








import time
from lxml import etree
import wordcloud
# 词云
import jieba # 长句切分
# import imageio # 遮幕
import imageio.v2 as imageio
import requests
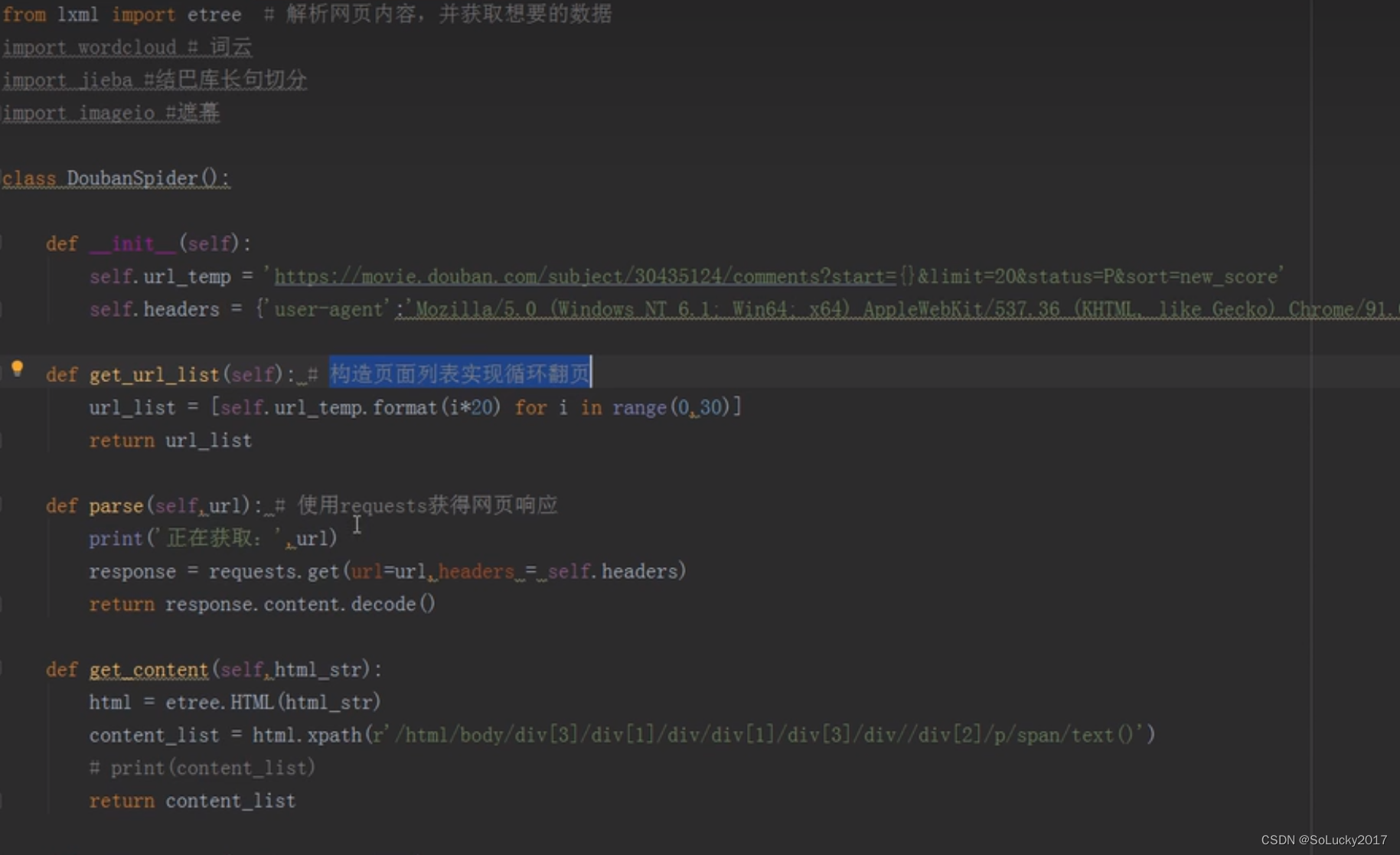
class DoubanSpider():
def __init__(self, ):
self.url_temp = 'https://movie.douban.com/subject/35290372/comments?start={}&limit=20&status=P&sort=new_score'
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.5359.95 Safari/537.36"
}
def get_url_list(self): # 构造url 翻页
url_list = [self.url_temp.format(i * 20) for i in range(0, 10)]
return url_list
def parse(self, url): # 请求
print("获取 url=" + url)
response = requests.get(url=url, headers=self.headers)
return response.content.decode()
def get_content(self, html_str):
html = etree.HTML(html_str)
content_list = html.xpath(r'/html/body/div[3]/div[1]/div/div[1]/div[4]//div/div[2]/p/span/text()')
# "/html/body/div[3]/div[1]/div/div[1]/div[3]//div/div[2]/p/span/text()"
# "/html/body/div[3]/div[1]/div/div[1]/div[4]/div[1]/div[2]/p/span"
# "/html/body/div[3]/div[1]/div/div[1]/div[4]/div[2]/div[2]/p/span"
print(content_list)
return content_list
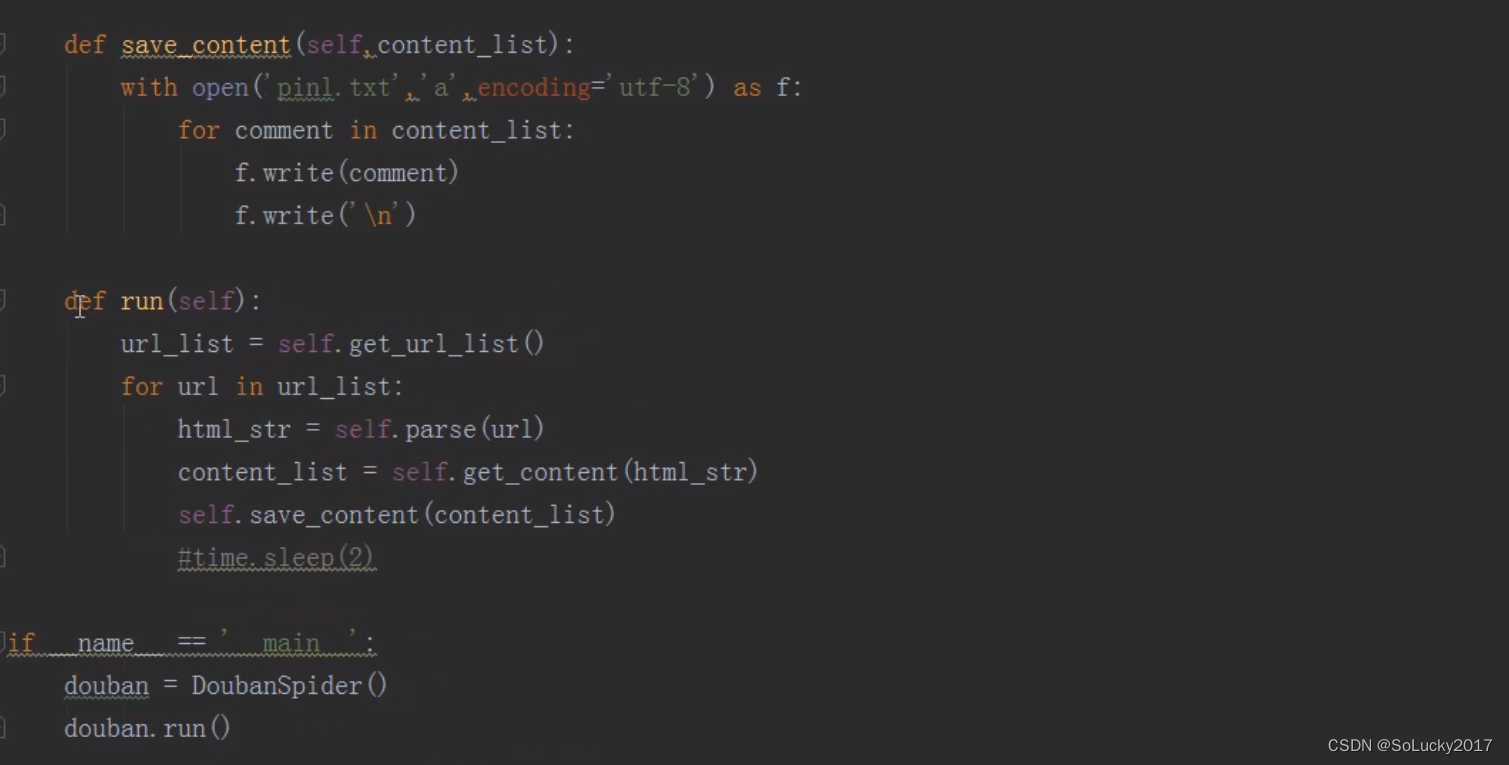
def save(self, content_list):
with open('doubanpl.txt', 'a', encoding='utf-8') as f:
for comment in content_list:
f.write(comment)
f.write('\n')
def run(self):
url_list = self.get_url_list()
for url in url_list:
html_str = self.parse(url)
content_list = self.get_content(html_str)
self.save(content_list)
time.sleep(1)
if __name__ == '__main__':
douban = DoubanSpider()
douban.run()
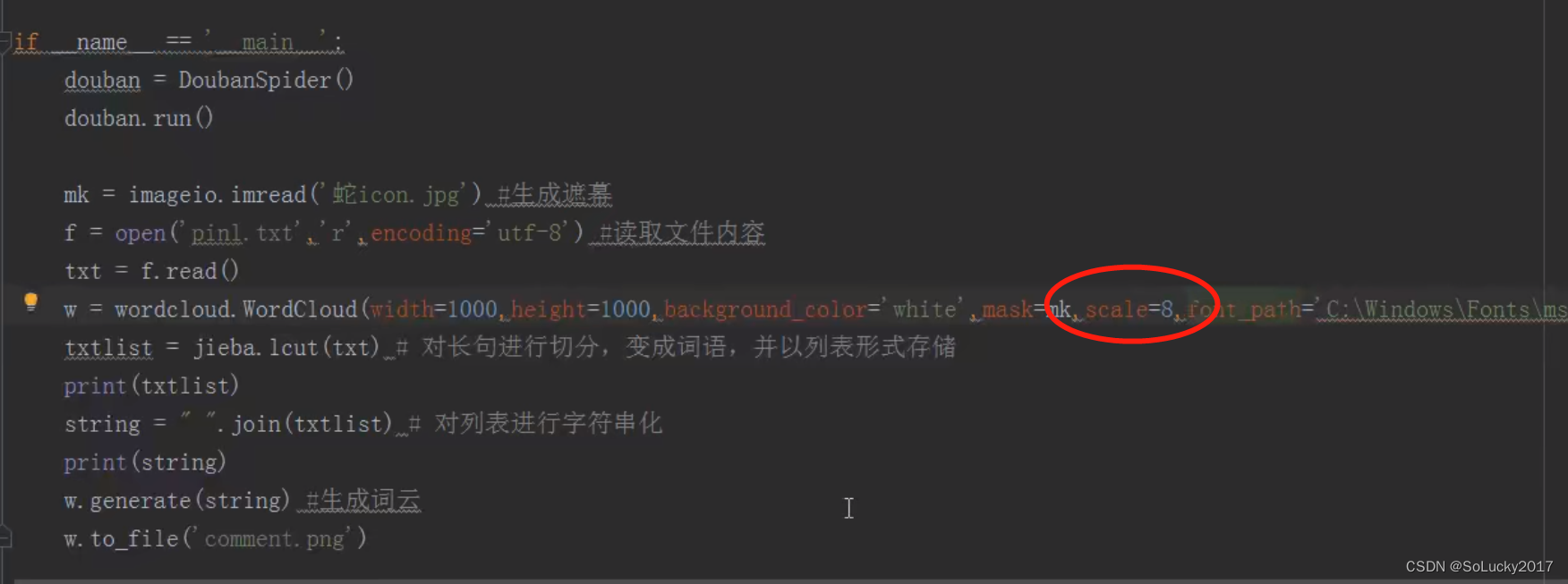
mk = imageio.imread('guangda.png')
# mk= imageio.imread()
f = open('doubanpl.txt', 'r', encoding='utf-8')
txt = f.read()
wmy = wordcloud.WordCloud(width=1000, height=1000, background_color='white', mask=mk, scale=8, font_path="C:\Windows\Fonts\msyhbd.ttc", stopwords={"的", "了", "和"})
txtlist=jieba.lcut(txt)
print(txtlist)
string=" ".join(txtlist)
print(string)
wmy.generate(string)
wmy.to_file("commentpng.png")note:
1. python script配置到环境变量:C:\Users\user\AppData\Roaming\Python\Python39\Scripts
2.自己的版本对应whl要清楚
3.numpy要下载带mkl的















 936
936











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









