







Python requests30行代码爬取知乎一个问题的所有回答
之前学习了Python的requests爬虫一直想找机会自己练习下,正好作为一个大学生平时知乎看的也不少,那就爬取知乎吧,先上源码和效果图(我找的是随便一个热门问题,你讨厌的LOL主播是什么,总共1911个回答)
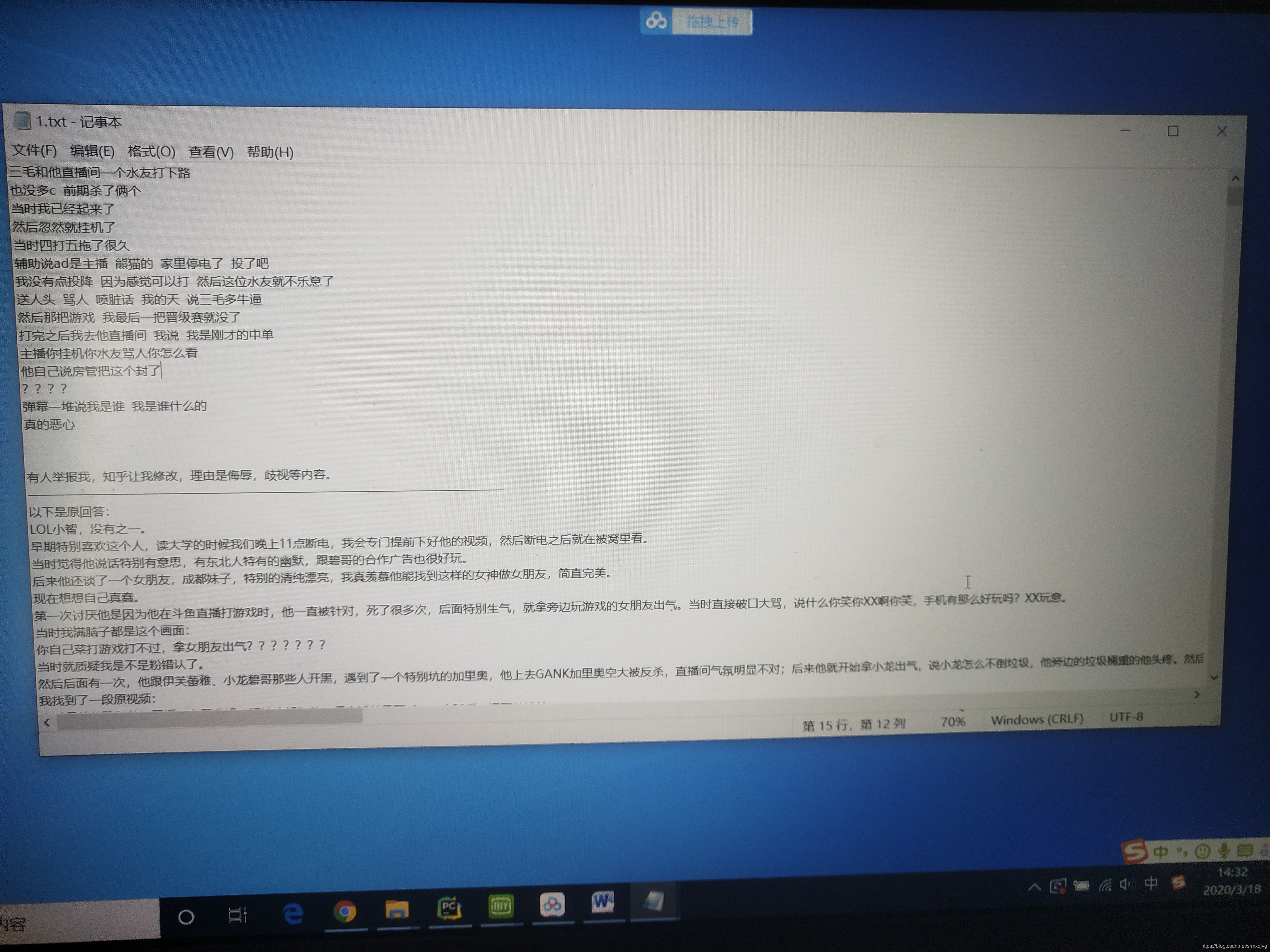
可以看到记事本里面的东西特别多啊,差不多有超级多的答案
好了,说思路了
本来以为知乎需要模拟登录才能爬取,后来发现不需要
直接在network中找到answer,访问那个url就可以了
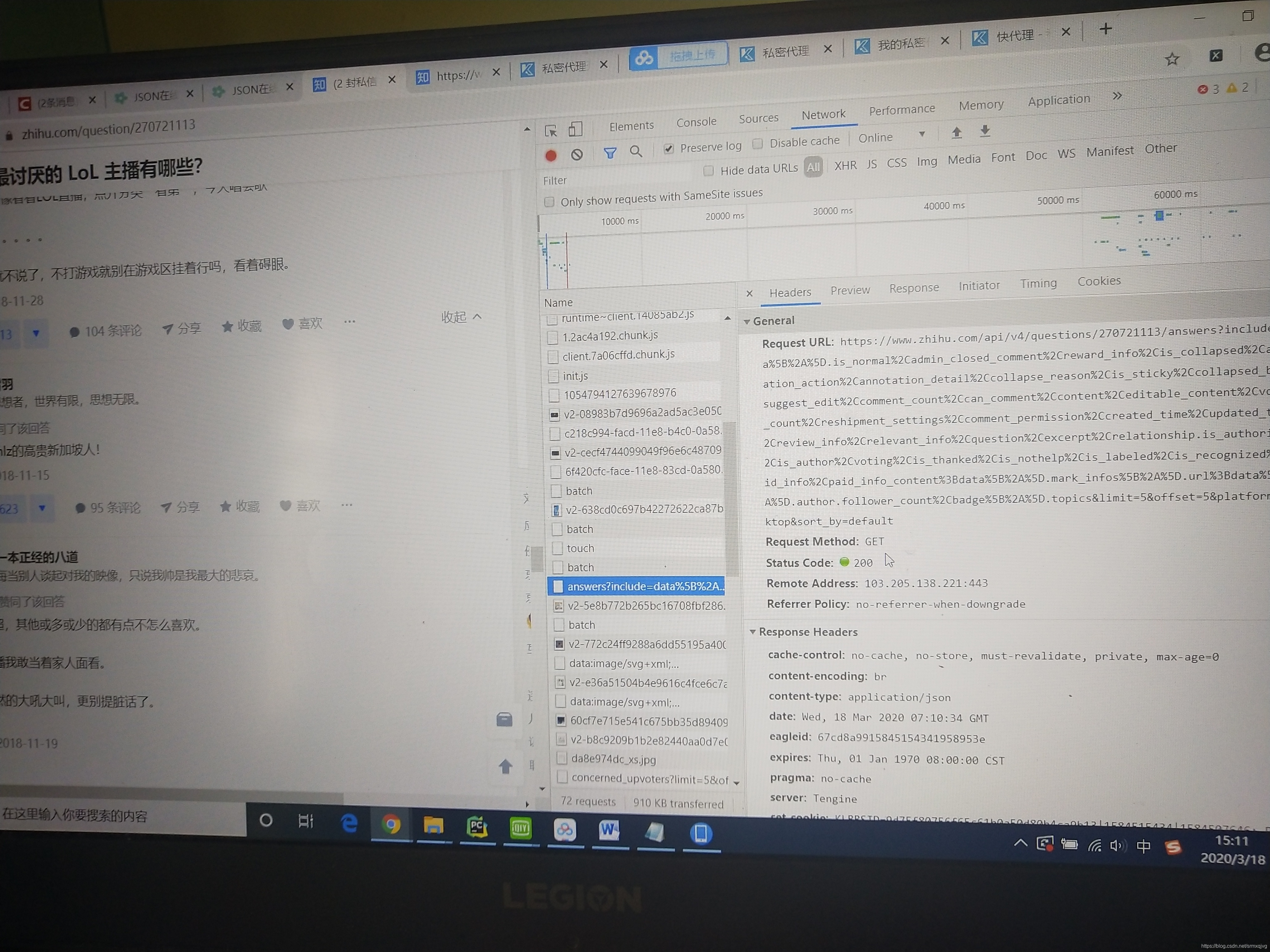
知乎上的问题答案肯定不是在页面上直接有的,也就是说检查网页源代码是出不来的,不能直接爬取,应该是一个ajax请求的类型
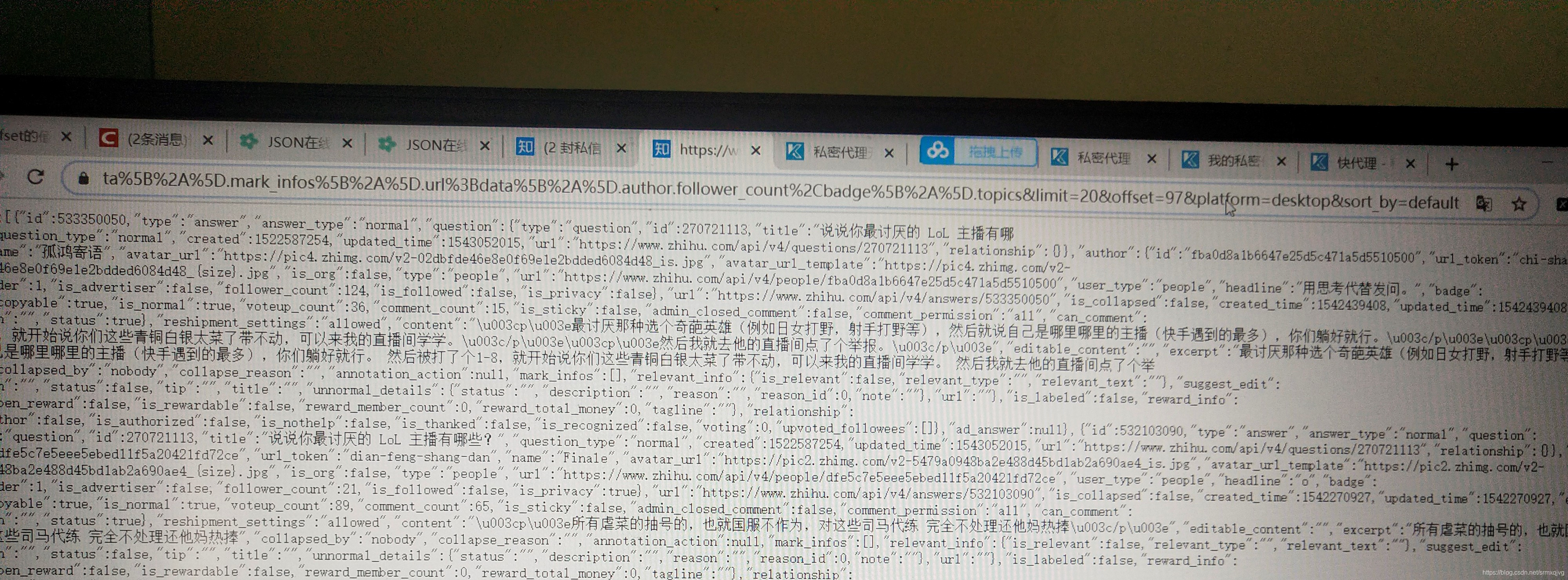
可以改里面limit的值,注意不能太大,意思是一次请求多少个回答下来,好像默认是5,我改的20,offset的值意思是第几页
明显是一个json符串,里面是有回答的
先随便找一个json解析的网站解析一下
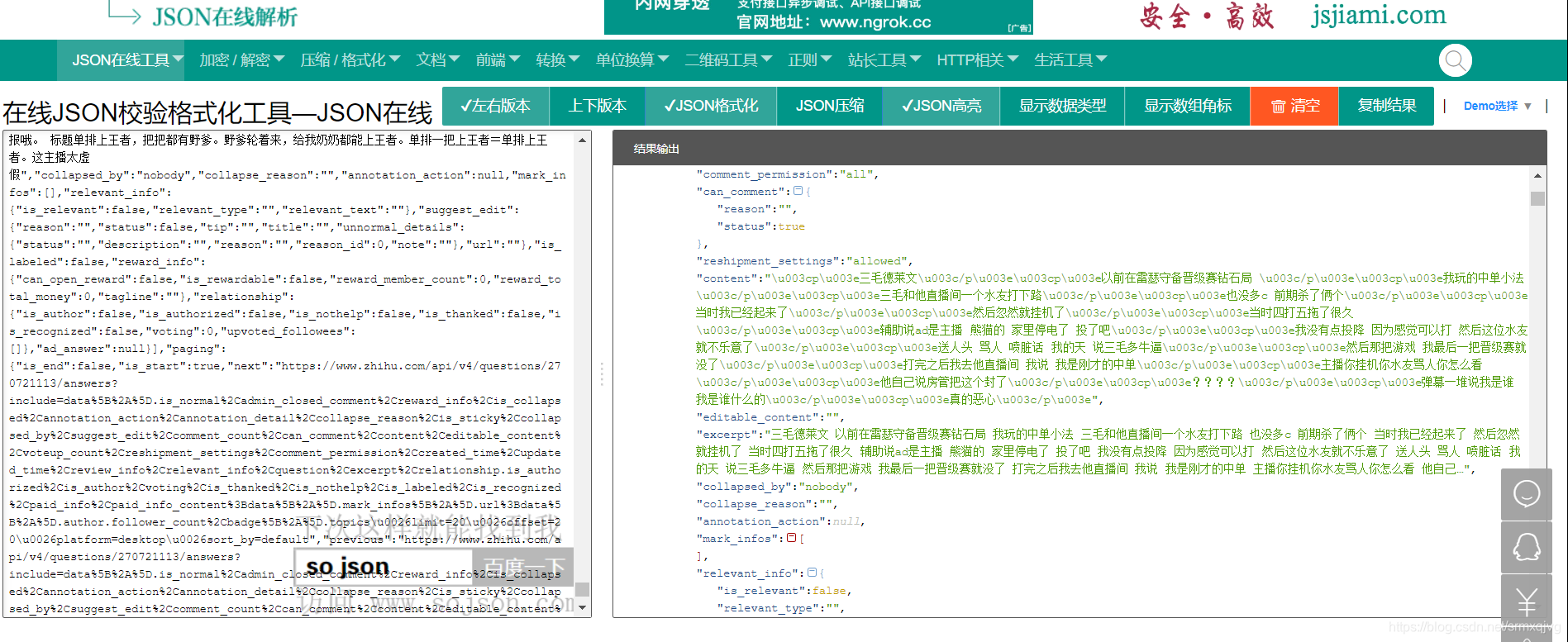
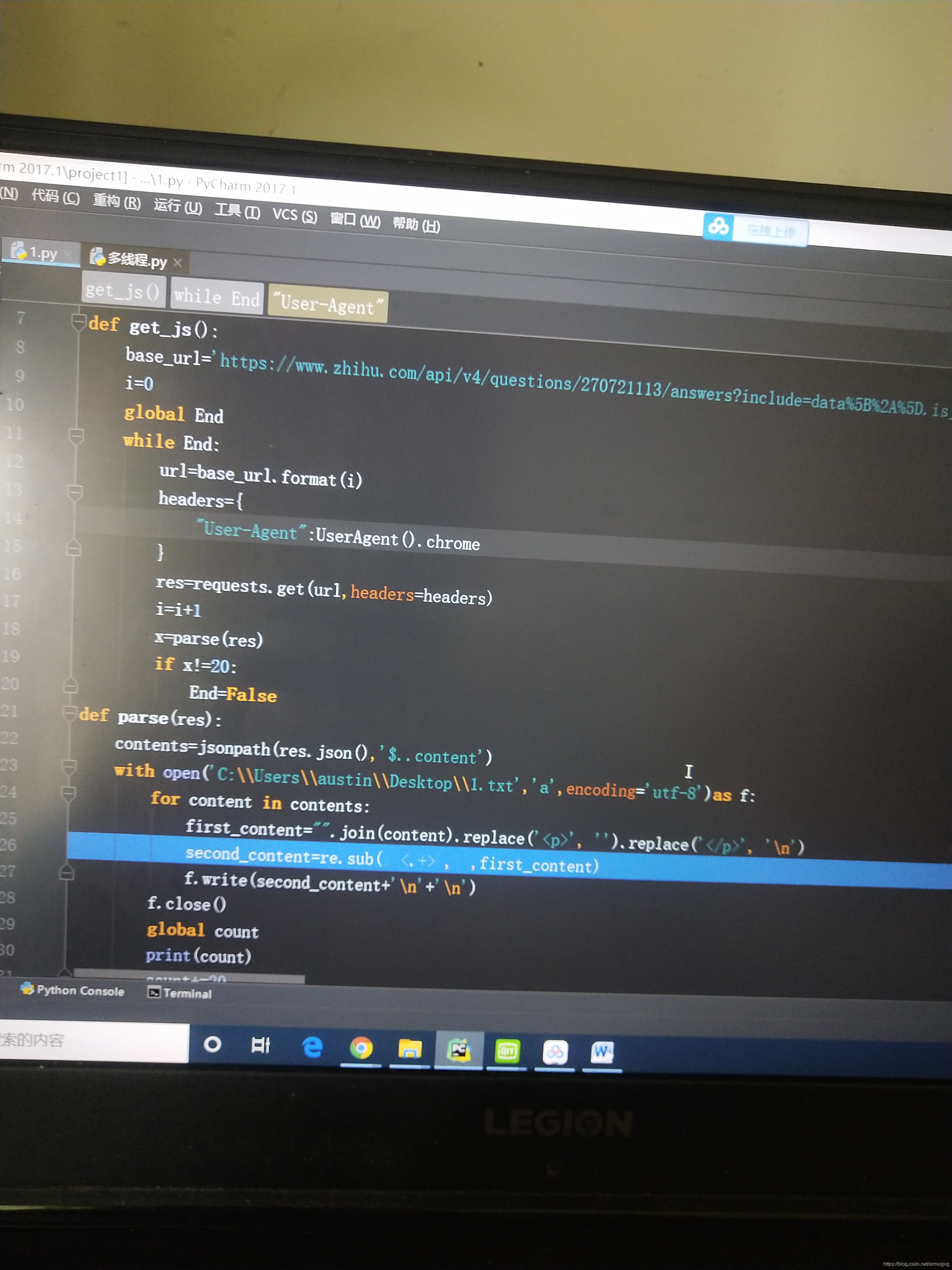
看出内容在content里面,在python中引入jsonpath解析

我这里用的是正则加jsonpath,正则作用是是把那些html标签什么乱七八糟的去掉 然后写入文件中就完事
后记:offset还是有点搞不太懂,我试了把offset改到100000还是有回答,也就是说我的while true判断条件是错的,实际运行的时候一直不停止,肯定是有重复回答的
还有就是这种问题的回答也没什么价值,没有用任何代理,没有设置任何间隔时间就爬取下来了,哈哈哈
欢迎大家一起来探讨## 标题















 830
830











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









