






import requests
from bs4 import BeautifulSoup #解析网页
import lxml
url="http://www.stats.gov.cn/sj/tjbz/tjyqhdmhcxhfdm/2022/index.html"
rep = requests.get(url) #Get方式获取网页数据
rep.encoding='utf-8' #我这里直接获取到rep之后中文全是乱码,所以设置一下编码格式
soup = BeautifulSoup(rep.text, 'lxml')
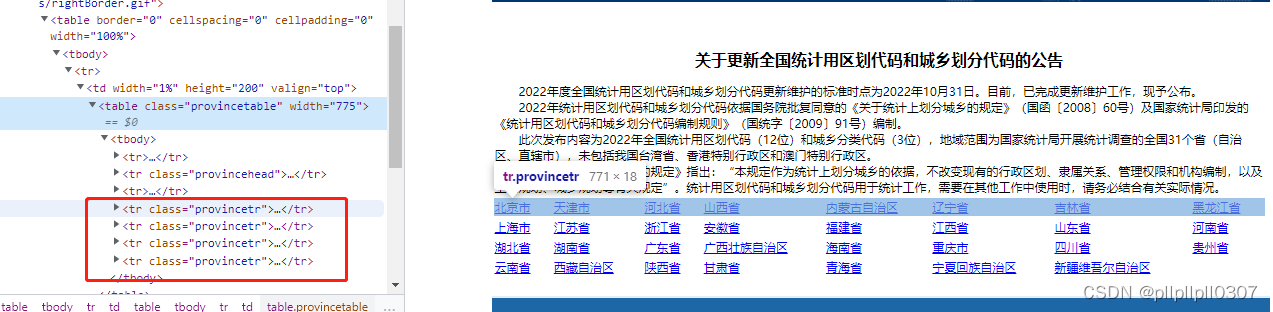
provinces = soup.select('.provincetr>td>a')
for province in provinces:
print(province.get_text())
print(province.get("href"))
# get_city_data(province.get("href"))
关于soup.select('.provincetr>td>a'),打开国家统计局页面后,f12调试模式可以看到主要内容的位置,可以直接根据className拿到数据。
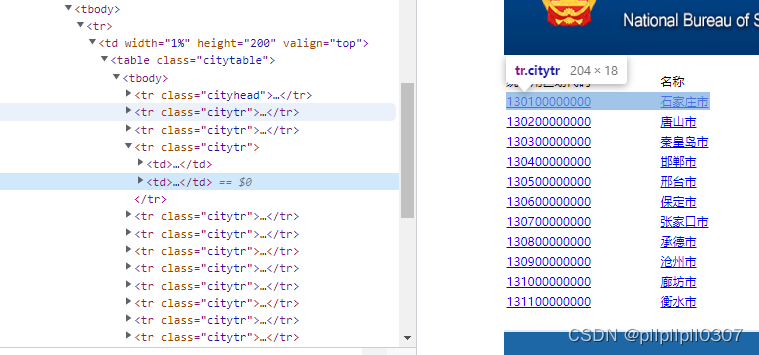
市数据的页面和省的不相同,列表左边是编码,右边是名字,要注意一下:
def get_city_data(href):
cityUrl = url.replace("index.html", href)
cityRep = requests.get(cityUrl)
cityRep.encoding = 'utf-8'
citySoup = BeautifulSoup(cityRep.text, 'lxml')
citys = citySoup.select('.citytr')
if citys is not None:
for city in citys:
c = city.select('td>a')
print(c[0].get("href"))
print(c[0].get_text()) #行政区划编码
print(c[1].get_text()) #名称
# get_county_data(c[0].get("href"))
print(citys)获取数据的方法都是一样的,有些判空我没有加,正式代码要多注意一点
def get_county_data( href):
county_url = url.rsplit("/",1)[0]+ "/" + href
county_rep = requests.get(county_url)
county_rep.encoding = 'utf-8'
county_soup = BeautifulSoup(county_rep.text, 'lxml')
countys = county_soup.select('.countytr')
if countys is not None:
for county in countys:
c = county.select('td>a')
if c: #过滤没有下级的数据
print(c[0].get("href"))
print(c[0].get_text()) # 行政区划编码
print(c[1].get_text()) # 名称
# get_town_data(county_url,c[0].get("href"))def get_town_data(county_url, href):
town_url = county_url.rsplit("/",1)[0] + "/" + href
town_rep = requests.get(town_url)
town_rep.encoding = 'utf-8'
town_soup = BeautifulSoup(town_rep.text, 'lxml')
towns = town_soup.select('.towntr')
for town in towns:
t = town.select('td>a')
print(t[0].get("href"))
print(t[0].get_text()) # 行政区划编码
print(t[1].get_text())这样省市县区数据就都可以打印出来了,也可以按照自己的格式写到文件里。
主要的点就在BeautifulSoup的select怎么用,数据拿到就好说了

















 663
663

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









