







马上6.8就到28岁了,我今年的梦想是顺利毕业,活到五十岁。此篇献给垃圾喵主?。
前言
上一篇说的是word2vec,老子还是没有静下心来去好好撸源代码,只能说有个大概印象了。就是先处理词,再训练。回头还是要持续更新这些博客的,东西要经常反复看,才能有更深的理解吧。每次只是花一点时间学习,没有下大功夫,总是会被其他事情打断。真是搓气,搓气喵?。
word2vec篇:https://blog.csdn.net/mashutian/article/details/89646050
glove
GloVe这个东西其实当时名声也很响亮的,但是大多数人都在用word2vec吧,glove这玩意儿是斯坦福大学的曼宁带头搞的(我猜的),跟word2vec也就是一前一后出来的。其实,每次听到glove,我都会联想到地球什么的。什么鬼,但是我没碰过glove,一点都没有,这次要碰下它,嗯。常见到的Global Vector 模型( GloVe模型)是一种对“词-词”矩阵进行分解从而得到词表示的方法,属于基于矩阵的分布表示。这次拎出来感受下他的精髓。
1. 相关文章就是下面这篇了,文章还给了链接,glove的网站,上面有训练好的向量哦:https://nlp.stanford.edu/projects/glove/:
- Pennington J, Socher R, Manning C. Glove: Global vectors for word representation[C]//Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP). 2014: 1532-1543.
作者在摘要说了,最近词向量的效果太好了,指的就是那个word2vec我猜,但是吧大家都不知道为啥好,为啥能捕捉到语义啊为啥能捕捉到语法规则那种信息呢,于是作者希望We analyze and make explicit the model properties needed for such regularities to emerge in word vectors。大概意思就是我们想摸索出一些规律。
反正作者提出了这个new global logbilinear regression model that combines the advantages of the two major model families in the literature: global matrix factorization and local context window methods。然后作者说了,与其用稀疏的大矩阵和语料中一个个的上下文窗口来做训练,不如用词共现矩阵,只用非零元素,让我们的vector space更有意义,效果也更好。好了,这个摘要大概提到了三个东西global matrix factorization,local context window methods,还有这个the nonzero elements in a word-word cooccurrence matrix。
相关工作的时候,作者先讲了矩阵分解,先前吧,为了学习向量表示,我们都会使lsa这样的模型,就是term-document这样的矩阵来玩,但是还有一种模型叫做the Hyperspace Analogue to Language (HAL),是利用的term-term这样的矩阵。就是行列都是词,然后每位的值指的是给了另一个词作为上下文时这个词的出现频次。然而呢HAL这个方法有个缺点,就是对高频词没做处理,比如the和and经常出现,但是他俩之间没啥语义关系呀。而后人们提出了些新模型来改进这个问题,比如COALS, PPMI, HPCA之类的吧。
除了矩阵分解,还有一个是Shallow Window-Based Methods,也就是利用上下文窗口来预测词学习词表示。除了CBOW和skip-gram,作者还提到几个工作就是下面这俩,Mnih和这个K提出了closely-related vector log-bilinear models, vLBL and ivLBL,然后 Levy et al. 提了个基于PPMI值的 explicit word embeddings ,突然觉得都要看下,??。反正这个Shallow Window-Based Methods没有直接从语料的统计信息中获取到一些有用的东西:
- Mnih A, Kavukcuoglu K. Learning word embeddings efficiently with noise-contrastive estimation[C]//Advances in neural information processing systems. 2013: 2265-2273.
- Levy O, Goldberg Y. Linguistic regularities in sparse and explicit word representations[C]//Proceedings of the eighteenth conference on computational natural language learning. 2014: 171-180.
于是乎,作者就来了个共现这么重要的信息你不用吗!这才是meaning精髓啊!
We use our insights to construct a new model for word representation which we call GloVe, for Global Vectors, because the global corpus statistics are captured directly by the model.
好了,我要来贴文章了:
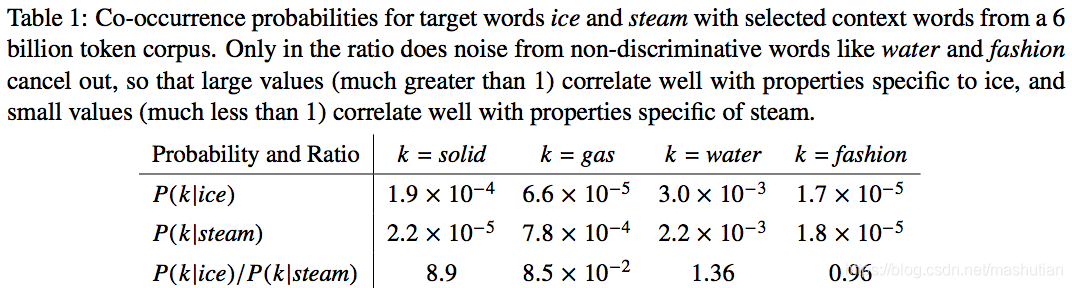
这个表➕原文的解释大概想讲的就是这么最后一句话,一个词相对于两个上下文词的概率的比值如果远大于1,那这个词就跟分子的那个上下文词很像,如果远小于1那就跟分母的那个上下文词很像。然后我们就有关键的三个词了,分子,分母和nobody词。阿哈哈哈哈。权力的游戏要结束了!!妖孽。就是下面的那个i, j, k。

然后,右边那个概率我们从语料里就能学出来所以不用操心,然后,我们就要说一下作者是怎么变戏法变左边的F函数的了。我们希望F要表达出概率比信息啊,那我们让两个词向量减一下吧。

啊呀,不好,右边是标量啊,左边是向量,那我向量转制一下再点积吧。

然后,喵的,作者又觉得,这个上下文词和nobody词是可以时刻互换啊,果然nobody是nobody,我们要对称我们的公式啊。首先,左面这个F框起来的东西我们拆开来,变成分子分母即公式4,然后因为左边跟右边相同,所以有了公式5。然后如果我们F是exp的话,那就有了公式6了。

然后吧,你看这个公式6右边的这个logXi跟nobody词一点关系也没有诶,所以我们把他挪到等式左边的时候就巴拉巴拉小魔仙变成bias摔过去。

好嘛,然后作者自己都说了现在的公式7简单吧,但是是错的啊。因为右边是log的话,左边的要大于0吧,log函数后面如果是0该咋办?然后作者说要不➕1吧。然后作者又说了现在还有个问题就是没有区分高频词低频词啊,然后就整了个f权重,加1的方法作为baseline了,实际的模型是平方了。反正损失函数就是下面的公式8了。然后权重函数具体长什么样子就去原文看吧。

再后来,作者分析了自己的模型和skip-gram啊ivLBL有什么样的关系。就其他这些模型都想最大化上下文窗口里词语一起的log概率吧,但是整个语料弄下来多费劲儿呢,我们glove就不一样,我们glove就是有效,因为我们直接利用共现矩阵把*相近的词拎出来了。然后吧,作者把他们的损失函数重新写了下,不得了了,发现可以看成global skip-gram模型啊。但是相比以交叉熵作为损失函数,作者觉得交叉熵不方便model长尾的那种分布啊,那我们肯定用最小二乘法。最后再夸一下本文提出可以区分不同词频的词语的权重函数。最后再分析下模型复杂度。反正最后的最后实验结果是还可以的。
2. 讲解分析与代码部分
照旧还是贴一下别人的链接,不过刚刚文章讲了一遍以后,有没有觉得有点懂了。后来发现网络上的一些分析基本都是文章重述,没有特别让人哦哦哦啊啊啊的那种分析,所以这边就直接给些链接,看来这个文章还是写的清楚啊。大白话说一遍大家都了然于胸了。
其他链接:
文章讲解:
https://blog.csdn.net/codertc/article/details/73864097
http://www.fanyeong.com/2018/02/19/glove-in-detail/
embedding的模型评估:https://www.cnblogs.com/iloveai/p/cs224d-lecture3-note.html
实践操作:
https://blog.csdn.net/sscssz/article/details/53333225
源码在这里,又是c啊啊啊啊?:https://github.com/stanfordnlp/GloVe
总共有四块内容,从GitHub上面的介绍看,vocab_count(做数据预处理的顺便去掉低频词),cooccur(构建共现矩阵),shuffle(数据shuffle,拆分,拼接)和glove。
源码解析先po个链接,回头再懵懵懂懂看下:https://blog.csdn.net/zyy617532750/article/details/83215130
流水的源码?,铁打的垃圾?。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









