







目录
1.文章介绍
本文将详细介绍使用Python爬虫根据歌手名称或歌曲名称进行音乐的爬取,音乐数据保存到本地!您还可以访问我的主页查看其它文章,您也可以在评论区或者私信发表您宝贵的意见或建议!
2.技术介绍
(1)requests库
requests是Python中一个非常流行的HTTP客户端库,它简化了许多发送HTTP请求的常见用例。使用requests库,你可以轻松地发送HTTP/1.1请求,并且有多种方法如GET请求,POST请求等等。
我们将通过requests库向目标网址发送请求,获取歌曲数据.
(2)re库
Python的
re库是一个用于处理正则表达式的库。正则表达式是一种在字符串中进行复杂搜索和替换的工具,它使用特殊的语法来描述要搜索的模式。
re库提供了许多函数和工具,使你可以在Python程序中使用正则表达式。
我们将使用正则表达式对请求的数据进行初步的筛选.
3.网页分析
因涉及到版权问题,这里不做详细分析.有需要的同学可以私信我.
4.代码实现
import hashlib
import time
import requests
import json
import re
# 登录网页版酷x音乐后很容易找到COOKIE
COOKIE = '换成你自己的cookie'
# 定义请求头
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.62',
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,"
"*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"accept-encoding": "gzip, deflate, br",
"accept-language": "zh-CN,zh;q=0.9,en;q=0.8",
"cache-control": "max-age=0",
'Cookie': COOKIE,
'Sec-Ch-Ua-Platform': "Windows",
'Sec-Fetch-Dest': 'script',
'Sec-Fetch-Mode': 'no-cors',
'Sec-Fetch-Site': 'same-site',
'Referer': 'https://www.kugou.com/',
}
# 要搜索的歌名
search_song_name = input('请输入你想要搜索的歌曲名称或歌手名称: ')
# 搜索的url
search_url = 'https://complexsearch.kugou.com/v2/search/song'
# 用来获取签名的数据
text = [
"NVPh5oo715z5DIWAeQlhMDsWXXQV4hwt",
"appid=1014",
"bitrate=0",
"callback=callback123",
"clienttime=1693422067307",
"clientver=1000",
"dfid=11S1hW0R7Bcg35YBWR1KxWuJ",
"filter=10",
"inputtype=0",
"iscorrection=1",
"isfuzzy=0",
f"keyword={search_song_name}",
"mid=741a0197fb501f9c1ded0c01c6544b34",
"page=1",
"pagesize=30",
"platform=WebFilter",
"privilege_filter=0",
"srcappid=2919",
"token=6b5be2025686cbde59d8416cd728f4b6c3cf3db88fbeee63262ccd9cab188547",
"userid=485601554",
"uuid=741a0197fb501f9c1ded0c01c6544b34",
"NVPh5oo715z5DIWAeQlhMDsWXXQV4hwt"
]
# "".join(text): 这行代码的作用是将text(可能是一个字符串列表)的所有元素连接起来,生成一个新的字符串
# .encode(encoding='utf-8'): 这部分将signature_data字符串以UTF-8编码转换为字节流,因为MD5哈希函数处理的是字节流,而不是字符串。
# hashlib.md5(...): 这部分将上一步得到的字节流进行MD5哈希加密。
# .hexdigest(): 这部分将上一步得到的MD5哈希对象转换为16进制的字符串表示,这就是最终的MD5签名signature
# 转换成字符串签名
signature = hashlib.md5("".join(text).encode(encoding='utf-8')).hexdigest() # md5加密
# print(signature)
# 发送搜索请求时向服务器发送的数据
data = {
"srcappid": "2919",
"clientver": 1000,
"clienttime": 1693422067307,
"mid": "741a0197fb501f9c1ded0c01c6544b34",
"uuid": "741a0197fb501f9c1ded0c01c6544b34",
"dfid": "11S1hW0R7Bcg35YBWR1KxWuJ",
"keyword": search_song_name,
"page": 1,
"pagesize": 30,
"bitrate": 0,
"isfuzzy": 0,
"inputtype": 0,
"platform": "WebFilter",
"userid": "485601554",
"iscorrection": 1,
"privilege_filter": 0,
"callback": "callback123",
"filter": 10,
"token": "6b5be2025686cbde59d8416cd728f4b6c3cf3db88fbeee63262ccd9cab188547",
"appid": 1014,
"signature": signature
}
# 获取请求到的数据
resp = requests.get(search_url, headers=headers, params=data).text
# 筛选数据
data = re.search('\{.*\}', resp).group()
# 从json数据中加载data列表里的lists列表
items = json.loads(data)['data']['lists']
# print(items[0])
# 遍历这个列表
for item in items:
# 歌曲id
song_id = item['EMixSongID']
# 获取歌曲播放信息的url
url = 'https://wwwapi.kugou.com/yy/index.php?r=play/getdata&callback=jQuery19106350861196723385_1693424511502' \
'&dfid=11S1hW0R7Bcg35YBWR1KxWuJ&appid=1014&mid=741a0197fb501f9c1ded0c01c6544b34&platid=4' \
f'&encode_album_audio_id={song_id}'
# 获取请求的数据
resp = requests.get (url, headers=headers).text
# 筛选数据
data = re.search('\{.*\}', resp).group()
# 获取json数据中的data列表
item = json.loads(data)['data']
audio_name = item['audio_name'] # 音频名称
play_url = item['play_url'] # 音频播放地址
# 根据音频播放地址获取音频数据
song_mp3_data = requests.get(play_url, headers=headers).content
# 保存音频数据
with open(f'../songs/{audio_name}.mp3', 'wb')as f:
f.write(song_mp3_data)
print(f'歌曲 {audio_name} 下载完成....')
time.sleep(2)
注:代码里的cookie需要替换成你自己的.
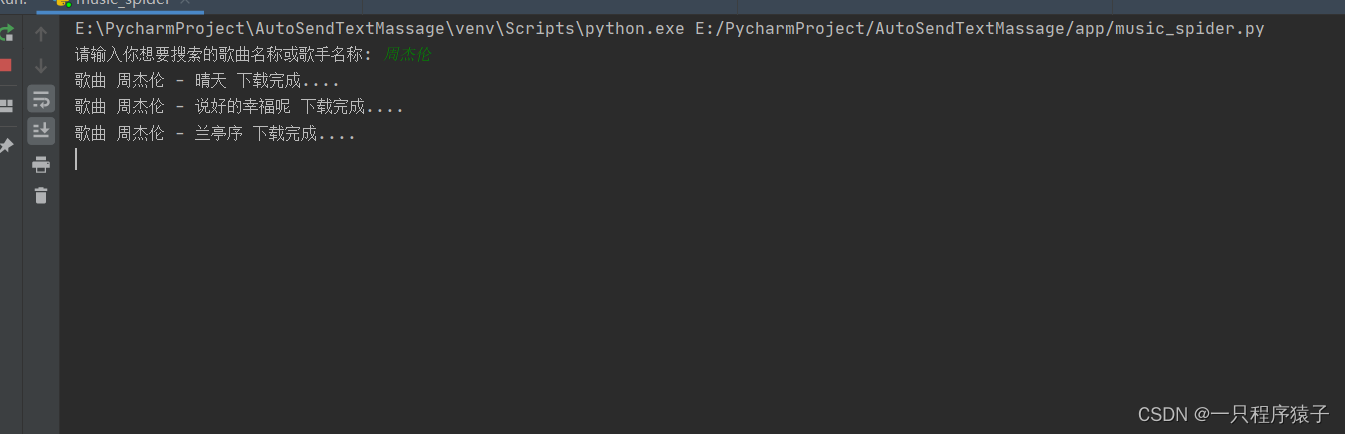
5.效果展示



















 499
499

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











