







1.介绍
本文将介绍Python调用第三方语音识别API实现语音转文本的方法,这里使用到的是百度语音识别API.学习到如何使用该API后,你可以在你的项目中添加语音转文本的功能.
文章创作不易,期待你的👍与⭐!
你还可以访问我的主页查看其他文章:
2.准备
(1)注册百度智能云账号
访问百度智能云主页注册账号或使用百度账号登录.
(2)领取免费的语音识别资源
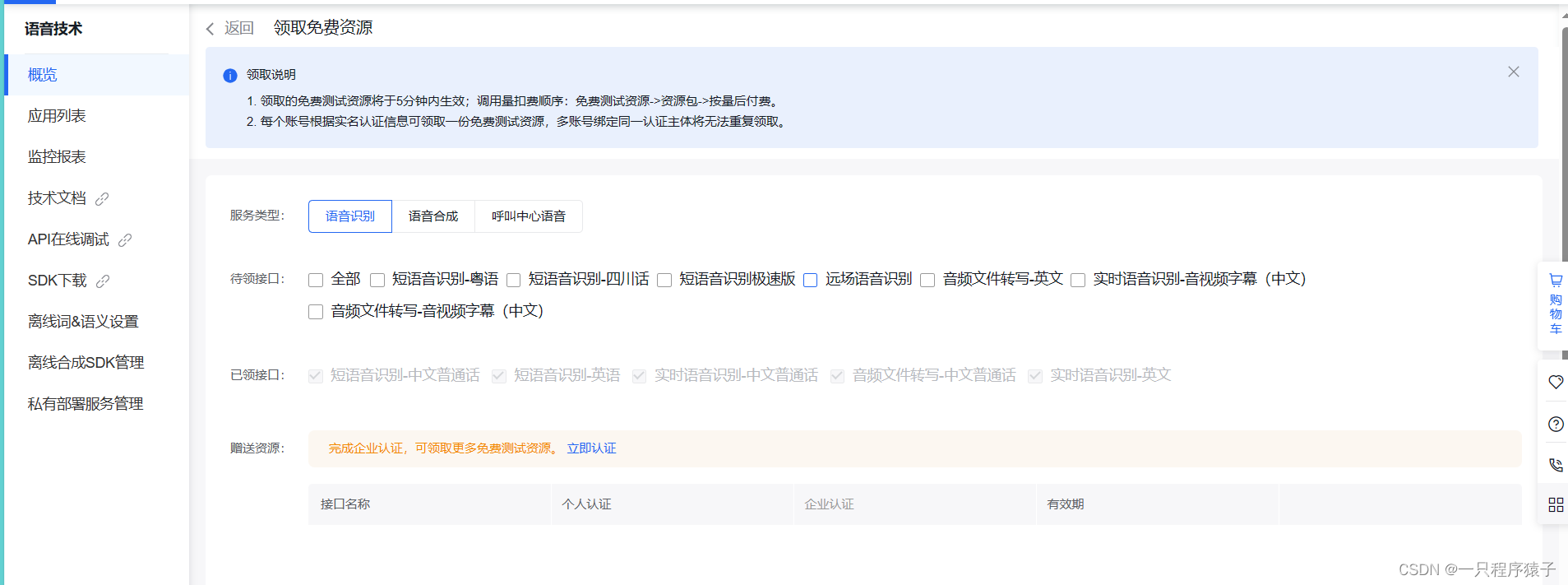
(3)创建新应用

(4) 创建完成后查看API Key和SECRET Key
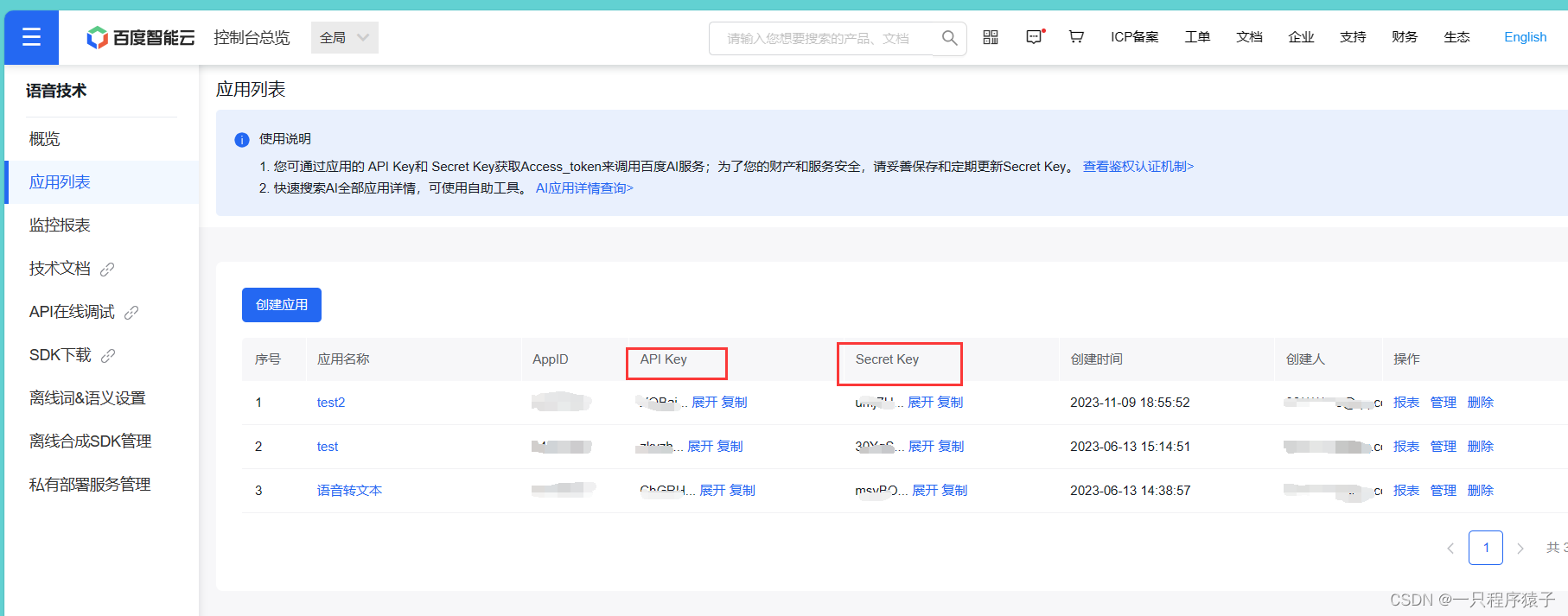
现在可以开始编写代码了
3.代码实现
我已在代码中做了详细注释:直接上代码!
import json
import base64
import time
from urllib.request import urlopen
from urllib.request import Request
from urllib.error import URLError
from urllib.parse import urlencode
timer = time.perf_counter
# 密钥
API_KEY = '替换成你自己的'
SECRET_KEY = '替换成你自己的'
# 这个随便填
CUID = 'audio_to_text_demo'
# 采样率
RATE = 16000 # 固定值
# 普通版
DEV_PID = 1537 # 1537 表示识别普通话,使用输入法模型。根据文档填写PID,选择语言及识别模型
ASR_URL = 'http://vop.baidu.com/server_api'
SCOPE = 'audio_voice_assistant_get' # 有此scope表示有asr能力,没有请在网页里勾选,非常旧的应用可能没有
# 自定义一个异常类
class DemoError(Exception):
pass
""" TOKEN start """
TOKEN_URL = 'http://aip.baidubce.com/oauth/2.0/token'
# 定义一个函数 fetch_token,该函数用于获取令牌,用于后续的 API 请求
def fetch_token():
# 定义一个字典 params,其中包含授权类型(grant_type)和客户端 ID(client_id)和秘钥(client_secret)
params = {'grant_type': 'client_credentials',
'client_id': API_KEY,
'client_secret': SECRET_KEY}
# 使用 urlencode 对 params 进行编码
post_data = urlencode(params)
# 将编码后的 post_data 转为 utf-8 编码的字节流
post_data = post_data.encode('utf-8')
# 创建一个新的 Request 对象,用于发送 POST 请求到 TOKEN_URL,请求的内容是 post_data
req = Request(TOKEN_URL, post_data)
try:
# 使用 urlopen 发送请求,返回一个文件对象 f,可以使用 f.read() 读取返回的内容
f = urlopen(req)
# 读取返回的内容并转为字符串
result_str = f.read()
# 如果出现网络错误(如网络连接中断、服务器异常等),进入异常处理
except URLError as err:
# 打印错误代码和错误信息
print('token http response http code : ' + str(err.code))
result_str = err.read()
# 将结果转为 utf-8 编码的字符串
result_str = result_str.decode()
# 打印结果(这行代码被注释掉,不会执行)
# print(result_str)
# 将结果转为字典对象(假设结果是以 json 格式返回的)
result = json.loads(result_str)
# 打印结果(这行代码被注释掉,不会执行)
# print(result)
# 检查返回结果中是否包含 access_token 和 scope 键值对
if ('access_token' in result.keys() and 'scope' in result.keys()):
# 如果 SCOPE 是真且返回的 scope 中不包含 SCOPE,则抛出 DemoError 异常,描述为 scope 不正确
if SCOPE and (not SCOPE in result['scope'].split(' ')): # SCOPE = False 忽略检查
raise DemoError('scope 不正确')
# 打印令牌和过期时间(这行代码被注释掉,不会执行)
# print('SUCCESS WITH TOKEN: %s EXPIRES IN SECONDS: %s' % (result['access_token'], result['expires_in']))
# 返回 access_token
return result['access_token']
else:
# 如果返回结果中没有 access_token 或 scope,则抛出 DemoError 异常,描述为 API_KEY 或 SECRET_KEY 不正确
raise DemoError('可能 API_KEY或SECRET_KEY不正确:在令牌响应中没有找到access_token或范围')
""" TOKEN end """
# 定义一个名为AudioToText的类,没有继承其他类
class AudioToText():
# 定义一个名为audio_to_text的方法,接受两个参数:AUDIO_FILE和FORMAT
def audio_to_text(AUDIO_FILE, FORMAT):
# 调用fetch_token函数获取令牌token,具体实现未给出
token = fetch_token()
# 以二进制读取模式打开AUDIO_FILE
with open(AUDIO_FILE, 'rb') as speech_file:
# 读取文件内容
speech_data = speech_file.read()
# 计算文件长度
length = len(speech_data)
# 如果文件长度为0,抛出DemoError异常,描述文件为空
if length == 0:
raise DemoError('文件 %s 是个空文件' % AUDIO_FILE)
# 对读取的二进制数据进行base64编码
speech = base64.b64encode(speech_data)
# 将编码后的二进制数据转为utf-8格式的字符串
speech = str(speech, 'utf-8')
# 定义参数字典,包含各种参数如开发工具箱ID(DEV_PID),格式(FORMAT),速率(RATE),令牌(token),用户ID(CUID),通道(channel),语音数据(speech),语音长度(len)等
params = {'dev_pid': DEV_PID,
# "lm_id" : LM_ID, #测试自训练平台开启此项
'format': FORMAT,
'rate': RATE,
'token': token,
'cuid': CUID,
'channel': 1,
'speech': speech,
'len': length
}
# 将参数字典转为json字符串,不改变键值顺序
post_data = json.dumps(params, sort_keys=False)
# 打印post_data内容,这一行在代码中是注释,实际不会执行
# print post_data
# 创建一个新的请求对象,使用POST方法,请求的URL是ASR_URL,请求的内容是post_data编码后的数据,并且设置请求头的Content-Type为application/json
req = Request(ASR_URL, post_data.encode('utf-8'))
req.add_header('Content-Type', 'application/json')
try:
# 记录开始时间
begin = timer()
# 使用urlopen函数发送请求,返回一个文件对象,可以使用f.read()读取返回的内容
f = urlopen(req)
# 读取返回的内容
result_str = f.read()
# 打印请求花费的时间(从开始计时到读取完响应内容的时间)
# print("Request time cost %f" % (timer() - begin)) 这一行在代码中是注释,实际不会执行
except URLError as err:
# 如果出现网络错误(如网络连接中断、服务器异常等),打印错误代码和错误信息
print('请求错误 : ' + str(err.code))
result_str = err.read() # 读取错误的详细信息
# 将返回的字节流转为utf-8格式的字符串
result_str = str(result_str, 'utf-8')
# 以追加模式打开文件"./log/result.txt",写入响应的结果字符串
with open("./log/result.txt", "a", encoding="utf-8") as f:
f.write(result_str) # 将结果写入到文件中
# 将返回的json字符串转为python字典对象并赋值给变量data
data = json.loads(result_str)
return data # 返回解析后的数据
# 需要识别的文件
AUDIO_FILE = './audio/16k.wav' # 只支持 pcm/wav/amr 格式,极速版额外支持m4a 格式
# 文件格式
FORMAT = AUDIO_FILE[-3:] # 文件后缀只支持 pcm/wav/amr 格式,极速版额外支持m4a 格式
if __name__ == '__main__':
data = AudioToText.audio_to_text(AUDIO_FILE, FORMAT)
COLOR_GREEN = "\033[32m" #绿色
RESET = "\033[0m" #黑色
print(f"语音转文本结果:{COLOR_GREEN}{data['result'][0]}"+RESET)
4.测试

















 402
402











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











