







总算来到了最为期待的一张,旁边总是有人会告诉你,这个用树很简单,这个用树都不用做,然而今天我也开始了树,不是每个人都没有权利去追赶,而是你有没有不服输的心没人可以有资格看不起你,没有一个人有资格站在神坛告诉你不行,更何况,你身边的人?站的真的是神坛吗??
言归正传:
对于树我们先给他一个定义:
1.一棵树有任意两个节点有且仅有唯一的一条路径连通。
2.一棵树有n个结点,那么它一定恰好有n-1条边。
3.在一棵树中加一条边可以构成一个回路。
首先树是指任意两个结点间有且只有一条路径无向图。或者说只要是没有没有任何回路的连通图就是树。
为了确定没一个数的形态,在树中我们可以指定一个特殊的结点———根。我们在对任意一棵数进行讨论的时候,将树中的每个点称为结点或者叫节点,且一个点又有很多分结点,我们把这个点叫做父结点其他与其直接相连的点叫做子节点,所以同常一个树会由许多的父节点和子节点,而且大部分的点不仅仅是一种,而是父与子的集合,这就构成了一个类似与家族族谱一样的东西,而最上面的那个我们称其为祖先。就这么点破东西,还打着么多,浪费脑子。
现在开始的才算是正常的学习了:
- 二叉树
二叉树是一种特殊的树,我们给其一个严格的定义:二叉树要么为空,要么由根左子树和右子树组成,而左子树和右子树分别是一棵二叉树。
二叉树分为满二叉树和完全二叉树,满二叉树是一个深度为h,且有2的h次方-1个结点的二叉树。
如果一棵二叉树除了最右边的位置有一个或者几个叶结缺少外,其他是丰满的,那么这样的二叉树就是完全二叉树,更为严格的定义是:若设二叉树的高度为h除了第h层外,其他各层结点数都能达到最大个数,第h层从右向左联系缺若干结点。则这个二叉树就是完全二叉树,也就是说如果结点有右子节点,那么它一定有左子节点,其实可以将满二叉树理解成一种特殊的或者极其完美的完全二叉树
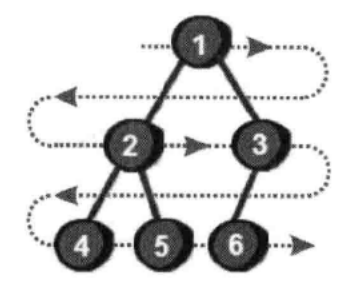
通过上图我么发现,如果完全二叉树的一个父节点编号为k,那么它左儿子的编号就是2*k,右儿子的编号就是2*k+1。如果一直儿子的编号是x,那么他父节点一定是x/2,注意,这里只求整数部分,即自动向下取整(C++就是这样),且如果一个完全二叉树有n个结点,那么这个完全二叉树的高度为log2 N(log以二为底N的对数,打不出来),简写为logN,即最多有logN层节点。
2.堆
堆是神马?堆就是一种特殊的二叉树,他们保持着某种特性,例如每个父节点比子节点小,我们就叫其为小顶堆,同时还有大顶堆,定义你肯定懂了哈。
这个有什么用呢?假设我们现在有一堆数,我们要找到其中的最小数,这很简单,一个循环可以解决,我们要是需要删除这个最小数并且再加入一个新数,再次求里面的最小数,那只能在重新扫描,假如每个都要来一遍呢?此时这个特殊的结构”堆”就可以解决这个问题。
首先我们按照最小对的要求将这些数放入一棵完全二叉树中。
然后我们开始替换,把替换后的值与下面的两个儿子比较,选择较小的一个与之交换。
然后继续向下交换,直到符合最小堆的特性为止。
向下调整的代码如下:
void sifedown(int i)//传入向下调整的结点编号i
{ //向下调整
int,t,flag=0;//flag标记是否需要向下调整
//当i结点有儿子(至少是有做儿子的情况下)并且有需要继续调整的时候,循环就执行
while(i*2<=n && flag=0)
{
if(h[i] > h[i*2]
t=i*2;
else
t=i;
//如果有右儿子我们在对右儿子进行讨论
if(i*2+1 <= n)
{
//如果右儿子的值更小,更新较小的结点编号
if( h[t] > h[i*2+1])
t=i*2+1;
}
//如果发现最小的结点编号不是自己,说明子节点有比父节点更小的
if(t!=i)
{
swap(t,i);交换他们,注意swap函数需要自己来写
i=t;//更新i为刚才与它交换的儿子结点编号,便于接下来继续向下调整。
}
else
flag=1;
}
return ;
}
现在时间复杂度恰好变为了logN,我们可以设一个数据,现在有一亿个数,,进行一亿次删除最小数并增加一个数的操作,原来大约要允许一亿的平方次,而现在只需要11一亿log一亿次,即27亿次在哟哟哟,假设计算机每秒运行10亿次,原来的方法要运行115天!而现在的我们只需要2,7秒,是不是很神奇?再次感受到了算法的伟大吧。
说到这里,如果我们想新增一个数,而不是删除最小值怎么办呢?其实只需要直接将新元素插入到末尾,再根据情况判断新元素是否需要上移,直到其满足了堆的特性为止。
我们每次让其与其父节点比较,为了维护最小堆的特性,我们让其父与其交换,重复循环,直至满足了最小堆的特性为止。
向上调整代码如下:
void siftup(int i)//传入向上调整的编号
{
int,flag=0;//用来标记是否需要向上调整,
if(i==1) return;//如果已经到了堆顶就不需要调整了
while(i!=1 && flag==0)//只有不在堆顶,并且当前结点i的值比父节点小的时候就继续调整。
{
//判断是否比父节点的小
if(h[i]<h[i/2])
swap(i,i/2);//交换它和它爸爸的位置。
else
flag=1;//表示不需要调整了,当前节点的值比父节点的值要大
i=i/2;//这句话很重要,更新编号i为它父节点的编号,从而便于下一次继续向上调整
}
return;
}到了现在,我们却忽略了一个很重要的问题,该如何定义堆呢?
每次插入一个对,然后升就好,代码如下:
n=0;
for(i=1;i<=m;i++)
{
n++;
h[n]=a[i];//或者是scanf("%d",&h[n]);
siftup(n);
}但其实还有更为简单的方法,我们先把所有数据延1-n自行编号,在这棵完全二叉树中,我们从最后一个结点开始,依次判断以这个结点为根的子树是否符合最小堆的特性,如果所有的子树都符合最小堆的特性,那么整棵就是最小堆了。
我们从最后一个非叶节点开始遍历即n/2每次使其向下调整。然后直至顶点,再回过头来从上面将本来在顶部的向下移动到底部,也许你会认为这个叙述在代码里难以实现,但实际上,这个代码却只有两行for(i=n/2;i>=1;i--) siftdown(i);用这种方法我们设立的堆的时间复杂度为O(N),
堆还有一个作用是堆排序,与快排一样,堆排序的时间复杂度也是NlogN比如我们现在要从小到大排序可以先建立最小堆,然后每次删除顶部元素将顶部元素输出或者放入到一个新的数组里,直到堆为空位置,
完整代码如下:
#include<stdio.h>
int h[101];//用来存放堆的个数
int n;//用来存储堆中的元素的个数,也就是堆的大小
//交换函数,交换堆中的两个元素的值。
void swap(int x, int y)
{
int t;
t=h[x];
h[x]=h[y];
h[y]=t;
return;
}
//向下调整函数
void siftdown(int i)
{//传入一个需要向下调整的结点编号i,这里传入1,即从堆顶开始向下调整
int t,flag=0;//flag标记是否向下调整
//当i结点有儿子(其实是至少有左儿子)并且有需要继续调整的时候就循环执行
while( i*2<=n && flag=0)
{//判断他和左儿子的关系,用t记录值较小的结点编号
if( h[i] > h[i*2})
t=i*2;
else
t=i;
//如果它有右儿子,再对右儿子进行讨论
if(i*2+1<=n)
{
//如果右儿子的值更小则更新较小的结点编号
if(h[t]>h[i*2+1])
T=I*2+1;
}
如果发现最小的节点编号不是自己,说明子结点中有比父结点更小的
if(t!=i)
{
swap(t,i);//交换他们
i=t;//更新i为刚才与它交换的儿子结点的编号,便于接下来继续向下调整。
}
else
flag=1;//否则说明当前的的父节点已经比两个子结都小了,不需要再调整了
}
return;
}
void cteat()
{
int i;//从最后一个非叶结点到第一个结点一次进行向下调整
for(i=n/2;i>=1;i--)
{
siftdown(i);
}
return;
}
删除最大的元素
int deletemax()
{
int t;用一个临时变量来记录堆顶点的点
t=h[1];
//将堆的最后一个点赋值到顶堆。
h[1]=h[n];
n--;//对减少一个
siftdown(1);//向下调整
return t;//返回之前记录的堆的顶点的最小值
}
int main()
{
int i,num;
//读入要排序的数字的格式
scanf("%d",&num);
for(i=1;i<=num;i++)
scanf("%d",&h[i]);
n=num;
//建堆
creat();
//删除顶部元素,连续删除n次,其实也就是从大到小输个来回
for(i=1;i<=num;i++)
printf("%d",deletemax());
getchar();
getchar();
return0;
} 以上只是其中一种方法,当然我们还有另一种更好的办法,从小到大排序的时候不建立最小堆而建立最大堆,最大堆建好后,最大的元素在h[1],因为我们的需求是从小到大排序,希望最大的值放后面,因此我们将h[1]和h[n]交换,此时h[n]就是数组中的最大元素。请注意,交换后还需将h[1]向下调整以保持堆的特性。OK最大的元素已经归为后,需要将堆的大小减一1即n–,并将交换后的信h[1]向下调整以保持堆的特性,如此反复直到堆的大小变成1为止,此时数组中的数就是已经排好的数了
完整代码如下:
#include<stdio.h>;
int h[101];
int n;
//交换函数
void swap(int x,int y)
{
int t;
t=h[x];
h[x]=h[y];
h[y]=t;
return;
}
//向下调整函数
void siftdown(int i)//传入一个需要想想啊调整的结点编号i,这里传入1,即从堆的顶点开始,向下调整
{
int t,flag=0;//用来标记是否需要继续向下调整
//当i结点有儿子(至少有左儿子的时候)并且有需要继续调整的时候就循环执行
while(i*2<=n &&flag == 0)
{
if( h[i]<h[i*2] )
t=i*2;
else
t=i;
//如果他有右儿子,再对右儿子进行讨论,
if(i*2+1 <= n)
{
//如果它有右儿子,在对右儿子进行讨论
if(h[t] < h[i*2+1])
t=i*2+1;
}
//如果发现最大的结点编号不是自己,说明子结点中有比父结点更大的
if(t!=i)
{
swap(t,i)
i=t;
}
else
flag=1;
}
return;
}
//建立堆的函数
void creat()
{
int i;
//从最后一个非叶结点到第一个结点依次向上调整
for(i=n/2;i>=1;i--)
{
siftdown(1);
}
return;
}
//堆排序
void heapsort()
{
while(n>1)
{
swap(1,n);
n--;
siftdown(1);
}
return;
}
int main()
{
int i,num;
//读入n个数
scanf("%d",&num);
for(i=1;i<=num;i++)
scanf("%d",&h[i]);
n=num;
//建堆
creat();
//堆排序
heapsort();
//输出
for(i=1;i<=num;i++)
printf("%d",h[i]);
getchar();
getchar();
return 0;
}最后总结一下,像这样支持插入元素和寻找最大小值元素的数据结构称为优先队列。如果使用普通队列来实现这两个功能,那么寻找最大元素需要枚举整个队列,这样的时间复杂度比较高。如果是已排序好的数组,那么插入一个元素则需要移动很多元素,时间复杂度仍然很高,而堆就是一种优先队列的实现,可以很好的解决这两种操作。
三、擒贼先擒王——并查集
我们先简述一下并查集的算法,并查集是一个通过一维数组来实现,其本质是维护一个森林。刚开始的时候,森林的每个点都是孤立的,也可以认为每个点都是一个孤立的,也可以理解为每一个点就是一课只有一个结点的树,之后通过一些条件,逐渐将这些树合并成一棵大树,其实合并的过程就是认爹的过程。在认爹过程中,要遵守靠左原则和擒贼先擒王原则。在每次判断两个结点是否已经在同一棵树中的时候(一棵树其实就是一个集合),也要注意必须要求其根源,中间父亲结点(小BOSS)是不能说明问题的,必须找到其祖宗(树的根结点),判断两个结点的组宗是否已经在同一个根节点才行,下面给出一个完整代码:
#include<stdio.h>
int f[1000]={0},n,m,k,sum=0;
//这里初始化,非常重要,数组里面存的是自己数组下标的编号就好了
void init()
{
int i;
for(i=1;i<=n;i++)
f[i]=i;
return;
}
//这是找爹的递归函数,不停地去找爹,知道找到祖宗为止,其实就是去找犯罪团伙的最高领导人。
//找到每个组织里的大Boss,
//擒贼先擒王原则
int gerf(int v)
{
if(f[v]==v)
return v;
else
{
f[v]=getf(f[v]);
return f[v];
}
}
//合并两个子集合的函数
void merge(int v,int u)
{
int t1,t2;//分别为v和u的大BOSS,每次双方的会谈都必须是各自最高领导人才行。
t1=getf(v1);
t2=getf(v2);
if(t1!=t2)//判断两个结点是否在同一个集合,即是否是同一个祖先
f[t2]=t1;
//靠左原则,左边变成右边的BOSS,即把右边的集合作为左边的子集合。
//经过路径压缩以后,将f[u]的根的值也赋值为v的祖先f[t1]。
return;
}
//请从主函数开始阅读程序
int main()
{
int i,x,y;
scanf("%d %d",&n,&m);
init();//初始化是必须的
for(i=1;i<=m;i++)
{
//开始合并团伙
scanf("%d %d",&x,&y);
marge(x,y);
}//最后扫描有多少个独立的团伙
for(i=1;i<=n;i++)
{
if(f[i]==i)
sum++;
}
printf("%d\n,sum);
getchar();getchar();
return 0;
}
总结:并查集我们用到的还是会很多,并且有很多人说用模板,我这种STL小白级的人物,就静静的看着你装B。
自述:我们得乐呵滴哈,真真得乐呵滴,你最亲的人,是你自己!为你活着,马上要写完了,感觉好不是滋味,时间好快,COME ON!















 3306
3306

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









