






在大模型训练中,数据分析是确保模型性能和训练效率的关键步骤。通过对训练数据进行全面的分析,可以发现潜在的问题和优化空间,提高模型的整体效果。以下是数据分析过程中需要重点关注的方面及其要点:
- 数据质量
- 准确性:检查数据是否有错误、错别字或不正确的标签。错误的数据会误导模型学习,降低其准确性。
- 完整性:确保数据集的完整性,避免缺失值或不完整的样本。缺失数据可能导致训练偏差。
- 数据分布
- 类别分布:分析分类任务中的类别分布,确保数据集中的类别分布均衡。如果类别不均衡,模型可能会偏向多数类别。
- 特征分布:对于回归或其他任务,检查特征的分布情况,确保没有异常值或过度偏斜的分布。
- 数据多样性
- 文本多样性:在NLP任务中,检查文本的多样性,包括词汇、句法结构和主题。多样性高的数据集有助于提高模型的泛化能力。
- 样本多样性:确保数据集中包含足够多样的样本,以覆盖不同的场景和情况。
- 文本长度
- 长度分布:分析文本长度的分布情况,确定合适的最大长度和最小长度。这有助于设定模型输入的最大序列长度,优化资源使用。
- 截断和填充:研究需要截断和填充的样本比例,确保截断和填充策略不会显著影响数据质量。
- 数据预处理
- 清洗和标准化:对数据进行必要的清洗和标准化处理,如去除噪声、统一格式和处理特殊字符。
- 去重:检查并去除重复的样本,避免模型在重复数据上过度拟合。
观察发现,QA数据集中有空格、“答:”、乱码等不需要的字样,于是进行处理。
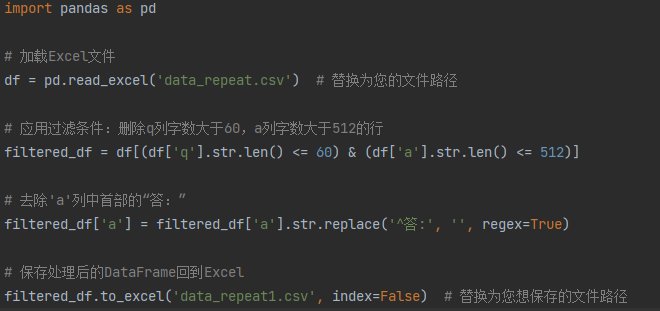
通过上述模版代码,去除了数据集中"答:"的字样,然后如法炮制,将空格和乱码都进行了去除和清洗。清理完后的部分数据如下图。

可以观察到,数据的结构比较清晰,q列是问题,a列是答案,并且数据中的空格、乱码等已经被去除。
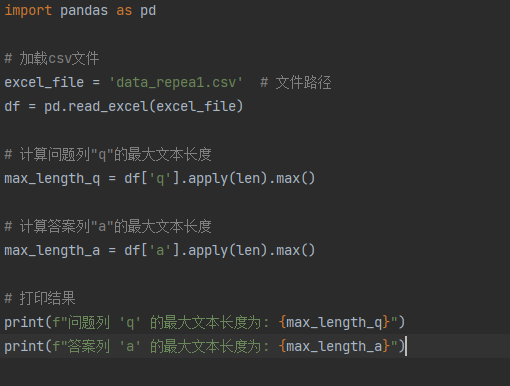
下面我进行了数据分析,主要是分析了文本长度。文本长度在大模型训练中很重要,主要有以下几点。
-
丰富的上下文:较长的文本通常包含更多的信息和上下文,有助于模型理解复杂的语义关系和捕捉长距离依赖。
-
过长文本的挑战:处理过长的文本可能导致模型过拟合或者捕捉到过多无关信息,反而可能降低模型性能。需要找到一个平衡点,既包含足够的信息,又不过多冗余。
-
最大长度设定:在训练过程中,通常会设定一个最大文本长度,超过该长度的文本会被截断。这种策略需要权衡信息完整性和计算资源。
-
任务特定需求:不同任务对文本长度的需求不同。例如,句子分类任务可能不需要很长的文本,而文档摘要生成则需要处理更长的文本。
-
微调阶段:在微调阶段,根据具体任务调整文本长度,可以优化模型性能和资源利用效率。
分析文本长度的代码如下。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









