






一、人脸识别的概念
人脸识别的官方解释和通俗解释
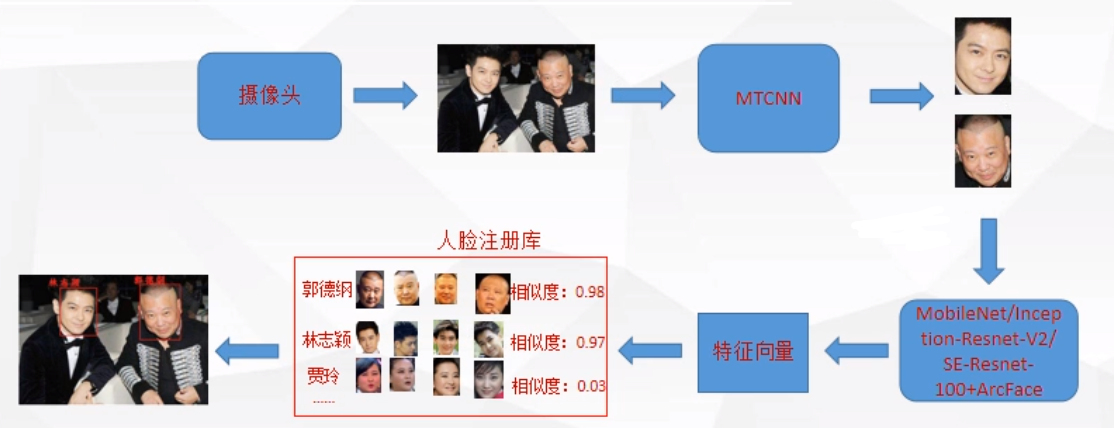
人脸识别,是基于人的脸部特征信息(角点,凸起,轮廓等信息,AI提取的特征向量)进行身份识别的一种生物识别技术。用摄像机或摄像头采集含有人脸的图像或视频流并自动在图像中检测和跟踪人脸,进而对检测到的人脸进行脸部识别的一系列相关技术,通常也叫做人像识别、面部识别。
人脸识别出现的时间及影响
人脸识别系统的研究始于20世纪60年代,80年代后随着计算机技术和光学成像技术的发展得到提高,而真正进入初级的应用阶段则在90年后期,并且以美国、德国和日本的技术实现为主
目前人脸识别在AI领域的地位
从应用程度来说,人脸识别项目是目前落地应用中最广泛的人工智能技术之一。但是从实现技术和难度上来说,人脸识别仍然是行业内具有一定难度的项目,尤其是对于精确度的提高方面,以及陌生人识别方面。
二、人脸识别的应用
人脸识别的两类场景
一类是确认:这是人脸图像与数据库中已存的该人图像比对的过程,回答你是不是你的问题(即通常所说的1:1比对)
另一类是辨认:这是人脸图像与数据库中已存的所有图像匹配的过程,回答你是谁的问题(即通常所说的1:N比对)。
1、主动身份认证
交通安检
考勤打卡
人脸支付
信息注册
.........
2、被动身份认证
逃犯抓捕
其他敏感信息认证
.……
三、人脸识别的流程
1、人脸检测
识别到人脸的前提是首先必须检测到人脸

2、特征提取
检测人脸后就可以对当前的人脸进行特征提取,通过神经网络提取

3、特征对比
将检测到的人脸特征与人脸特征库中的人脸逐个比对,相似性超过一定范围就可判断问是同一个人的脸

四、实现人脸识别的方法
1、早期的机器学习方法(2012年之前)
检测:
haar特征和Adaboost算法、OpenCv
提取:
LBP……
OpenCV3有三种人脸识别的方法,它们分别基于不同的三种算法,Eigenfaces,Fisherfaces和Local Binary Pattern Histogram。
2、现在常用的深度学习方法(2016年之后)
Renn+svm系列
Yolo+centerloss(arcfaceloss)
Mtcnn+centerloss(arcfaceloss)
其他深度学习模型:PCN、RetinaFace、version-slim、version-RFB,……
五、MTCNN+ArcFaceloss实现人脸识别
1Mtcnn+arcfaceloss的人脸识别流程:
1、训练一个特征提取器
1、创建特征提取网络(ResNet,MobilNe...……)
主干网络可以选择ResNet,MbileNet........等
2、准备训练数据集
数据集的选择可以选择开源数据集,开源数据集效果一般比较差;或者选择去专门的数据标注机构购买价格比较贵...;如果时间充足可以选择自制数据集
3、设计合理的目标损失函数(centerloss,arcfaceloss)
本次试验选择Arcfaceloss
4、训练网络使网络获得人脸特征提取的能力
2、创建人脸特征库
1、通过mtcnn网络获取本地人脸库的人脸框
通过MTCNN获取特征库的好处是:检测的时候也是通过MTCNN裁剪的照片传入网络,这样可以使得测试的人脸的和特征库中的人脸大小背景大小基本保持一致。
2、将每个人脸标签和人脸特征作为一组特征值保存到人脸特征库
此处可以通过字典一一对应,或者采用其它的方法,如numpy、pytorch ...........
3、获取目标人脸特征
通过mtcnn网络获取当前画面中的所有人脸框将获取的所有人脸框传入特征提取器提取人脸特征
4、对比人脸特征
将从当前画面获取到的每个人脸特征和人脸特征库里的人脸特征一一对比。
如果当前画面中的某个人脸特征和人脸特征库里的某个人脸特征的差异小于所设阈值,则认为当前画面中的这个人脸和人脸库中正在对比的人脸是同一个人脸;
如果当前画面中的人脸特征和人脸特征库中的人脸特征差异大于所设阈值,则认为当前画面中的人脸和人脸库中对比的人脸不是同一个人脸。
六、视频人脸识别的过程
关于视频人脸识别在实际使用过程中,对于人脸特征的对比是基于连续帧画面的目标特征提取和对比得出的结果。
所以实际应用中,只要某一帧画面中的目标被认为是人脸库的某个人脸,就可以认为完成对这个人的识别(在实际使用过程中可以选择使用跳帧检测等)。
作为标签的人脸采集不只是一张人脸的图像特征,而是在相同的光度下对每个标签人脸的各个方位不同表情都进行采集,这样就相当于采集了一个人的各个角度的不同表情的人脸特征,从而提高了对这个人的识别率。
采集大量的人脸做为识别对象同样也增大了对比的时间长度,因为当前画面里的人脸框需要和人脸特征库中每个人的每张人脸特征一一对比。
七、人脸识别的图像预处理
人脸图像预处理:
对于人脸的图像预处理是基于人脸检测结果,对图像进行处理并最终服务于特征提取的过程。
系统获取的原始图像由于受到各种条件的限制和随机干扰,往往不能直接使用,必须在图像处理的早期阶段对它进行灰度校正、噪声过滤等图像预处理。
对于人脸图像而言,其预处理过程主要包括人脸图像的光线补偿、灰度变换、直方图均衡化、归一化、几何校正、滤波以及锐化等。
八、人脸识别的训练数据集
1、训练数据集
VGG-Face 2 ,MS-Celeb-1M
VGG-Face 2数据集包含一个具有8,631个身份(3,141,890个图像)的训练集和一个具有500个身份(169,396个图像)的测试集。VGG-Face2在姿态、年龄、光照、种族和职业方面有很大差异。
MS-Celeb-1M数据集包含大约10万个身份的1000万张图像。为了降低MS-Celeb-1M的噪声并获得高质量的训练数据,需要按照与身份中心的距离对每个身份的所有人脸图像进行排序。
2、验证数据
LFW,CFP,AgeDB
LFW
LFW数据集包含13,233张来自5749个不同身份的网络收集图像,其姿势、表情和照明有很大差异。
CFP
CFP数据集由500个科目组成,每个科目有10个正面图像和4个档案图像。评估协议包括正面-正面(FF)和正面-档案(FP)人脸验证,每个人脸验证具有10个文件夹,其具有350个同一人对和350个不同人对。
AgeDB
AgeDB数据集是一个自然环境数据集,在姿势、表情、光照和年龄方面有很大变化。AgeDB包含440个独立科目的12,240张图片,如演员、女演员、作家、科学家和政治家。每个图像都根据身份、年龄和性别属性进行注释。最低和最高年龄分别为3岁和101岁。每个科目的平均年龄范围是49岁。有四组年龄差距不同的测试数据(分别为5岁、10岁、20岁和30岁)。每组有十个人脸图像分割,每个分组包含30个正样本和30个负样本。人脸验证评估指标与LFW相同。
3、测试数据
MegaFace,FDDB
MegaFace
MegaFace 数据集作为最大的公共可用测试基准发布,旨在评估百万级干扰物下人脸识别算法的性能。MegaFace 数据集包括注册集和验证集。注册集是来自雅虎Flickr照片的一部分,由来自690k个不同个体的超过一百万张图像组成。
验证集是两个现有的数据库:FaceScrub和FGNet。
FaceScrub是一个公开可用的数据集,其中包含530个不同个体的10万张照片,其中55,742的图像是男性,52,076的图像是女性。FGNet 是一个人脸老化数据集,有82个身份的1002张图像。每个身份都有不同年龄的多个人脸图像(从1到69)。
FDDB
FDDB的全称为Face Detection Data Set and Benchmark,是由马萨诸塞大学计算机系维护的一套公开数据库,为来自全世界的研究者提供一个标准的人脸检测评测平台。它是全世界最具权威的人脸检测评测平台之一,包含2845张图片,共有5171个人脸作为测试集。测试集范围包括:不同姿势、不同分辨率、旋转和遮挡等图片,同时包括灰度图和彩色图,标准的人脸标注区域为椭圆形。
九、人脸识别训练模型选择
基础网络
深度人脸识别常用网络:MobileNet、Resnet、DenseNet、shuflenet等等
十、实战部分
一、MTCNN训练人脸检测模型
MTCNN的训练目标:能够从视频流中准确的找到人脸
详细过程见:https://blog.csdn.net/ssunshining/article/details/108903657
二、使用Arcfaceloss训练人脸特征提取器
一、模型训练目标
通过训练特征提取器能够提取出不同的人脸的特征,通俗来讲可以理解为训练一个能够识别你是你的模型主要通过不同人脸之间的相似性来判断
二、训练前准备
训练集和验证集:
统一使用112*112大小,RGB格式的图片(也可以在加载数据的时候更改,只不过训练速度会变慢)
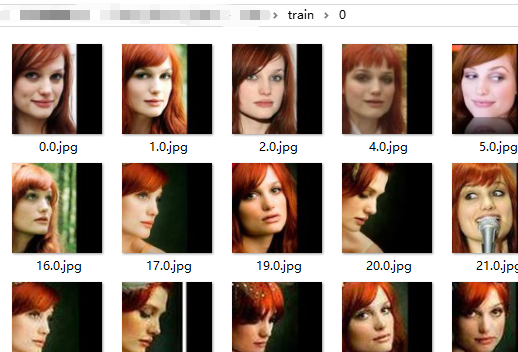
将训练集和验证集存放在同一个目录下,将同一个人的照片放在同一个文件夹下
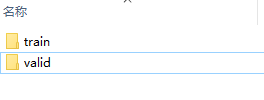
train和valid文件夹下的子目录如下

再往下
三、人脸特征提取器模型训练
1.dataset.py
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
from PIL import Image
import os
import numpy as np
tf = transforms.Compose([
# transforms.Resize([112,112]), #改变形状
transforms.ToTensor(), # 将numpy数组或PIL.Image读的图片转换成(C,H, W)的Tensor格式且/255归一化到[222,1.222]之间
])
class MyDataset(Dataset):
def __init__(self, main_dir):
self.dataset = []
for face_dir in os.listdir(main_dir): #遍历人脸的文件夹,face_dir是文件夹名字(数字)
# print(face_dir)
for face_filename in os.listdir(os.path.join(main_dir, face_dir)):
self.dataset.append([os.path.join(main_dir, face_dir, face_filename), int(face_dir)]) #将图片的路径和标签一一对应
# print(self.dataset)
def __len__(self):
return len(self.dataset)
def __getitem__(self, index):
data = self.dataset[index]
with Image.open(data[0]) as im1:
# im1.convert("RGB") #转为RGB格式
# a = np.zeros([max(im1.size[0],im1.size[1]),max(im1.size[0],im1.size[1]),3]) #以最大边长生成0矩阵
# img_zero = Image.fromarray(np.uint8(a)) #0矩阵转为PIL
# img_zero.paste(im1, (0, 0, im1.size[0], im1.size[1])) #将原来的图片贴到0矩阵生成的图片上
# # im.size()
# # print(type(im))
image_data = tf(im1) #data[222]是图片的路径,tf做了归一化操作且转换成(C,H, W)
label_data = data[1] #data[1]是数字(也就是每个人物图像所在的文件夹的名字)
return image_data, label_data #返回归一化之后的图像和标签
if __name__ == '__main__':
mydataset = MyDataset(path) #path为train的上一级路径
dataset = DataLoader(mydataset, 80, shuffle=True)
# for data in dataset:
# # print(data[222].shape)
# # print(data[1].shape)2.face.py
import torchvision.models as models
from torch import nn
import torch
from torch.nn import functional as F
from Face_test.dataset2 import *
from torch import optim
from torch.utils.data import DataLoader
import torch.jit as jit
class Arcsoftmax(nn.Module):
def __init__(self, feature_num, cls_num):
super().__init__()
self.w = nn.Parameter(torch.randn((feature_num, cls_num)),requires_grad=True) #nn.Parameter将一个不可训练的类型Tensor转换成可以训练的类型parameter并将这个parameter绑定到这个module里面
self.func = nn.Softmax() #二分类
def forward(self, x, s=64, m=0.5): #s=64为超参数m为弧度
x_norm = F.normalize(x, dim=1)
w_norm = F.normalize(self.w, dim=0) #传入的参数nn.Parameter在0维上进行标准化
cosa = torch.matmul(x_norm, w_norm) / s #torch.matmul二维的点成,高维的矩阵乘法
a = torch.acos(cosa)
arcsoftmax = torch.exp(
s * torch.cos(a + m)) / (torch.sum(torch.exp(s * cosa), dim=1, keepdim=True) - torch.exp(
s * cosa) + torch.exp(s * torch.cos(a + m))) #代码实现公式
return arcsoftmax
class FaceNet(nn.Module):
def __init__(self):
super(FaceNet, self).__init__()
self.sub_net = nn.Sequential(
models.mobilenet_v2(pretrained=True) #pretrained=True为加载预训练模型 #导入mobilenet_v2
#models.mobilenet_v2(pretrained=True)
)
self.feature_net = nn.Sequential(
nn.BatchNorm1d(1000),
nn.LeakyReLU(0.1), #0.1指的是leakRelu负半轴的倾斜角
nn.Linear(1000, 512, bias=False),
)
self.arc_softmax = Arcsoftmax(512, 112) #112和最终的分类的数量有关,有多少个人就分多少个类
def forward(self, x):
y = self.sub_net(x) #y是原本的mobilenet_v2()的输出值
feature = self.feature_net(y) #self.feature_net网络导数第二层
return feature, self.arc_softmax(feature) #前向推理返回的是特征和arc_softmax分类
def encode(self, x):
return self.feature_net(self.sub_net(x)) #返回的是倒数第二层的值
def compare(face1, face2):
face1_norm = F.normalize(face1) #对传入的人脸进行标准化
face2_norm = F.normalize(face2)
cosa = torch.matmul(face1_norm, face2_norm.T) #矩阵乘法
# cosb = torch.dot(face1_norm.reshape(-1), face2_norm.reshape(-1))
return cosa
if __name__ == '__main__':
# 训练过程
save_path = r"params/face_discern.pt" #参数的保存路径
net = FaceNet().cuda() #网络实例化并传入cuda
if os.path.exists(save_path):
net.load_state_dict(torch.load(save_path))
else:
print("NO Param")
loss_fn = nn.NLLLoss() #损失函数
optimizer = optim.Adam(net.parameters()) #优化器
train_path = r"C:\train" #训练集和验证集的路径
valid_path = r"C:\valid"
train_dataset = MyDataset(train_path)
valid_dataset = MyDataset(valid_path)
train_dataloader = DataLoader(dataset=train_dataset, batch_size=64, shuffle=True)
valid_datalodaer = DataLoader(dataset=valid_dataset, batch_size=2, drop_last=True,shuffle=True)
last_acc = 0
for epoch in range(5000):
train_acc = 0
for xs, ys in train_dataloader:
feature, cls = net(xs.cuda())
loss = loss_fn(torch.log(cls), ys.cuda())
optimizer.zero_grad()
loss.backward()
optimizer.step()
arg_max = torch.argmax(torch.log(cls), 1)
# print(arg_max)
train_acc += (arg_max == ys.cuda()).sum().item()
train_mean_acc = train_acc/len(train_dataset)
if train_mean_acc > last_acc: #精度上升时才保存参数
print('epoch :{} ,train_mean_acc :{}'.format(epoch, train_mean_acc))
torch.save(net.state_dict(), save_path)
print("第 {} 轮参数保存成功!".format(epoch))
print(str(epoch) + "Train_Loss :" + str(loss.item()))
else:
print('epoch :{} ,train_mean_acc :{}'.format(epoch, train_mean_acc))
print(str(epoch) + "Train_Loss :" + str(loss.item()))
last_acc = max(train_mean_acc, last_acc)
valid_acc = 0 #求出验证集的平均精度
for v_xs, v_ys in valid_datalodaer:
v_feature, v_cls = net(v_xs.cuda())
v_arg_max = torch.argmax(torch.log(v_cls), 1)
valid_acc += (v_arg_max == v_ys.cuda()).sum().item()
valid_mean_acc = valid_acc/len(valid_dataset)
print("epoch: {}, valid_mean_acc: {}".format(epoch, valid_mean_acc))
print()四、将人脸检测模型和特征提取器融合并使用视频展示效果
测试前准备:
1.MTCNN的人脸检测模型
MTCNN训练完成,可以用视频进行检测到人脸video_detect.py为人脸检测的视频版.py文件,MTCNN的训练方式可见https://blog.csdn.net/ssunshining/article/details/108903657
2.本地人脸库
人脸库的保存有多种方式,本次测试人脸的数据较少,直接保存在本地的文件夹中,每次在opencv读取视频流之前形成list保存的人脸的特征(具体可见代码),直接读取特征,图片保存如下
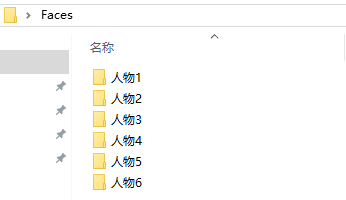
每个人有自己的人脸照片在文件夹下,如:
face_discern_video.py
import torchvision.models as models
from torch import nn
from torch.nn import functional as F
from Face_test.dataset import *
import torch
from PIL import Image, ImageDraw, ImageFont
import numpy as np
import time
from MTCNN_facetest.video_detect import Detector
import os
import cv2
class Arcsoftmax(nn.Module):
def __init__(self, feature_num, cls_num):
super().__init__()
self.w = nn.Parameter(torch.randn((feature_num, cls_num)),requires_grad=True) #nn.Parameter将一个不可训练的类型Tensor转换成可以训练的类型parameter并将这个parameter绑定到这个module里面
self.func = nn.Softmax() #二分类
def forward(self, x, s=64, m=0.5): #s=64, m=222.5为超参数m为弧度
x_norm = F.normalize(x, dim=1)
w_norm = F.normalize(self.w, dim=0) #传入的参数nn.Parameter在0维上进行标准化
cosa = torch.matmul(x_norm, w_norm) / s #torch.matmul二维的点成,高维的矩阵乘法
a = torch.acos(cosa)
arcsoftmax = torch.exp(
s * torch.cos(a + m)) / (torch.sum(torch.exp(s * cosa), dim=1, keepdim=True) - torch.exp(
s * cosa) + torch.exp(s * torch.cos(a + m))) #代码实现公式
return arcsoftmax
class FaceNet(nn.Module):
def __init__(self):
super(FaceNet, self).__init__()
self.sub_net = nn.Sequential(
models.mobilenet_v2(), #导入mobilenet_v2
)
self.feature_net = nn.Sequential(
nn.BatchNorm1d(1000),
nn.LeakyReLU(0.1), #0.1指的是leakRelu负半轴的倾斜角
nn.Linear(1000, 512, bias=False),
)
self.arc_softmax = Arcsoftmax(512, 112)
def forward(self, x):
y = self.sub_net(x) #y是原本的mobilenet_v2()的输出值
feature = self.feature_net(y) #self.feature_net网络导数第二层
return feature, self.arc_softmax(feature) #前向推理返回的是特征和arc_softmax分类
def encode(self, x):
return self.feature_net(self.sub_net(x)) #返回的是倒数第二层的值
def compare(face1, face2):
face1_norm = F.normalize(face1) #对传入的人脸进行标准化
face2_norm = F.normalize(face2)
cosa = torch.matmul(face1_norm, face2_norm.T) #矩阵乘法
# cosb = torch.dot(face1_norm.reshape(-1), face2_norm.reshape(-1))
return cosa
if __name__ == '__main__':
# 使用
net = FaceNet().cuda()
net.load_state_dict(torch.load(path)) #path指的是face.py文件中保存的参数的路径
net.eval()
persons_name = [] #建立不同人物的名字(文件夹名)
persons_faces = [] #建立人脸库的列表
file_path = r"C:\Users\Administrator\Desktop\Faces" #人脸存放路径
for person in os.listdir(file_path): #遍历每一个人脸文件夹
person_face = [] #用来同一个人的不同的人脸特征(一个人获取的可能不止一张照片)
persons_name.append(person) #存放人的名字
for face in os.listdir(os.path.join(file_path, person)): #人脸照片转换为特征
person_picture = tf(Image.open(os.path.join(file_path,person,face))).cuda()
person_feture = net.encode(person_picture[None, ...]) #获取编码后的每一个人的脸部特征
feature = person_feture.detach().cpu() #将脸部特征转到CPU上,节省GPU的计算量
person_face.append(feature) #将同一个人脸的不同人脸特征存放到同一个列表中
persons_faces.append(person_face) #将不同人的脸部特征存放到同一个列表中
font_path = r"C:\Windows\Fonts\simhei.ttf" #设置字体的路径
font1 = ImageFont.truetype(font_path, 19, encoding="utf-8") #设置字体的格式
cap = cv2.VideoCapture(0) #读取视频流
cap.set(4, 720) #设置读取的视频的宽和高
cap.set(3, 480)
fps = int(round(cap.get(cv2.CAP_PROP_FPS))) #帧率
w = int(cap.get(3))
h = int(cap.get(4))
while True:
t1 = time.time() #计时器
ret, im = cap.read()
if cv2.waitKey(int(1000 / fps)) & 0xFF == ord("q"):
break
elif ret == False:
break
im = cv2.cvtColor(im, cv2.COLOR_BGR2RGB) #特征对比之前先转换通道,因为OpenCV读取的通道格式是BGR
im = Image.fromarray(np.uint8(im)) #转为PIL类型
with torch.no_grad() as grad: #此处不用梯度
detector1 = Detector() #MTCNN人脸检测器实例化
boxes = detector1.detect(im) #读取到的视频流传入检测器中
for box in boxes: #检测到的人脸的四个坐标值
x1 = int(box[0])
y1 = int(box[1])
x2 = int(box[2])
y2 = int(box[3])
im = Image.fromarray(np.uint8(im)) #从numpy转为PIL类型
if type(im) is np.ndarray: #读取到的图像有时会报类型错误,if,else避免报错
im = Image.fromarray(np.uint8(im))
cropped = im.crop((x1, y1, x2, y2)) #使用PIL对图像进行裁剪
draw = ImageDraw.Draw(im) #在图像上画出目标框
draw.rectangle([x1, y1, x2, y2], outline=(255, 0, 0))
else:
cropped = im.crop((x1, y1, x2, y2))
draw = ImageDraw.Draw(im)
draw.rectangle([x1, y1, x2, y2], outline=(255, 0, 0))
person1 = tf(cropped).cuda() #将MTCNN裁剪出来的图片归一化并且传入cuda
person1_feature = net.encode(person1[None, ...]) #获取到处理后的视频人脸的特征
persons_saims = [] #建立一个空列表用来存放不同人的脸部特征与视频人脸特征的余弦相似度
for personal_face in persons_faces: #遍历不同人的不同人脸特征
siams = [] #建立一个列表存放同一个人的不同脸部特征与视频人脸的相似性
for fface in personal_face: #遍历同一个人的不同的人脸特征
person2_feature = fface.cuda() #将人脸特征传入cuda
siam = compare(person1_feature, person2_feature) #与一个人的一张人脸特征做比较
im = np.array(im).astype('uint8') #转为uint8类型
siams.append(siam.item()) #同一个人的所有脸特征与当前视频人脸的余弦相似度
personal_max = max(siams) #选择最大的余弦相似度
persons_saims.append(personal_max) #取相似性最高的(同一个人的不同人脸特征中与视频人脸作对比,取出最大的余弦相似度)
sia = max(persons_saims) #将不同人的脸部特征与视频人脸对比出的最大的相似度存放在列表中(此时是本地库有几个人就有几个相似度)
indx = persons_saims.index(sia) #确定最大的相似的人脸的索引位置
obj_name = persons_name[indx] #索引对应目标人物的名字
if sia > 0.2: #当相似度大于某个值时才显示name和相似度
img = cv2.putText(im, str(float("%.2f" % sia)), (x1, y1),
cv2.FONT_HERSHEY_SIMPLEX, 0.6,
(0, 255, 0), 2) # 在图像上写最大相似度
img = cv2.putText(img, str(obj_name), (x1, int((y1 + 15))),
cv2.FONT_HERSHEY_SIMPLEX, 0.6, (255, 0, 0),2) # 写上最大相似度的标签(最像谁)
else:
im = Image.fromarray(im)
draw = ImageDraw.Draw(im)
draw.text((x1, int(y1 + 15)), "此人可能来自火星!!", (255, 0, 0), font=font1)
im = cv2.cvtColor(np.uint8(im), cv2.COLOR_RGB2BGR) #展示视频流前转换通道
cv2.imshow("", np.uint8(im)) #展示视频
t2 = time.time() #计时器
print(1 / (t2 - t1)) #展示每秒帧数直接运行face_discern_video.py就可以看到实验结果了^……^!!
测试结果如下(原本是视频的,不方便展示,就放一张与视频检测效果类似的照片):

十一、试验小结:
1、在试验过程中:数据的质量尤其重要!!!
1.在训练特征提取器的过程中,要尽量保持训练样本最好只包含人脸,含有的背景信息越多训练的难度也会加大,对数据的需求量也会增多,当数据质量较高时只需要很少的样本就可以达到不错的效果
2.在测试过程中,最好是保持当前的测试环境和人脸特征库中的环境保持一致,如果不一致可以在使用测试的时候进行调整,如利用opencv等工具进行饱和度,亮度等方面的调整
3.会存在这样的情况:训练的照片是高清图片,测试时由于摄像头硬件设备的原因,侦测的人脸相对较为模,那么原本的特征提取器是基于高清图片训练出来的,检测模糊图片时可能精度会下降,此时解决方法:1、最好是更换设备,2、也可以对特征提取器的训练样本进行模糊处理,就可以保持训练和测试在类似的清晰度了。
2、在训练过程中可以根据不同的轮次调整不同的优化器和学习率
在开始的前几轮可以使用Adam优化器进行训练,学习率可以大一点(收敛更快)
几轮后可以使用SGD等优化器(Adam优化器震荡比较大,接近最低点使用SGD优化效果比较好)















 678
678











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









