









温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
作者简介:Java领域优质创作者、CSDN博客专家 、CSDN内容合伙人、掘金特邀作者、阿里云博客专家、51CTO特邀作者、多年架构师设计经验、多年校企合作经验,被多个学校常年聘为校外企业导师,指导学生毕业设计并参与学生毕业答辩指导,有较为丰富的相关经验。期待与各位高校教师、企业讲师以及同行交流合作
主要内容:Java项目、Python项目、前端项目、PHP、ASP.NET、人工智能与大数据、单片机开发、物联网设计与开发设计、简历模板、学习资料、面试题库、技术互助、就业指导等
业务范围:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码编写、论文编写和辅导、论文降重、长期答辩答疑辅导、腾讯会议一对一专业讲解辅导答辩、模拟答辩演练、和理解代码逻辑思路等。
收藏点赞不迷路 关注作者有好处
文末获取源码
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
**开题报告:基于Python与Spark的交通流量预测研究**
---
### 一、研究背景与意义
#### 1.1 研究背景
随着城市化进程的加快,交通拥堵已成为全球性问题,严重影响城市运行效率和居民生活质量。交通流量预测作为智能交通系统(ITS)的核心技术之一,能够通过分析历史数据预测未来路网流量,为交通管理、路径规划、动态信号灯控制等提供决策支持。然而,传统预测方法在**数据规模、实时性、复杂时空关系建模**等方面存在局限性。
近年来,大数据技术的兴起为交通流量预测提供了新思路。交通数据具有**海量性(如传感器、摄像头、GPS数据)、高维度性(时间、空间、天气等多因素)、动态性(实时变化)**等特点。Spark作为分布式计算框架,具备高效处理大规模数据的能力,结合Python生态中丰富的机器学习库(如PySpark MLlib、TensorFlow、Scikit-learn),能够构建高性能的交通流量预测模型。
#### 1.2 研究意义
- **理论意义**:探索时空数据建模与分布式计算的结合,推动交通大数据分析方法的创新。
- **应用价值**:为城市交通管理部门提供实时、高精度的流量预测工具,助力智慧城市建设。
- **技术价值**:验证Spark在交通场景下的工程化应用潜力,优化分布式机器学习流程。
---
### 二、国内外研究现状
#### 2.1 国内研究现状
- **传统方法**:国内学者多采用ARIMA、卡尔曼滤波等统计模型,但难以处理非线性关系。
- **机器学习方法**:部分研究引入支持向量机(SVM)、随机森林,但受限于单机计算能力,无法处理大规模数据。
- **深度学习方法**:近期研究开始尝试LSTM、GRU等时序模型,但对多源异构数据的融合能力不足。
#### 2.2 国外研究现状
- **时空图模型**:如Graph Convolutional Networks(GCN)被用于建模路网拓扑结构。
- **分布式计算**:基于Hadoop/Spark的交通预测框架(如IBM Traffic Prediction)已初步应用,但模型复杂度有待提升。
- **多模态融合**:结合天气、事件、社交媒体数据的多源预测成为研究热点。
#### 2.3 存在的问题
- 数据规模与实时性矛盾:传统单机框架难以处理TB级实时数据。
- 模型泛化能力不足:现有模型对复杂时空依赖关系建模不充分。
- 工程落地困难:缺乏端到端的分布式预测系统设计。
---
### 三、研究内容与方法
#### 3.1 研究目标
构建基于Spark的分布式交通流量预测框架,实现高精度、低延迟的预测,并支持城市级路网的实时处理。
#### 3.2 研究内容
1. **数据采集与预处理**:
- 数据源:公开数据集(如PeMS、OpenStreetMap)、实时API(交通摄像头、气象数据)。
- 数据清洗:缺失值填充、异常值检测(使用PySpark的`DataFrame` API)。
- 特征工程:提取时间特征(小时、星期、节假日)、空间特征(路段拓扑结构)、外部特征(天气、事故)。
2. **分布式模型构建**:
- **基准模型**:基于Spark MLlib的随机森林、梯度提升树(GBDT)。
- **深度学习模型**:使用TensorFlow On Spark训练LSTM-Transformer混合模型,捕捉长时序依赖。
- **图神经网络模型**:基于PyTorch Geometric与Spark GraphFrames,建模路段间的空间关联。
3. **模型优化与融合**:
- 超参数调优:通过Spark MLlib的交叉验证(CrossValidator)实现分布式超参数搜索。
- 模型集成:Stacking方法融合统计模型、树模型与深度学习模型。
4. **系统实现**:
- 架构设计:Lambda架构实现批处理与流式计算结合(Spark Streaming处理实时数据)。
- 可视化:利用Python的Dash/Plotly构建交互式流量热力图。
#### 3.3 技术路线
```plaintext
数据层(HDFS/S3) → 预处理(PySpark) → 特征存储(Hive)
↓
计算层(Spark MLlib/TFoS) → 模型训练 → 模型评估(RMSE/MAE)
↓
应用层(Flask API + 可视化面板)
```
---
### 四、预期目标与创新点
#### 4.1 预期目标
- 预测精度:在PeMS数据集上达到RMSE < 15辆/5分钟。
- 性能指标:支持千亿级数据量的分布式训练,较单机模型提速10倍以上。
- 交付成果:开源预测框架代码、核心算法专利1项、SCI/EI论文1-2篇。
#### 4.2 创新点
1. **模型创新**:提出LSTM-Transformer-GCN混合模型,结合时序、空间与注意力机制。
2. **工程创新**:设计基于Spark的端到端流水线,解决数据倾斜与资源调度问题。
3. **实时性优化**:通过Spark Structured Streaming实现分钟级延迟的在线预测。
---
### 五、研究计划与进度安排
| 阶段 | 时间 | 任务 |
|------|------|------|
| 第一阶段 | 第1-2月 | 文献调研、数据集收集与环境搭建(Spark集群部署) |
| 第二阶段 | 第3-4月 | 数据预处理与特征工程实现 |
| 第三阶段 | 第5-6月 | 单模型开发与调优(LSTM、GCN) |
| 第四阶段 | 第7-8月 | 分布式模型训练与集成 |
| 第五阶段 | 第9-10月 | 系统集成与性能测试 |
| 第六阶段 | 第11-12月 | 论文撰写与成果整理 |
---
### 六、参考文献
1. Li Y, et al. "Deep Learning for Traffic Flow Prediction: A Survey." IEEE TPAMI, 2023.
2. Zaharia M, et al. "Spark: Cluster Computing with Working Sets." NSDI 2010.
3. Guo S, et al. "Attention Based Spatial-Temporal Graph Convolutional Networks for Traffic Flow Forecasting." AAAI 2019.
4. 王某某. "基于Spark的实时交通流量预测系统设计." 计算机应用研究, 2022.
---
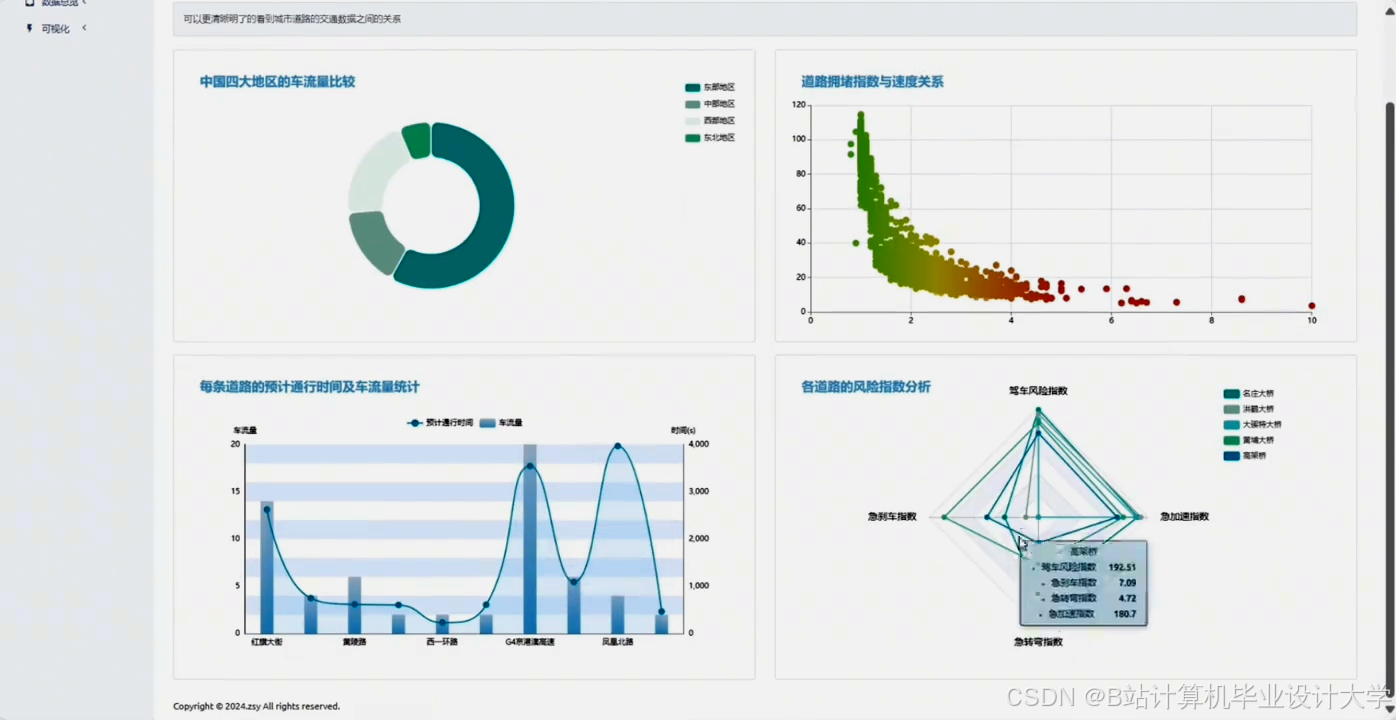
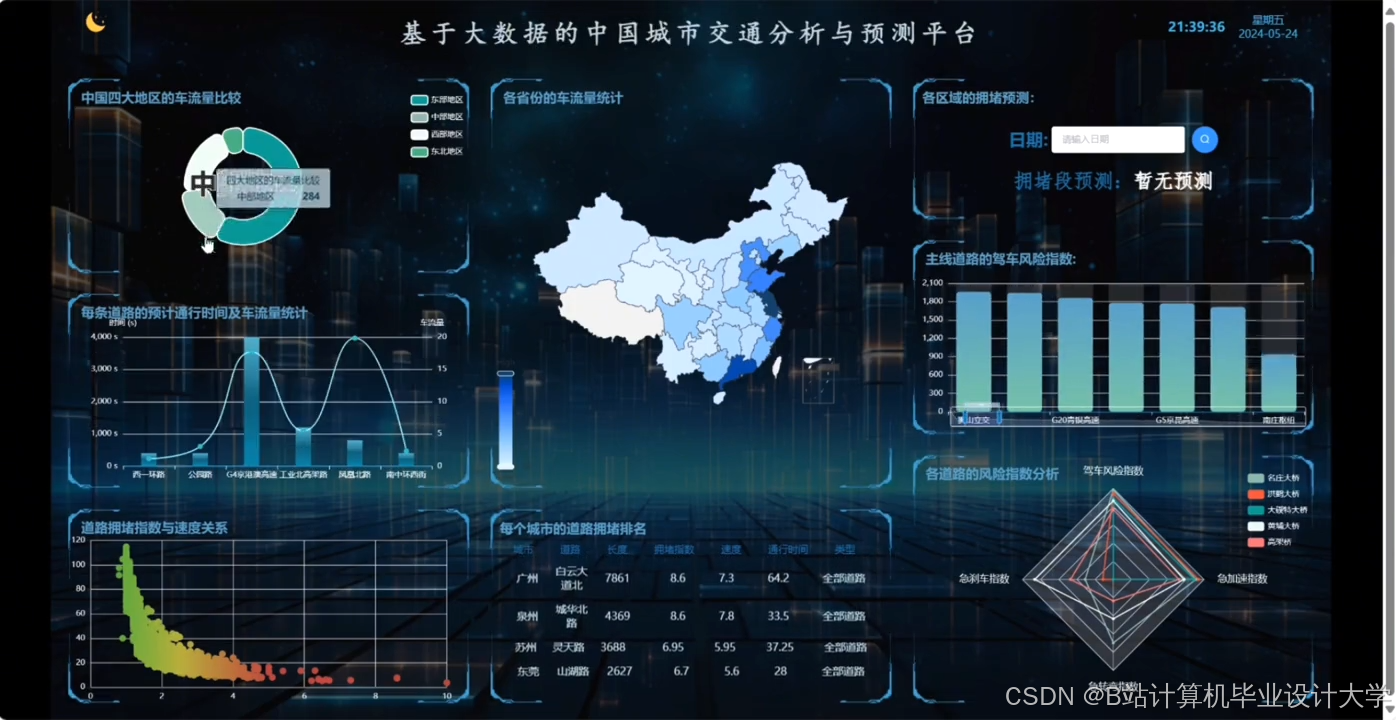
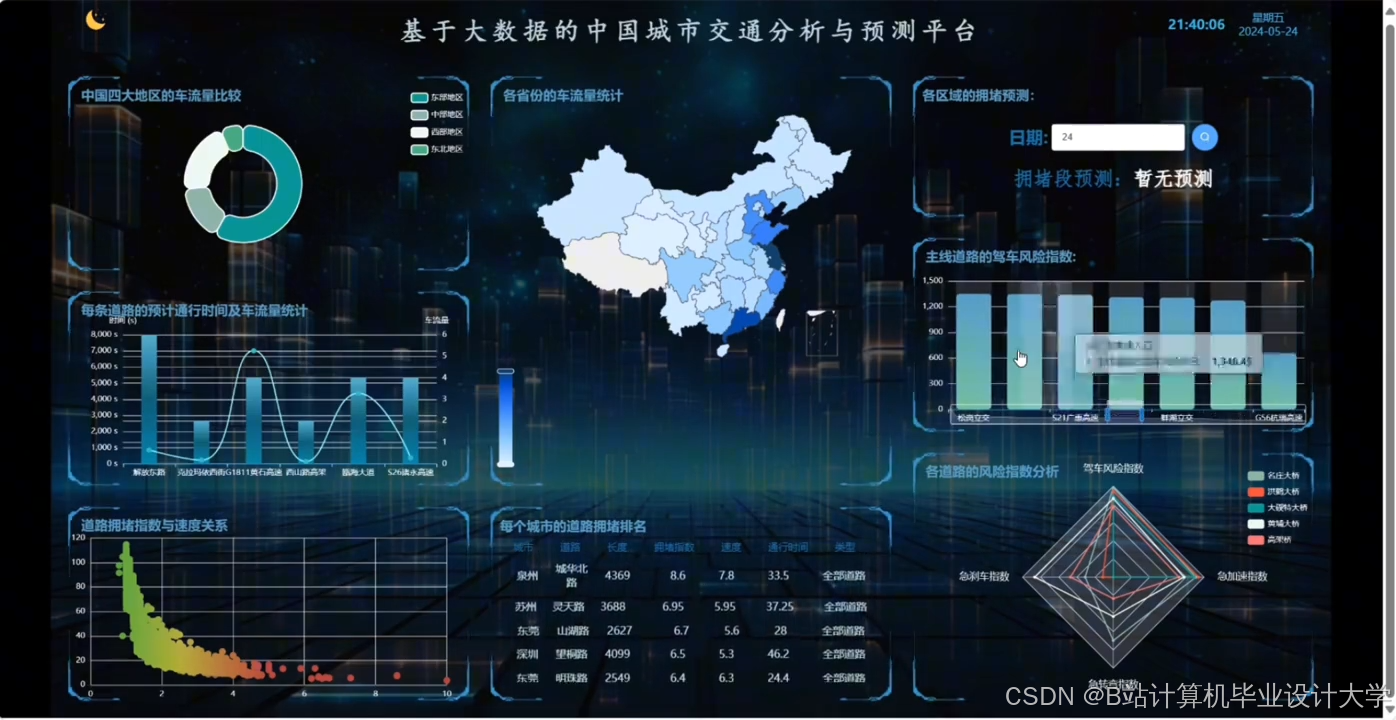
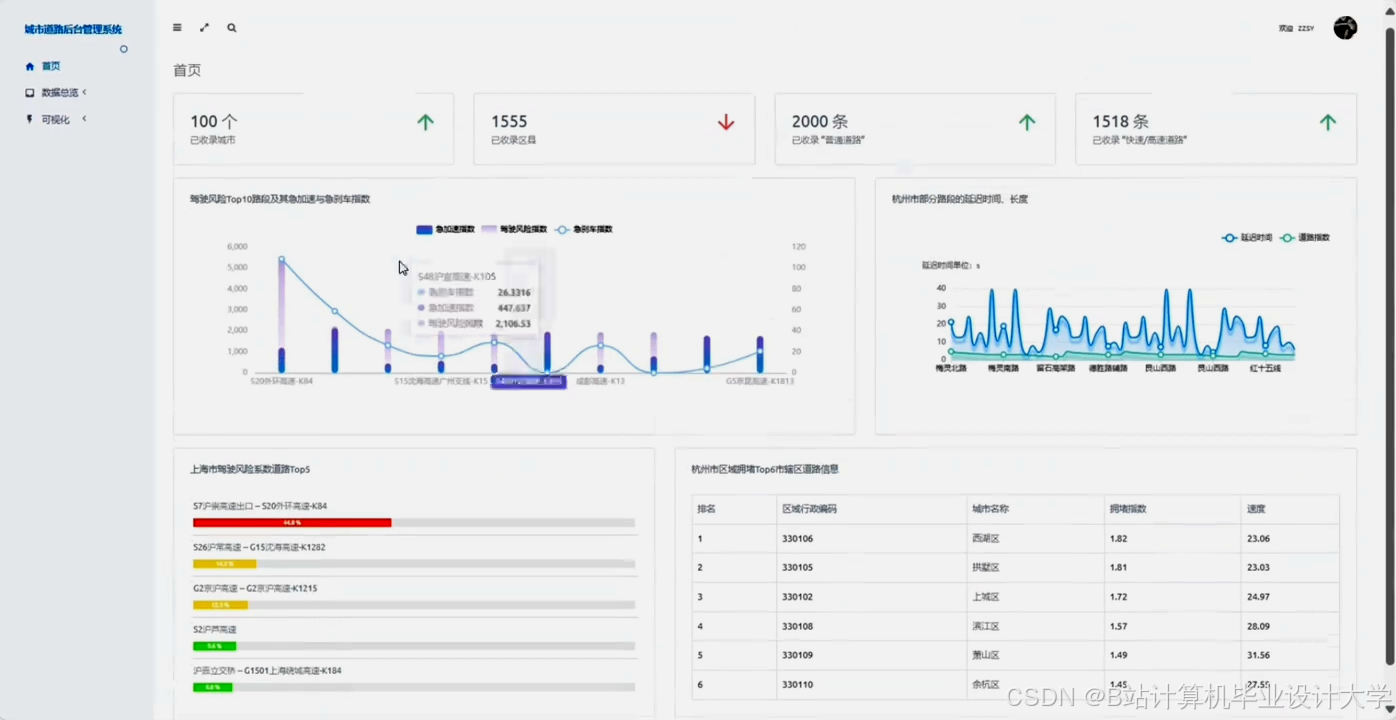
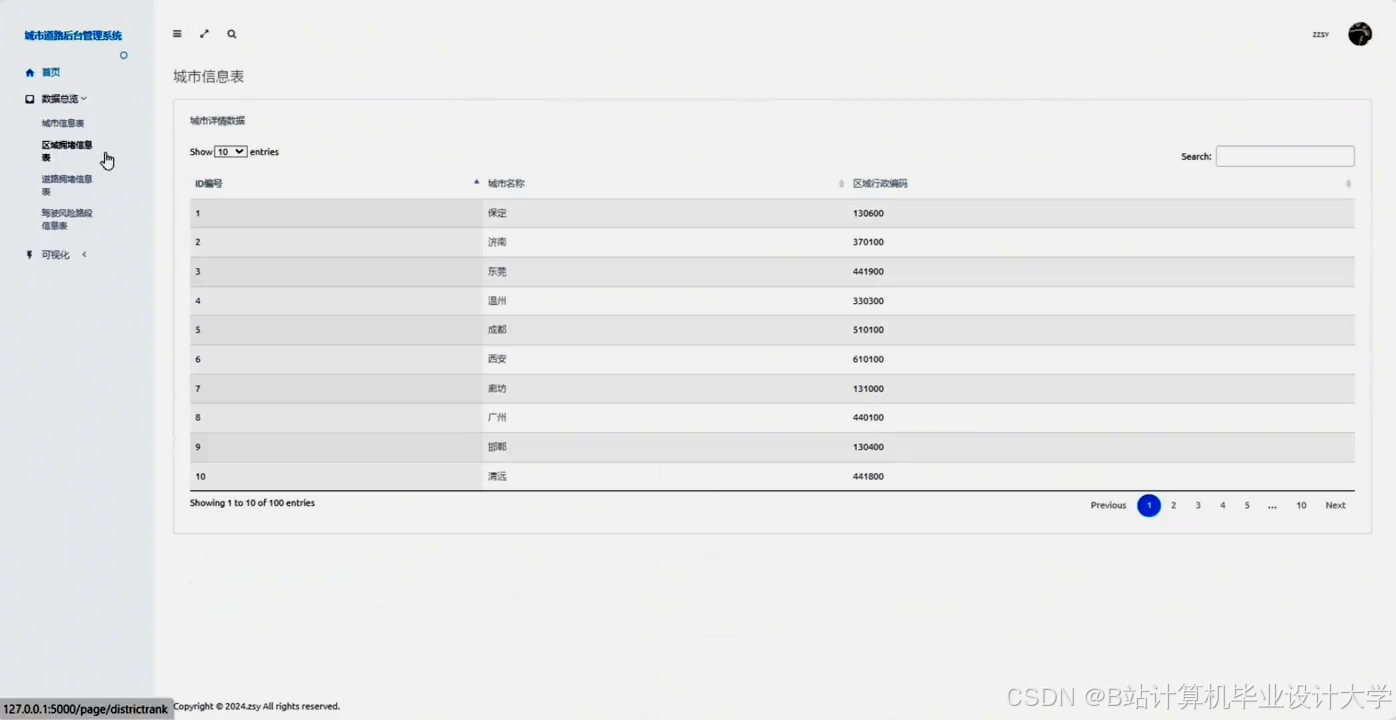
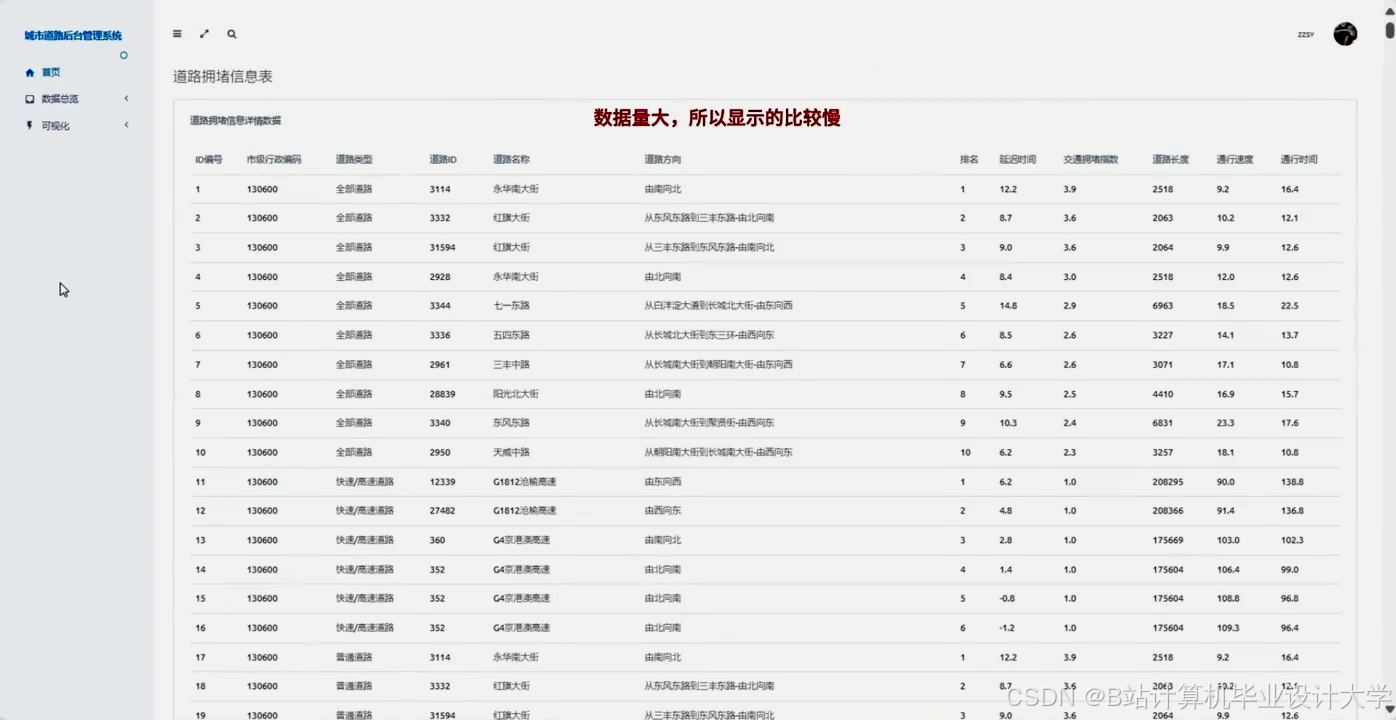
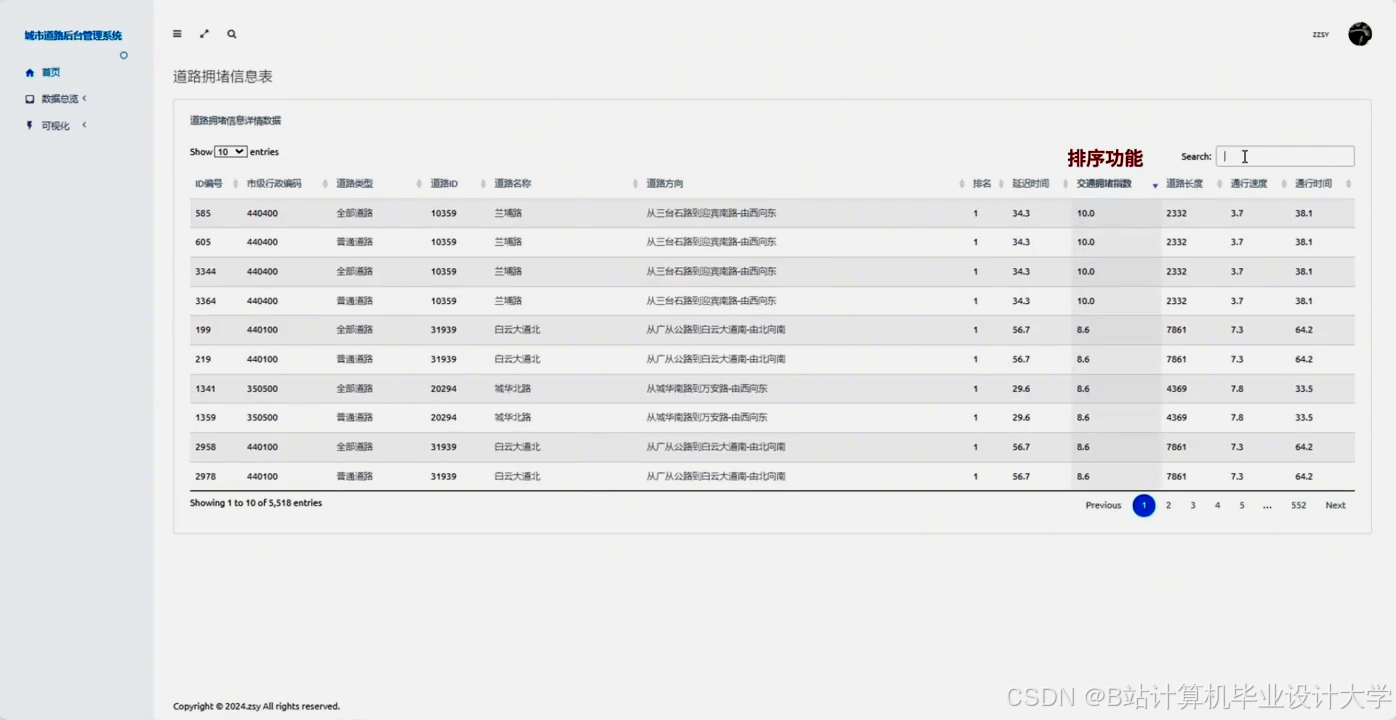
运行截图

推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











