






因为个人疏忽,之前的个人周报都上传到了个人博客:https://srj2003.top/,现在整合过来。
项目实训个人周报4.14
我们组的项目是基于大模型的知识问答教育系统,我在前期的任务是数据采集和处理清洗,以便于构建数据集训练大模型。
基于调查研究,我对于数据收集的关键点做出了以下归纳。
-
准确性:确保数据来源可靠,内容准确无误。错误的信息会导致模型输出错误答案,影响用户体验和教育效果。
-
更新性:确保数据是最新的,特别是对于动态变化的领域,如科技、法律等。
-
教育层次:覆盖从基础教育到高等教育的内容,适应不同学习阶段的用户需求。
-
结构化数据:优先选择结构化数据(如数据库、表格),便于处理和分析。
-
隐私保护:确保用户数据的匿名化处理,避免泄露个人信息。
-
合规性:遵守数据保护法律法规,如GDPR等,确保数据收集和使用过程中的合法合规性。
在开始的时候,我准备从百度百科、csdn等知识网站上收集数据,但是我发现这些网站上的数据质量良莠不齐,有的甚至有常识性错误,难以在爬取的时候进行分辨;并且这些数据的格式不一致,在后期处理的时候会造成麻烦,于是放弃。
然后我找到了Hugging Face 的 Datasets 库,这个库提供了大量预构建的数据集,涵盖了广泛的任务和领域,包括文本分类、情感分析、机器翻译、问答、对话系统等。这些数据集经过整理和优化,便于用户直接使用。这个库还可以通过简单的 API 调用轻松下载和加载数据集,无需手动下载和处理数据文件,比较方便。
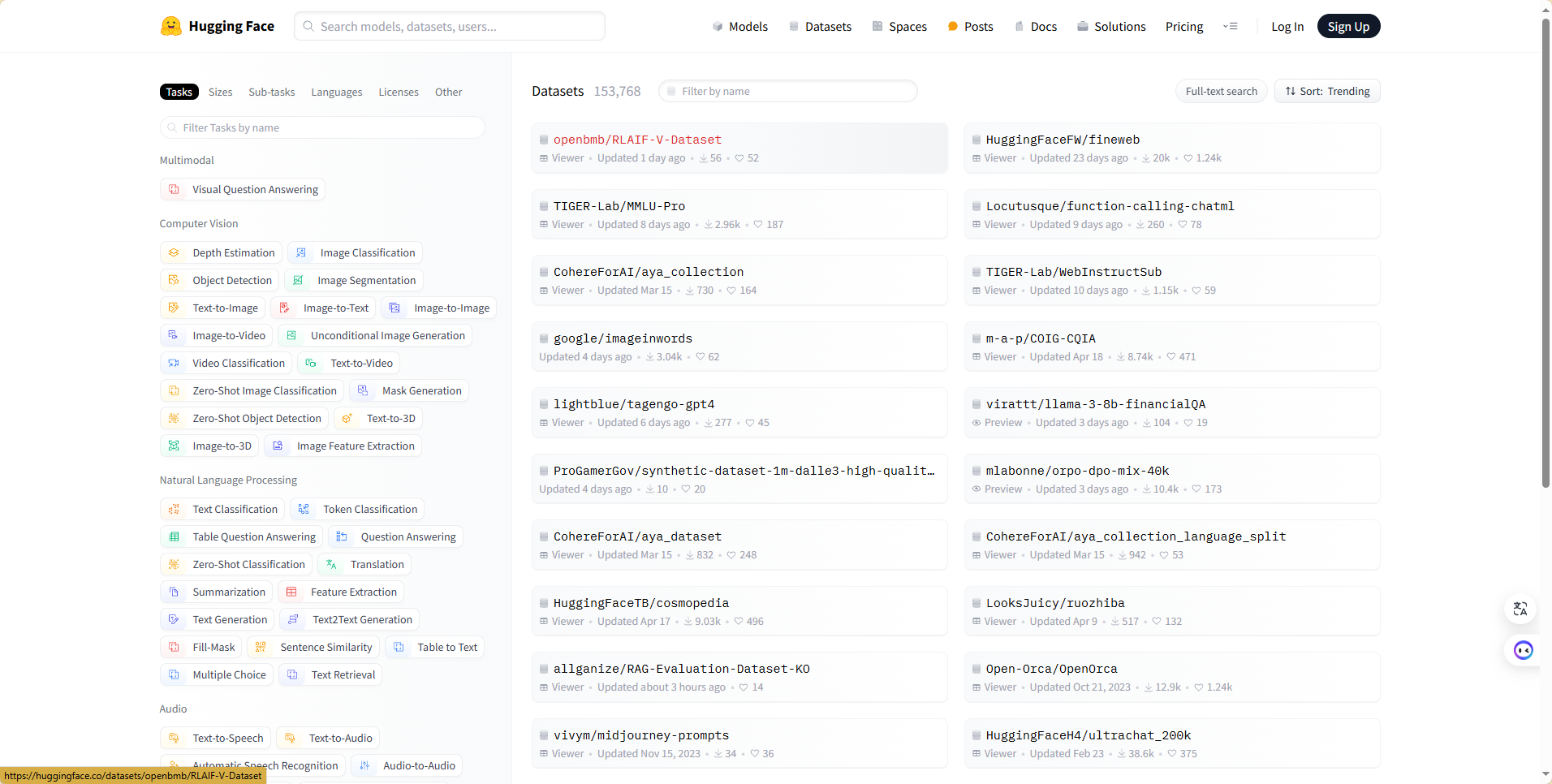
于是我决定在这里进行数据的收集。因为我们的项目是问答系统,所以我筛选了可能用得到的QA数据集。以下是我认为能用到的数据集,供给大模型训练。
医疗:https://huggingface.co/datasets/lavita/medical-qa-datasets?row=15
https://huggingface.co/datasets/blinoff/medical_qa_ru_data?row=7
https://huggingface.co/datasets/medalpaca/medical_meadow_medqa
中医:https://huggingface.co/datasets/FreedomIntelligence/huatuo_knowledge_graph_qa
https://huggingface.co/datasets/FreedomIntelligence/huatuo_encyclopedia_qa/viewer/default/train?p=3624&row=362400
中文综合:https://huggingface.co/datasets/m-a-p/COIG-CQIA
博客节目:https://huggingface.co/datasets/wavpub/JinJinLeDao_QA_Dataset
哲学:https://huggingface.co/datasets/sayhan/strix-philosophy-qa/viewer/default/train?p=1337&row=133777
心理健康:https://huggingface.co/datasets/Amod/mental_health_counseling_conversations?row=7
小学数学:https://huggingface.co/datasets/microsoft/orca-math-word-problems-200k
计算机相关
数学:https://huggingface.co/datasets/math-ai/StackMathQA
python编程:https://huggingface.co/datasets/lucasmccabe-lmi/codex_math_qa_alpaca_style/viewer/default/train?p=280&row=28004
https://huggingface.co/datasets/flytech/python-codes-25k
sql编程:https://huggingface.co/datasets/b-mc2/sql-create-context
代码指令:https://huggingface.co/datasets/m-a-p/CodeFeedback-Filtered-Instruction?row=38
https://huggingface.co/datasets/m-a-p/Code-Feedback/viewer/default/train?p=663&row=66310
论文NLP:https://huggingface.co/datasets/allenai/qasper?row=0
stackExchange:https://huggingface.co/datasets/lvwerra/stack-exchange-paired?row=16
综合包括computer science:https://huggingface.co/datasets/MMMU/MMMU/viewer/Computer_Science/test?row=2
https://huggingface.co/datasets/cais/mmlu/viewer/college_computer_science?row=29
https://huggingface.co/datasets/ikala/tmmluplus/viewer/computer_science/test
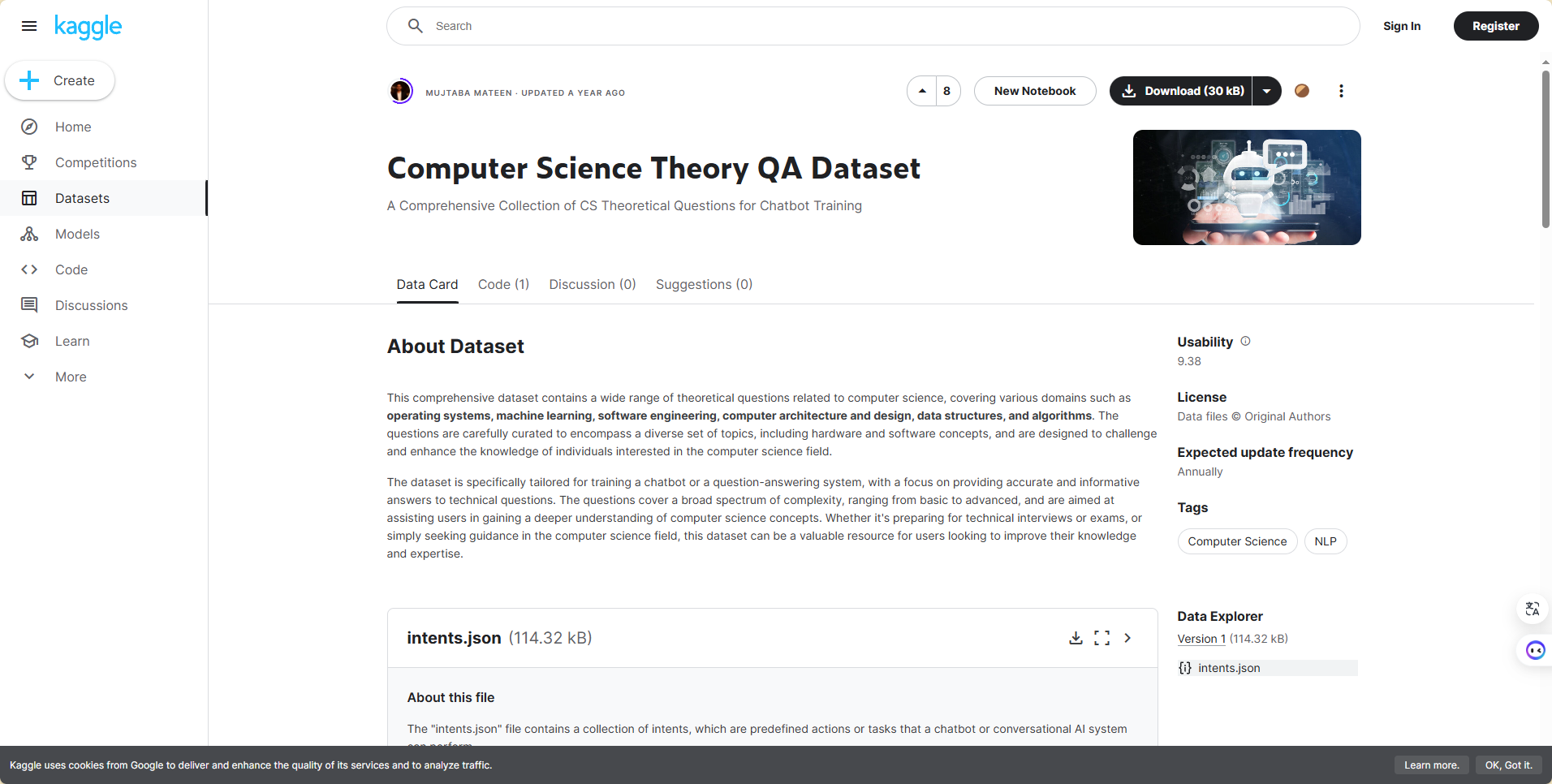
然后我在kaggle网站上找到了一个与我们项目适配程度较大的数据集,是关于计算机理论知识的问答集:
https://www.kaggle.com/datasets/mujtabamatin/computer-science-theory-qa-dataset
结合做大模型相关工作的同学的反馈,我选取了上述中的几个数据集,整理成了csv文件,以便于后续的数据清洗等工作。
项目实训个人周报4.23
在大模型训练中,数据分析是确保模型性能和训练效率的关键步骤。通过对训练数据进行全面的分析,可以发现潜在的问题和优化空间,提高模型的整体效果。以下是数据分析过程中需要重点关注的方面及其要点:
- 数据质量
- 准确性:检查数据是否有错误、错别字或不正确的标签。错误的数据会误导模型学习,降低其准确性。
- 完整性:确保数据集的完整性,避免缺失值或不完整的样本。缺失数据可能导致训练偏差。
- 数据分布
- 类别分布:分析分类任务中的类别分布,确保数据集中的类别分布均衡。如果类别不均衡,模型可能会偏向多数类别。
- 特征分布:对于回归或其他任务,检查特征的分布情况,确保没有异常值或过度偏斜的分布。
- 数据多样性
- 文本多样性:在NLP任务中,检查文本的多样性,包括词汇、句法结构和主题。多样性高的数据集有助于提高模型的泛化能力。
- 样本多样性:确保数据集中包含足够多样的样本,以覆盖不同的场景和情况。
- 文本长度
- 长度分布:分析文本长度的分布情况,确定合适的最大长度和最小长度。这有助于设定模型输入的最大序列长度,优化资源使用。
- 截断和填充:研究需要截断和填充的样本比例,确保截断和填充策略不会显著影响数据质量。
- 数据预处理
- 清洗和标准化:对数据进行必要的清洗和标准化处理,如去除噪声、统一格式和处理特殊字符。
- 去重:检查并去除重复的样本,避免模型在重复数据上过度拟合。
观察发现,QA数据集中有空格、“答:”、乱码等不需要的字样,于是进行处理。
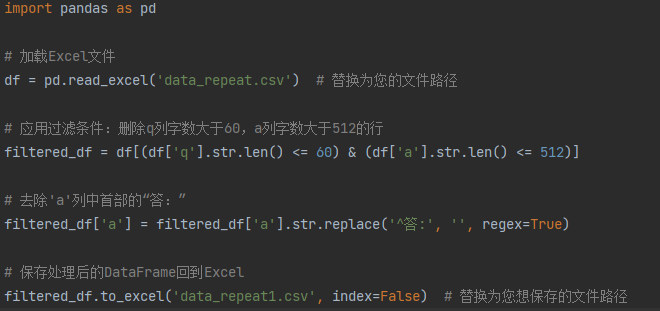
通过上述模版代码,去除了数据集中"答:"的字样,然后如法炮制,将空格和乱码都进行了去除和清洗。清理完后的部分数据如下图。

可以观察到,数据的结构比较清晰,q列是问题,a列是答案,并且数据中的空格、乱码等已经被去除。
下面我进行了数据分析,主要是分析了文本长度。文本长度在大模型训练中很重要,主要有以下几点。
-
丰富的上下文:较长的文本通常包含更多的信息和上下文,有助于模型理解复杂的语义关系和捕捉长距离依赖。
-
过长文本的挑战:处理过长的文本可能导致模型过拟合或者捕捉到过多无关信息,反而可能降低模型性能。需要找到一个平衡点,既包含足够的信息,又不过多冗余。
-
最大长度设定:在训练过程中,通常会设定一个最大文本长度,超过该长度的文本会被截断。这种策略需要权衡信息完整性和计算资源。
-
任务特定需求:不同任务对文本长度的需求不同。例如,句子分类任务可能不需要很长的文本,而文档摘要生成则需要处理更长的文本。
-
微调阶段:在微调阶段,根据具体任务调整文本长度,可以优化模型性能和资源利用效率。
分析文本长度的代码如下。
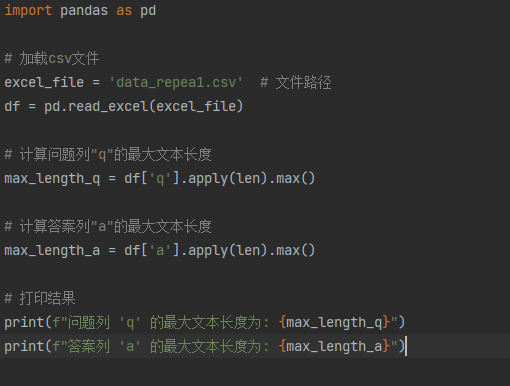
项目实训个人周报5.6
在大模型训练中,数据集划分、数据增强和数据可视化是至关重要的步骤,确保模型训练的有效性、可靠性和可解释性。下面是对这三个方面的具体实现方法的详细说明。
数据集划分:合理划分训练、验证和测试集
-
比例划分:
常用的划分比例是70%用于训练,15%用于验证,15%用于测试。具体比例可以根据数据集的规模和任务的需求进行调整。
-
随机划分:
使用随机数生成器确保数据集划分的随机性,避免样本顺序导致的偏差。
-
分层抽样:
在分类任务中,确保各类样本在训练、验证和测试集中的比例一致,可以使用分层抽样。
-
时间序列数据划分:
在时间序列数据中,按照时间顺序划分数据,确保训练集早于验证集,验证集早于测试集。
这里我使用随机划分,使用sklearn.model_selection.train_test_split函数实现:
from sklearn.model_selection import train_test_split
train_data, test_data = train_test_split(data, test_size=0.3, random_state=42)
train_data, val_data = train_test_split(train_data, test_size=0.2, random_state=42)
数据增强:同义词替换、回译、随机删除
1.同义词替换
随机选择句子中的词,替换为其同义词。
这里我使用NLTK实现:
from nltk.corpus import wordnet
def synonym_replacement(text):
words = text.split()
new_words = words.copy()
for i in range(len(words)):
synonyms = wordnet.synsets(words[i])
if synonyms:
new_words[i] = synonyms[0].lemmas()[0].name()
return ' '.join(new_words)
2.回译:
将文本翻译成另一种语言,再翻译回来,以生成新的文本。
我这里使用谷歌的翻译API(Google Translate API)实现:
from googletrans import Translator
def back_translation(text, src='en', dest='de'):
translator = Translator()
translated = translator.translate(text, src=src, dest=dest).text
back_translated = translator.translate(translated, src=dest, dest=src).text
return back_translated
3.随机删除:
随机删除句子中的一些词,生成新的变体。
实现如下:
import random
def random_deletion(text, p=0.1):
words = text.split()
if len(words) == 1:
return text
new_words = [word for word in words if random.uniform(0, 1) > p]
return ' '.join(new_words)
数据可视化:文本数据可视化
词频统计:使用词云(Word Cloud)展示高频词。
from wordcloud import WordCloud
import matplotlib.pyplot as plt
def plot_wordcloud(text):
wordcloud = WordCloud(width=800, height=400).generate(text)
plt.figure(figsize=(10, 5))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.show()
项目实训个人周报5.19
前面从广义数据的角度对数据集进行了处理,但是没有考虑到大模型的角度。在和负责大模型部分的同学沟通后,进一步对数据进行了处理,使其更贴合大规模预训练模型。通过一番查找对比,我在这里选择了llm_corpus_quality这个项目。
llm_corpus_quality集成了包含清洗、敏感词过滤、广告词过滤、语料质量自动评估等功能在内的多个数据处理工具与算法,为中文AI大模型提供安全可信的主流数据。项目采用java实现,完整项目见https://github.com/jiangnanboy/llm_corpus_quality
llm_corpus_quality支持以下特性:
- 规则清洗
- 敏感词过滤
- 广告过滤
- 去重
- 质量评估
处理流程如下
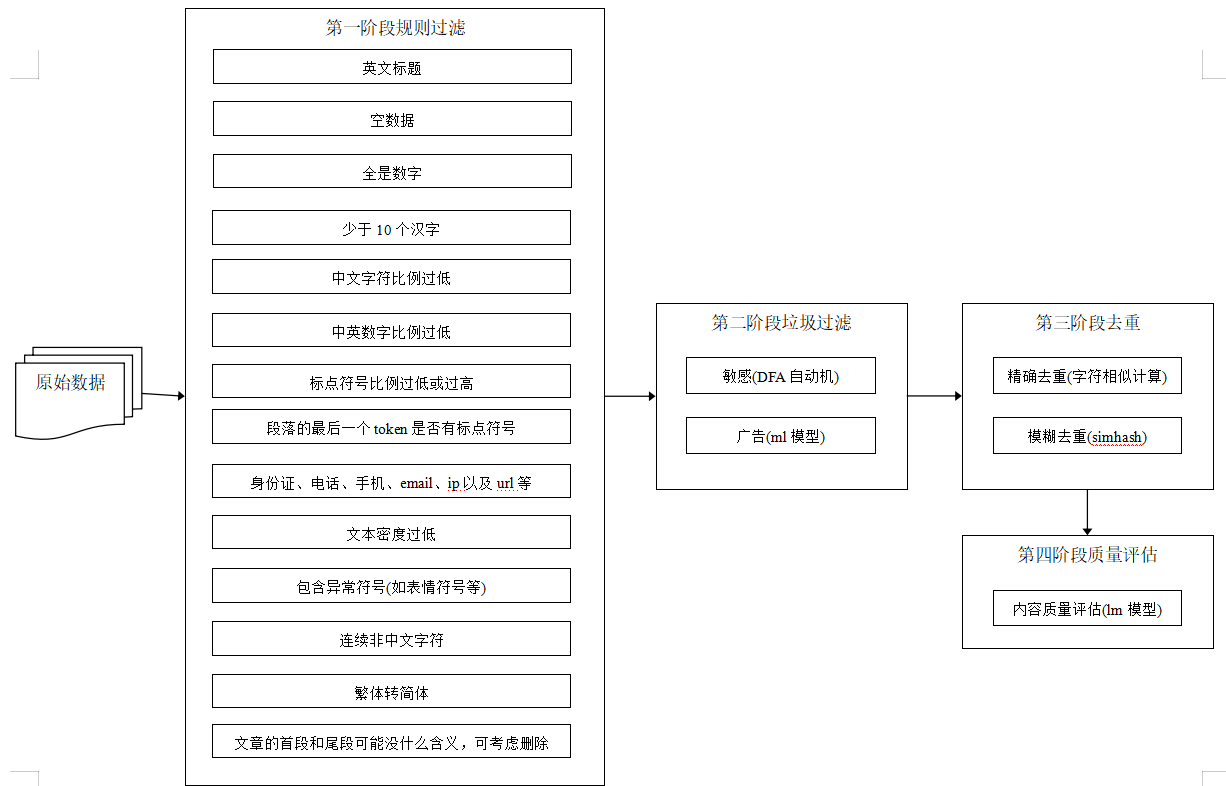
大模型训练语料清洗流程,共包括4个阶段5个模块:
- 语料清洗规则过滤:通常经过格式转换后的json文件仍存在很多问题,不能直接用于构建训练数据集。通常会以句子或篇章作为过滤单位,通过检测句子或篇章内是否含有大量的怪异符号、是否存在html网页标签等来判断文本是否为合格文本。
- 敏感词过滤器:利用自动机,过滤色情、赌博、部分低质量广告等内容的文本。
- 广告过滤:利用textcnn模型,过滤涉嫌广告内容。(见https://github.com/jiangnanboy/ad_detect_textcnn)
- 去重:利用simhash对相似文本片段进行去重。
- 质量评估:采用ngram语言模型评估的方法,对语料进行概率预估,文本质量越高的语句,困惑度ppl越低,设定一个ppl阈值,高于这个阈值为低质量语料,可过滤。
下面是作者给出的示例代码,我稍加改动,对预处理的数据集进行了适配大模型的清洗,得到了最终数据集。
// hash data of corpus to deduplication (read and save)
var hashFile = PropertiesReader.get("dedeplication_hash_path");
//1.rule
var ruleQuality = new RuleQuality();
//2.sensitivity and advertising detection
var simpleSenDetectionProcessor = SimpleSenDetectionProcessor.newInstance();
var senDetection = simpleSenDetectionProcessor.getKWSeeker("sensitive_words_path");
var ad_detect_model_path = PropertiesReader.get("ad_detect_model_path");
var ad_dict_path = PropertiesReader.get("ad_dict_path");
var stop_words_path = PropertiesReader.get("stop_words_path");
var adDetection = new AdDetection(ad_detect_model_path, ad_dict_path, stop_words_path);
//3.text deduplication
var deDuplication = new DeDuplication(4, 3);
//4.quality evaluation
var ngramModelPath = PropertiesReader.get("language_model_path");
var qualityEvaluation = new QualityEvaluation(ngramModelPath);
// load hash
if(Files.exists(Paths.get(hashFile))) {
deDuplication.loadHash(hashFile);
}
var corpusQuality = new CorpusQuality(ruleQuality, senDetection, adDetection, deDuplication, qualityEvaluation, 100);
var corpus = "对未按土地、环保和投资管理等法律法规履行相关手续或手续不符合规定的违规项目,地方政府要按照要求进行全面清理。一,凡是未开工的违规项目,一律不得开工建设;二,凡是不符合产业政策、准入标准、环保要求的违规项目一律停建。";
var result = corpusQuality.quality(corpus);
System.out.println(result);
// save hash
deDuplication.saveHash(hashFile);
不过在这里,我对清洗前后的数据进行观察,发现并没有明显变化,因为原本的数据集已经是在上传者处理过后上传至平台上的。















 669
669

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









