验证算法的有效性和准确性。同时,结合课程资源的特性,对算法进行优化和改进。
- 系统设计与实现:基于研究结果,设计并实现课程推荐系统的功能模块,包括用户管理、课程资源管理、推荐算法模块等。系统应具备用户注册、登录、课程浏览、推荐结果展示等功能,并确保系统的稳定性和易用性。
本研究将采用文献综述、实验验证和案例分析等方法进行研究。首先通过文献综述了解课程推荐系统的研究现状和发展趋势;然后通过实验验证推荐算法的有效性和准确性;最后通过案例分析验证系统的实用性和可推广性。
四、预期成果与贡献
本研究预期将取得以下成果和贡献:
- 开发一个高效、智能的课程推荐系统,为学习者提供个性化的课程推荐服务,提高学习者的学习效率和满意度。
- 提出一种基于学习者画像和课程资源信息的推荐算法,实现精准推荐,提高推荐效果和用户体验。
- 为在线教育平台提供一套有效的数据分析工具,帮助他们更好地了解学习者的需求和偏好,优化课程资源的配置和推荐策略。
五、研究计划与时间安排
本研究计划分为以下阶段进行:
- 第一阶段(XX月-XX月):进行文献综述和需求分析,明确研究目标和内容。
- 第二阶段(XX月-XX月):进行数据收集与预处理工作,为后续分析提供数据支持。
- 第三阶段(XX月-XX月):进行特征提取与学习者画像构建工作,为推荐算法提供用户特征。
- 第四阶段(XX月-XX月):研究并应用推荐算法,进行实验验证和结果分析。
- 第五阶段(XX月-XX月):设计并实现课程推荐系统的功能模块,进行系统测试和优化。
- 第六阶段(XX月-XX月):撰写论文并准备答辩工作。
以上是本研究的课程推荐系统开题报告,如有不足之处,请各位专家和老师指正。













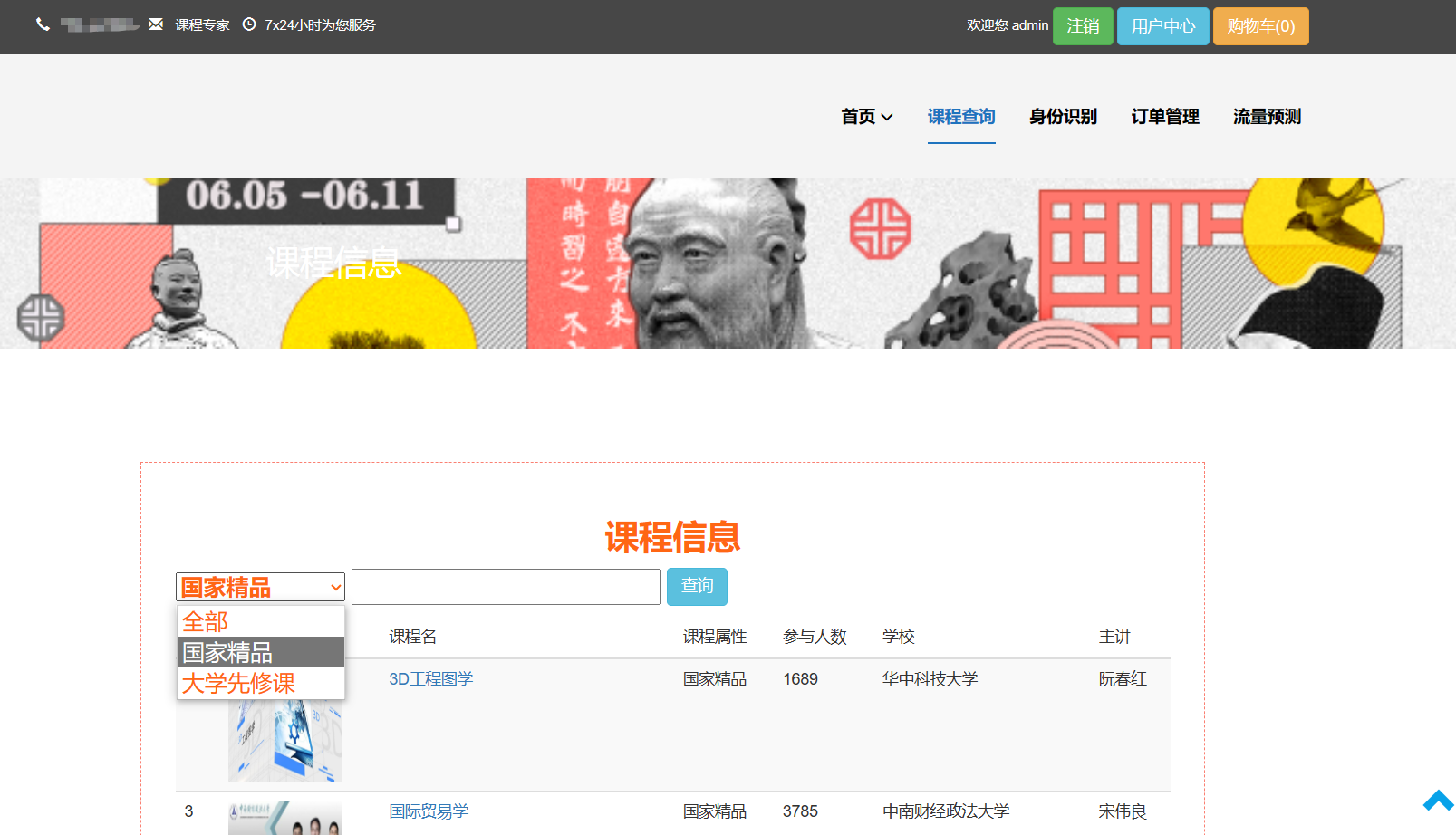
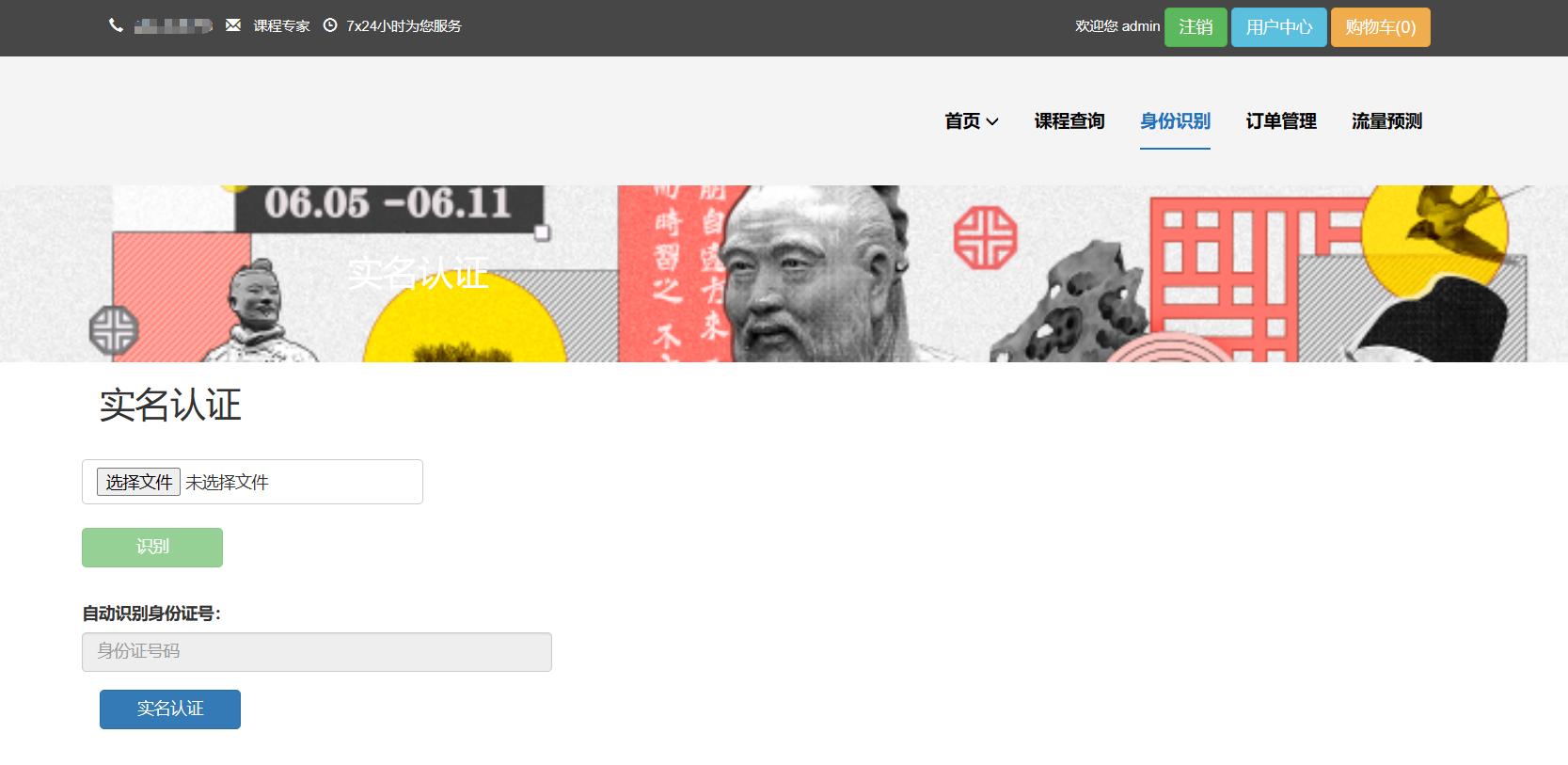



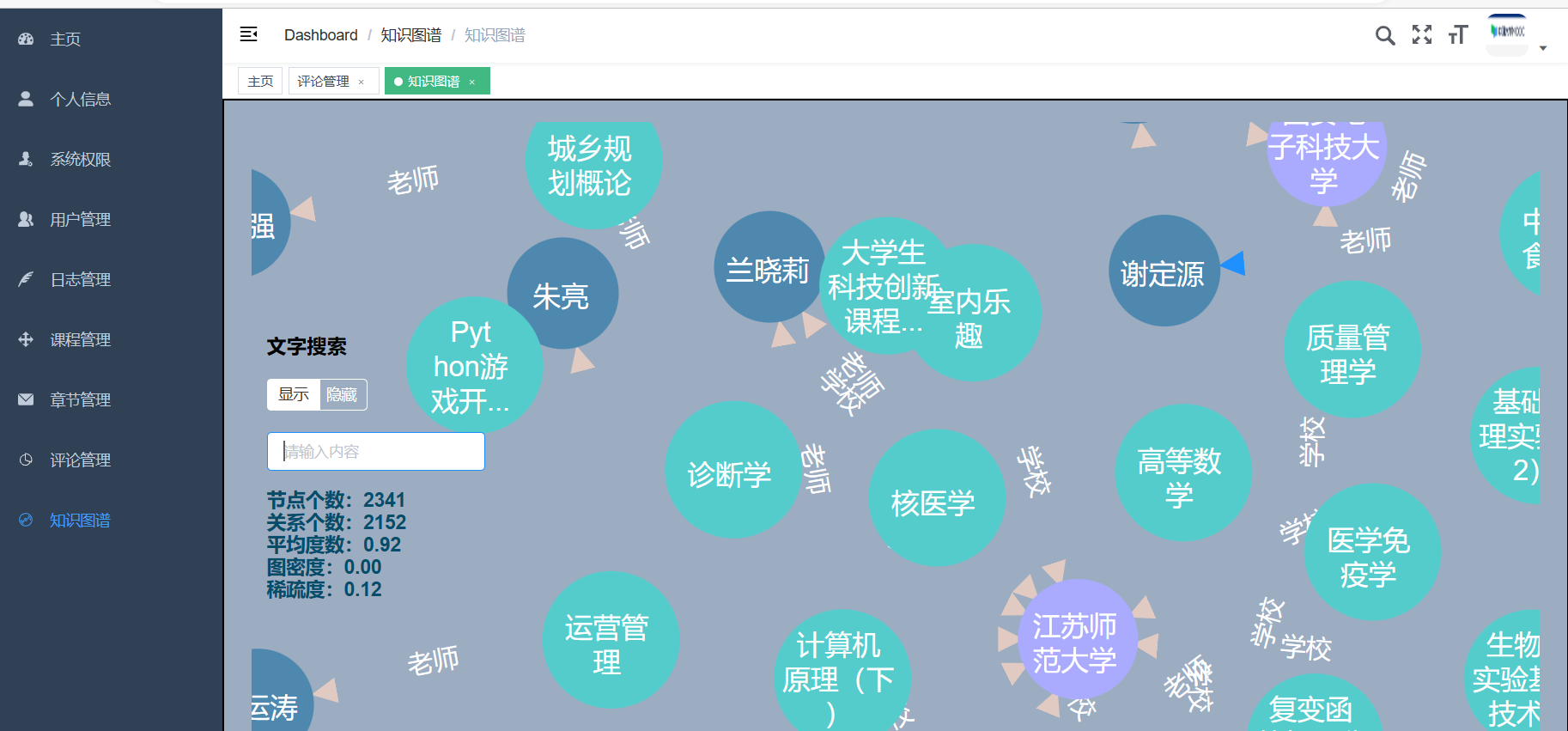


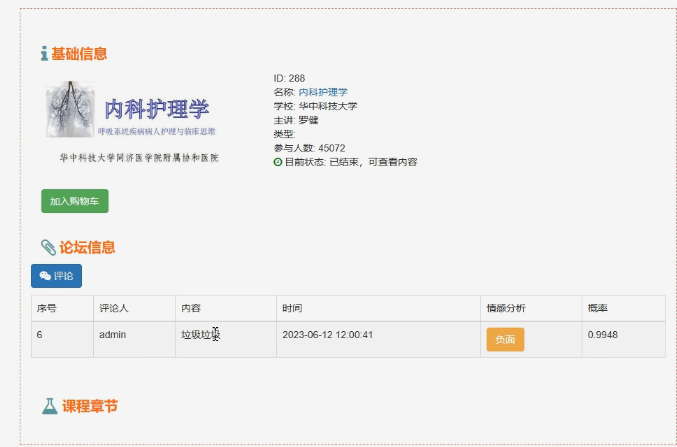










核心算法代码分享如下:
# -*- codeing = utf-8 -*-
# 创建图谱专用的json文件
import pandas as pd
import json
from db import db_util
d = db_util()
db, cursor = d.get_conn()
def build():
s_dict = {}
t_dict = {}
ret = []
ind1 = 10000
ind2 = 20000
ind3 = 30000
rind = 900000
sql = 'select * from tb_mooc'
df = pd.read_sql(sql, con=db)
for index, row in df.iterrows():
print(row['title'])
school = row['school']
teacher = row['teacher']
print(row['school'])
print(row['teacher'])
if school not in s_dict:
ind2 = ind2 + 1
s_dict[school] = ind2
if teacher not in t_dict:
ind3 = ind3 + 1
t_dict[teacher] = ind3
properties = {"name": row['title'], 'brief': row['brief'], 'status': row['status'], 'price':row['price']}
start = {'identity': index, 'labels':['课程'], 'properties':properties}
end = {'identity': ind2, 'labels':['高校'], 'properties':{"name": school}}
relationship = {"identity": rind, "start": index,"end": ind2,
"type": "type", "properties": {"name": "学校"}}
rind = rind + 1
segments = []
segments.append(dict(start=start, relationship=relationship, end=end))
end = {'identity': ind3, 'labels': ['老师'], 'properties': {"name": teacher}}
relationship = {"identity": rind, "start": index, "end": ind3,
"type": "type", "properties": {"name": "老师"}}
rind = rind + 1
segments.append(dict(start=start, relationship=relationship, end=end))
p = dict(segments=segments, length=1.0)
ret.append(dict(p=p, score=2))
json_str = json.dumps(ret, ensure_ascii=False)
with open('test.json', 'w', encoding='utf8') as f2:
# ensure_ascii=False才能输入中文,否则是Unicode字符
# indent=2 JSON数据的缩进,美观
json.dump(ret, f2, ensure_ascii=False, indent=2)
print(json_str)
print("end..")
if __name__ == '__main__':
build()















 1047
1047











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











