







 本文记录了一次使用Python爬取58同城商品数据的经历,重点讲述了如何应对网站的反扒机制。作者在研究中发现,通过在HTTP Header中添加referer字段可以成功获取数据,揭示了在爬虫过程中注意cookie、referer和user-agent的重要性。
本文记录了一次使用Python爬取58同城商品数据的经历,重点讲述了如何应对网站的反扒机制。作者在研究中发现,通过在HTTP Header中添加referer字段可以成功获取数据,揭示了在爬虫过程中注意cookie、referer和user-agent的重要性。
python实战第一周大作业:爬取一页商品数据。
直接上运行结果如图:
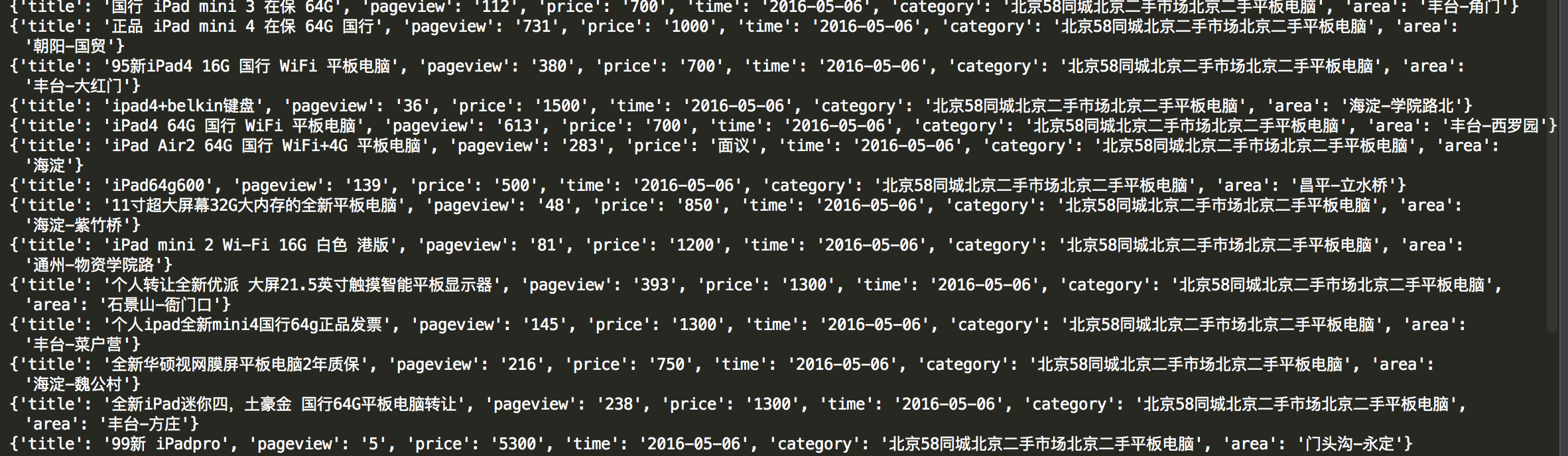
代码如下:
from bs4 import BeautifulSoup
import requests
import time
url = 'http://bj.58.com/pbdn/0/'
#入口函数
def get_url(url):
web_data = requests.get(url)
soup = BeautifulSoup(web_data.text,'lxml')
links = get_links(soup.select('td.t > a'))
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 8985
8985

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









