







建议先看:
如何使用glove,fasttext等词库进行word embedding?(原理篇)
再看本篇。
先睹为快:本文会用到的全部代码:
def get_coefs(word, *arr):
return word, np.asarray(arr, dtype='float32')
def load_embeddings(path):
with open(path) as f:
return dict(get_coefs(*line.strip().split(' ')) for line in f)
def build_matrix(word_index, path):
embedding_index = load_embeddings(path)
embedding_matrix = np.zeros((len(word_index) + 1, 300))
for word, i in word_index.items():
try:
embedding_matrix[i] = embedding_index[word]
except KeyError:
pass
return embedding_matrix
# f为你下载下来的glove/fasttext训练好的模型
embedding_matrix = build_matrix(tokenizer.word_index, f)
#下面是你的模型。我这里是乱写的。
def build_model(embedding_matrix,...):
words = Input(shape=(MAX_LEN,))
x = Embedding(*embedding_matrix.shape, weights=[embedding_matrix], trainable=False)(words)
lstm = CuDNNLSTM(128)(x)
predictions = Dense(2)(lstm)
model = Model(inputs=words, outputs=predictions)
model.compile(loss='binary_crossentropy', optimizer='adam')
return model
model = build_model(...)
begin~~
ok。既然你看过上一篇博客,我们现在的任务就是把上文的两个大字典拼成一个权重矩阵了~
首先第一个字典是tokenizer.word_index,是现成的。我们可以直接用。重点是这个字典:也就是glove/fasttext中word与300维向量的字典。长这样:
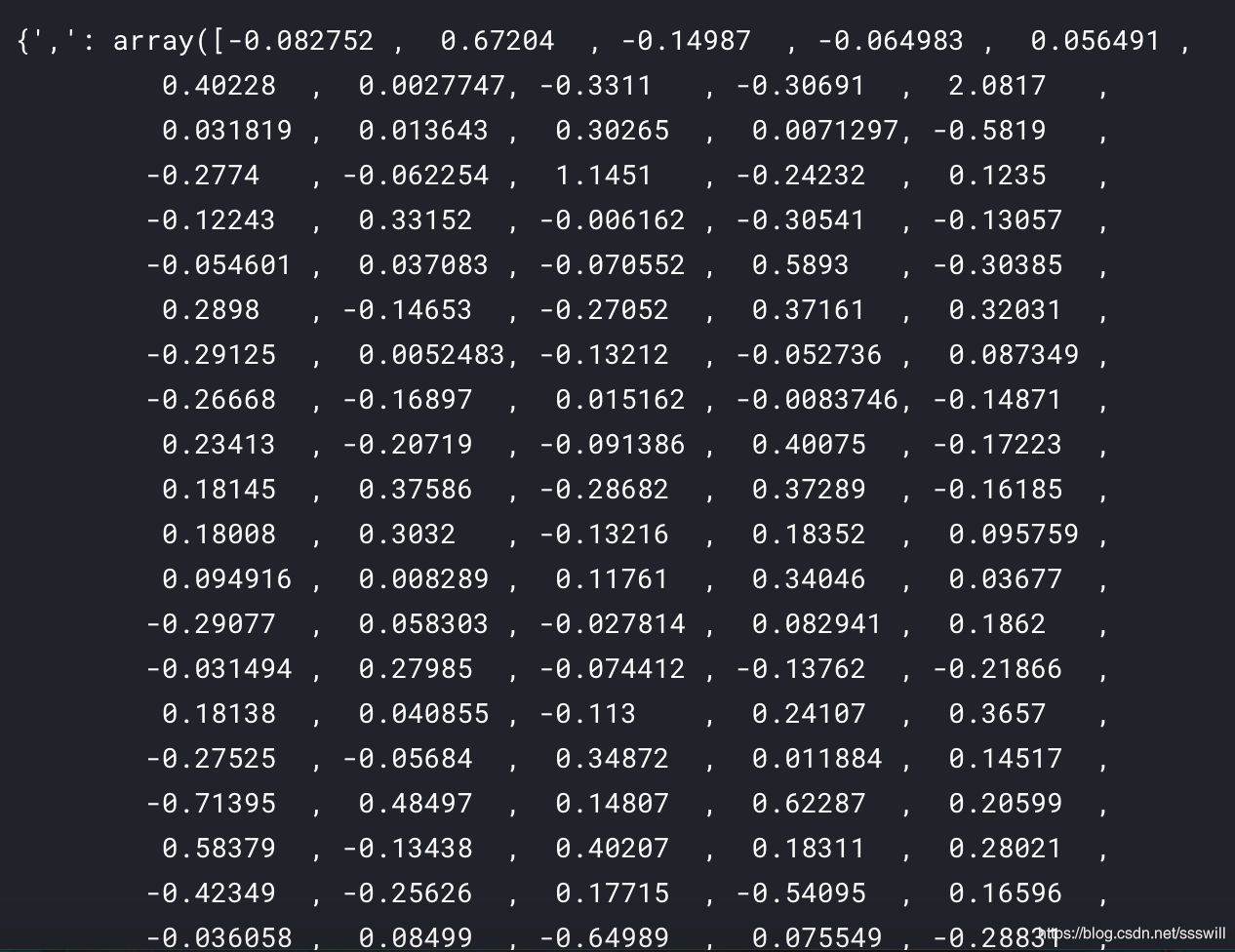
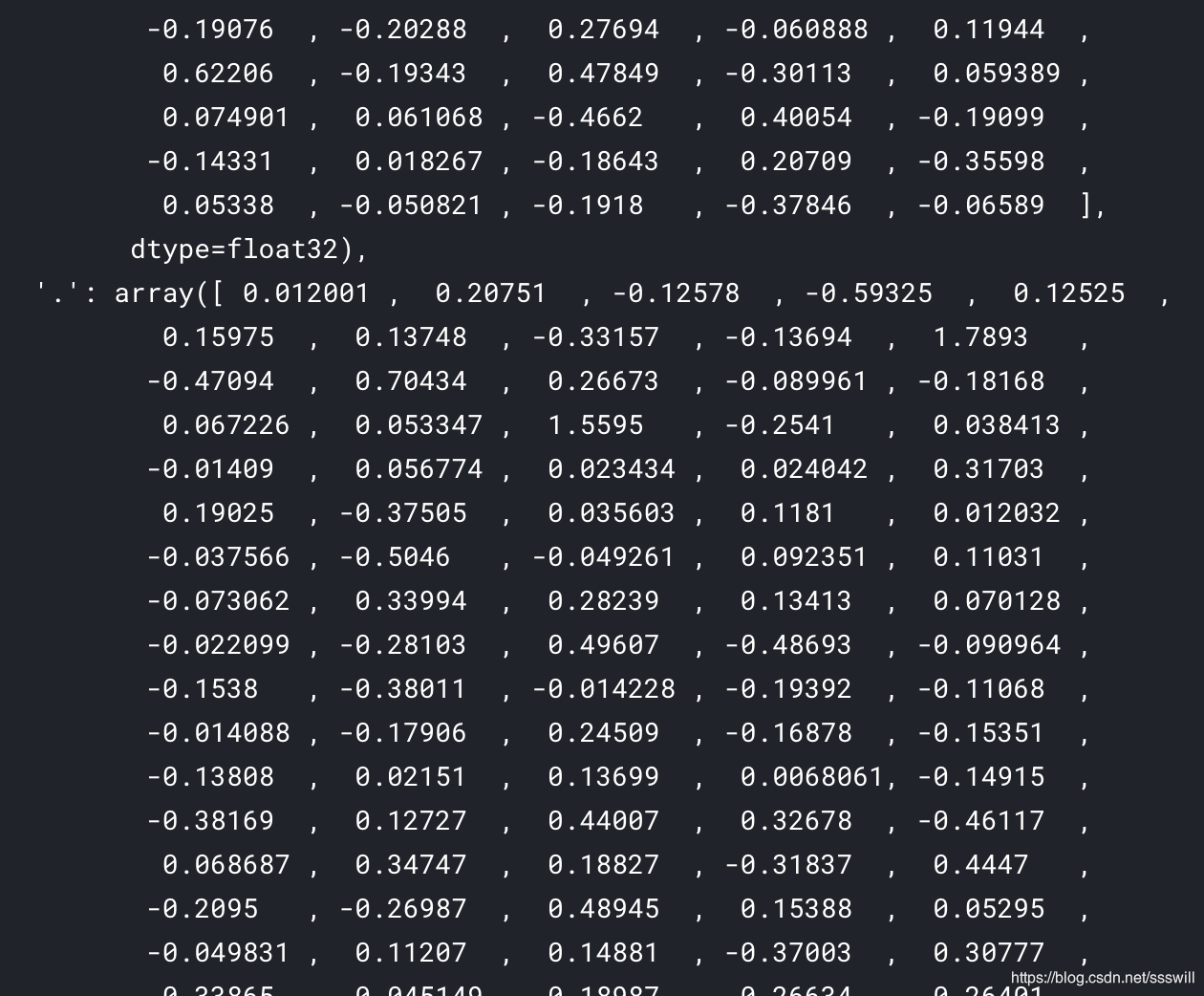
我们如何生成呢?
def get_coefs(word, *arr):
return word, np.asarray(arr, dtype='float32')
def load_embeddings(path):
with open(path) as f:
return dict(get_coefs(*line.strip().split(' ')) for line in f)
利用上面两个函数即可。
然后生成权重矩阵
def build_matrix(word_index, path):
embedding_index = load_embeddings(path)
embedding_matrix = np.zeros((len(word_index) + 1, 300))
for word, i in word_index.items():
try:
embedding_matrix[i] = embedding_index[word]
except KeyError:
pass
return embedding_matrix
# f为你下载下来的glove/fasttext训练好的模型
embedding_matrix = build_matrix(tokenizer.word_index, f)
上面的代码还是很好理解的,我把一些需要注意的稍微说一下:
def get_coefs(word, *arr):
return word, np.asarray(arr, dtype='float32')
def load_embeddings(path):
with open(path) as f:
return dict(get_coefs(*line.strip().split(' ')) for line in f)
如果你没有理解那肯定是这一段代码没看懂,它是在干嘛呢?
get_coefs(*line.strip().split(’ ')) for line in f
这句话,就是把文件f的每一行都做了一件事,去掉每行前后的空格,然后以空格进行split,得到一个列表。具体是这样的:
原来的一行是这样:
, -0.082752 0.67204 -0.14987 -0.064983 0.056491 0.40228 0.0027747 -0.3311 -0.30691 2.0817 0.031819 0.013643 0.30265 0.0071297 -0.5819 -0.2774 -0.062254 1.1451 -0.24232 0.1235 -0.12243 0.33152 -0.006162 -0.30541 -0.13057 -0.054601 0.037083 -0.070552 0.5893 -0.30385 0.2898 -0.14653 -0.27052 0.37161 0.32031 -0.29125 0.0052483 -0.13212 -0.052736 0.087349 -0.26668 -0.16897 0.015162 -0.0083746 -0.14871 0.23413 -0.20719 -0.091386 0.40075 -0.17223 0.18145 0.37586 -0.28682 0.37289 -0.16185 0.18008 0.3032 -0.13216 0.18352 0.095759 0.094916 0.008289 0.11761 0.34046 0.03677 -0.29077 0.058303 -0.027814 0.082941 0.1862 -0.031494 0.27985 -0.074412 -0.13762 -0.21866 0.18138 0.040855 -0.113 0.24107 0.3657 -0.27525 -0.05684 0.34872 0.011884 0.14517 -0.71395 0.48497 0.14807 0.62287 0.20599 0.58379 -0.13438 0.40207 0.18311 0.28021 -0.42349 -0.25626 0.17715 -0.54095 0.16596 -0.036058 0.08499 -0.64989 0.075549 -0.28831 0.40626 -0.2802 0.094062 0.32406 0.28437 -0.26341 0.11553 0.071918 -0.47215 -0.18366 -0.34709 0.29964 -0.66514 0.002516 -0.42333 0.27512 0.36012 0.16311 0.23964 -0.05923 0.3261 0.20559 0.038677 -0.045816 0.089764 0.43151 -0.15954 0.08532 -0.26572 -0.15001 0.084286 -0.16714 -0.43004 0.060807 0.13121 -0.24112 0.66554 0.4453 -0.18019 -0.13919 0.56252 0.21457 -0.46443 -0.012211 0.029988 -0.051094 -0.20135 0.80788 0.47377 -0.057647 0.46216 0.16084 -0.20954 -0.05452 0.15572 -0.13712 0.12972 -0.011936 -0.003378 -0.13595 -0.080711 0.20065 0.054056 0.046816 0.059539 0.046265 0.17754 -0.31094 0.28119 -0.24355 0.085252 -0.21011 -0.19472 0.0027297 -0.46341 0.14789 -0.31517 -0.065939 0.036106 0.42903 -0.33759 0.16432 0.32568 -0.050392 -0.054297 0.24074 0.41923 0.13012 -0.17167 -0.37808 -0.23089 -0.019477 -0.29291 -0.30824 0.30297 -0.22659 0.081574 -0.18516 -0.21408 0.40616 -0.28974 0.074174 -0.17795 0.28595 -0.039626 -0.2339 -0.36054 -0.067503 -0.091065 0.23438 -0.0041331 0.003232 0.0072134 0.008697 0.21614 0.049904 0.35582 0.13748 0.073361 0.14166 0.2412 -0.013322 0.15613 0.083381 0.088146 -0.019357 0.43795 0.083961 0.45309 -0.50489 -0.10865 -0.2527 -0.18251 0.20441 0.13319 0.1294 0.050594 -0.15612 -0.39543 0.12538 0.24881 -0.1927 -0.31847 -0.12719 0.4341 0.31177 -0.0040946 -0.2094 -0.079961 0.1161 -0.050794 0.015266 -0.2803 -0.12486 0.23587 0.2339 -0.14023 0.028462 0.56923 -0.1649 -0.036429 0.010051 -0.17107 -0.042608 0.044965 -0.4393 -0.26137 0.30088 -0.060772 -0.45312 -0.19076 -0.20288 0.27694 -0.060888 0.11944 0.62206 -0.19343 0.47849 -0.30113 0.059389 0.074901 0.061068 -0.4662 0.40054 -0.19099 -0.14331 0.018267 -0.18643 0.20709 -0.35598 0.05338 -0.050821 -0.1918 -0.37846 -0.06589
按上面说的做完后,变成一个列表,[’,’ , ‘-0.082752’ , ‘0.67204’…]。前面不是还有个*号嘛,他的意思就是把这个列表拆开,变成301个独立的元素。
*的意思可参见
python 在列表,元组,字典变量前加*号。。
之后把这301个元素传到get_coefs()函数中,第一元素’,'就变成了返回值word,剩下300个元素则被as成array了。
也就是这个函数:
def get_coefs(word, *arr):
return word, np.asarray(arr, dtype='float32')
最终就成了
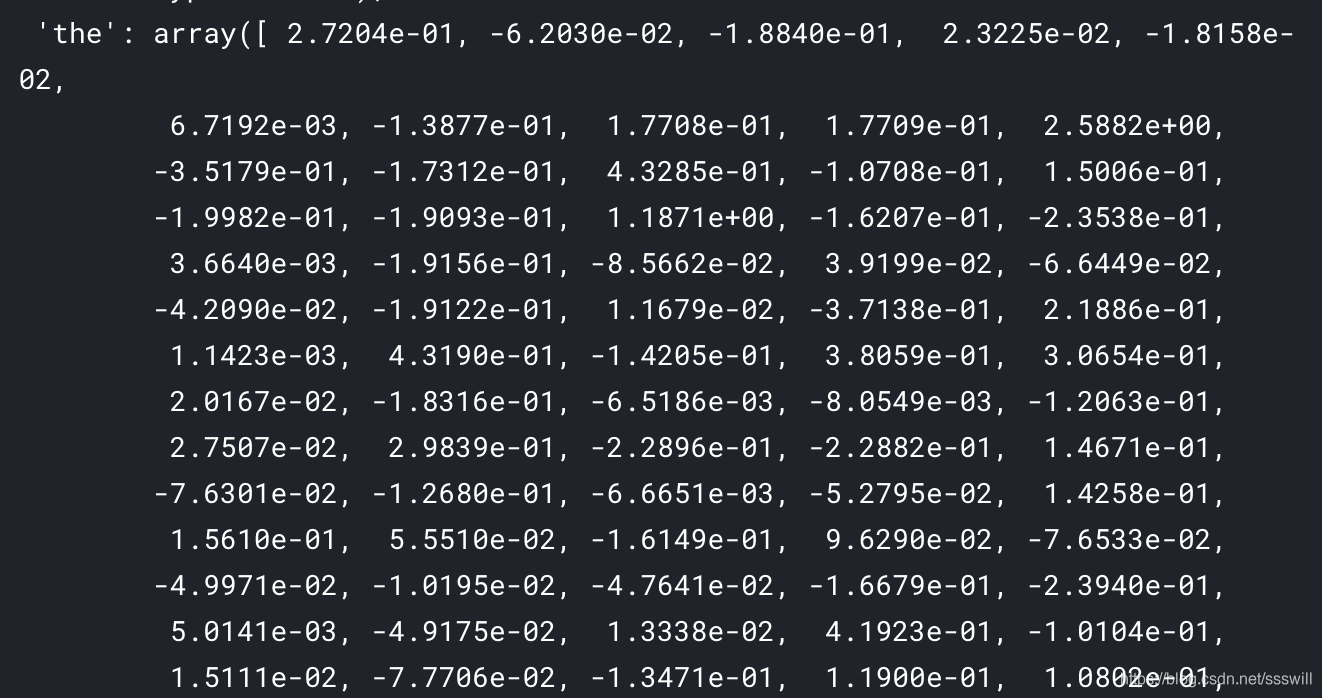
这样的字典。key值为单词,value为一个(300,)的numpy array。
然后用build_matrix函数生成权重矩阵即可。
整体代码请看文章开头。
参考:
https://blog.csdn.net/weixin_40877427/article/details/82931899
https://www.kaggle.com/thousandvoices/simple-lstm?scriptVersionId=12556909














 962
962











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









