









字符编码
零、引言
关于字符编码的概念会在具体些程序的时候,高频的出现。非常有必要了解其意义以及其具体的原理。本文会介绍ASCII、Unicode以及它的编码方式UTF-8和代码页。
一、ASCII
我们就从最简单的ASCII入手,因为这个是在编程初期就会碰到的编码方式。对于ASCII的背景历史就不在这里赘述。有兴趣的读者可以google或者百度,上面都有详细的介绍。
ASCII是单字节编码方式,就是它只用一个字节中的前7位存放字符。所以一个字节可以包含2^7 = 128种字符。看上去好像是太少了,但是对于只使用英语的话就完全足够了。
这里举几个例子来说明这种编码方式。
比如字母‘A’,它的ASCII编码是65,展开它的二进制编码(01000001)。
比如字母‘B’,它的ASCII编码是66,展开它的二进制编码(01000010)。
这里的英文字符A到Z的ASCII编码是65到90。其小写字母a到z的ASCII编码是97到122。
数字0到9的ASCII编码是48到57。再加上一些符号,是不是对于只使用英文的用户来说完全够用了。
当然ASCII其中还有一些不可见的控制符。这些可以具体查看完整地ASCII表。
二、Unicode
在介绍ASCII的时候,我们一直强调其用户面对英文使用者。但是现实的情况并不是这么简单,比如中文用户、韩文用户、日文用户等等。对于这些用户一个一个字节根本放不下这么多语言。所以有了Unicode这种几乎支持地球上所有字符的字符集。
当然这里也不介绍Unicode的背景历史。
Unicode编码方式,使用两个字节存放字符。这样就有2^16 = 65536个字符可以存放,基本也能满足存放世界上所有语言的字符。
上述的两个字节构成所谓的基本多文种平面(Basic Multilingual Plane 简称BMP)。除了这个BMP还有16个辅助平面(Supplementary Plane)。
我们来看一下这个所谓的多文种平面
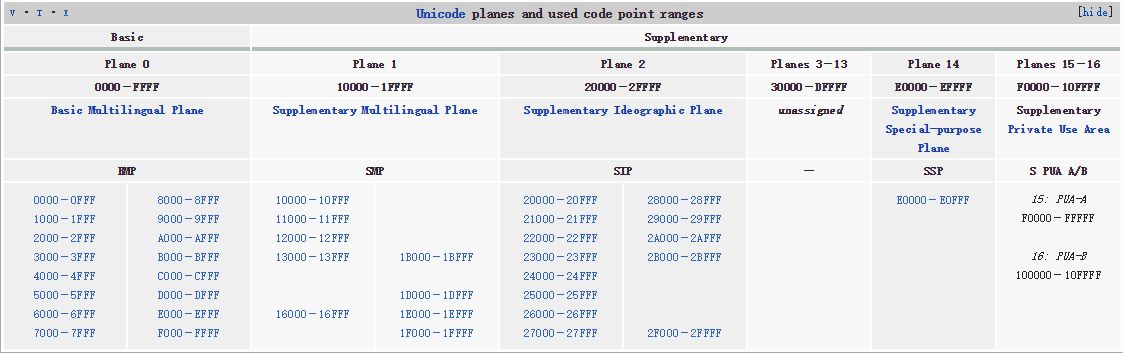
图2.1
0xhhhhhhhh,这里是4个字节,总共32位。这四个字节组成上诉的17个多文种平面。其中0x0~0xFFFF的构成构成第一个平面BMP。其中一开始的两个字节构成序号0x00~0x10。从0到16分别标识这17个平面。
而世界上大部分语言都在第一个平面BMP里。所以我们通常使用的Unicode都只用了2个字节足够了。
对于上面的多文种平面不是很清楚也没关系,这个不影响下面的阅读。我们现在来看一下我们关心的中文在Unicode中的情况。
中文在Unicode中的编码范围在4E00-9FBF,完全落在了0x00~0xFFFF第一个基本平面里。
好了,我们具体举一个例子。
“中国“,这两个中文字的Unicode编码就是u4E2D,u56FD。
Unicode这里就先介绍这点。下面看一下UTF-8这个熟悉的概念。
三、UTF-8
在介绍UTF-8之前,有一些概念需要明确。首先前面提到的Unicode是一个字符集或者说符号集。就是说它为所有的符号规定了二进制编码。就像“中国“就是u4E2D和u56FD。每一个字符或者符号在Unicode中都能找到其所对应的二进制编码。
而UTF-8、UTF-16和UTF-32都是Unicode的实现方式。
我们再来看一下UTF-8的编码方式。
UTF-8用1到4个字节来存放字符。所以它是一种变长的编码方式。
1. 对于单字节的字符,其存放方式按照ASCII的存放方式。
2. 对于n字节的字符,第一个字节的前n位都是1,第n+1位恒为0,后面的字节的前两位恒位10。然后将字符的二进制位逐位填上。
那么如何判断一个字符需要多少字节呢?UTF-8给出了一个范围。
| 字节数 | 范围 | 格式 |
| 1字节 | 0x~0x7F | 0xxxxxxx |
| 2字节 | 0x80~0x7FF | 110xxxxx 10xxxxxx |
| 3字节 | 0x800~0xFFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| 4字节 | 0x10000~0x10FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
好了可能有点迷糊。我们还是具体举一个例子来说明UTF-8这种编码方式。
还是举“中国“,这两个字符。(多么爱国!!!)
中u4E2D,它落在了3字节的范围里。那么它的二进制格式应该是这样的,
1110xxxx 10xxxxxx 10xxxxxx。然后我们展开u4E2D,01001110 00101101。
然后依次填入上面的二级制格式中,把x替换掉。就会变成:11100100 10111000 10101101。转换成16进制便是:0xE4B8AD。
同样方法可以获得“国“的UTF-8码:0xE59BBD。
四、代码页
代码页,可以说就是编码方式。如果一个代码页是65001(微软windows环境下),那么它就是UTF-8编码方式;936便是GB中文编码。
五、编码转换
我们已经了解了编码的一些原理上的东西,现在一个问题便是如何在写程序中怎么去转换它们。这里我就讨论windows下C++的编码转换。
在转换编码的时候我们会用到下面两个函数:WideCharToMultiByte和MultiByteToWideChar。
int WideCharToMultiByte(
_In_ UINT CodePage,
_In_ DWORD dwFlags,
_In_ LPCWSTR lpWideCharStr,
_In_ intcchWideChar,
_Out_opt_ LPSTR lpMultiByteStr,
_In_ intcbMultiByte,
_In_opt_ LPCSTR lpDefaultChar,
_Out_opt_ LPBOOL lpUsedDefaultChar
);先介绍一下WideCharToMultiByte函数,这个函数主要作用是将UTF-16编码的字符串转换成其他编码方式的字符串。
1. CodePage,在转换的指定代码页;
2. dwFlags,指定转换类型,这个参数在这里我们都传入0(原因可以具体可以去查看MSDN对于这个函数的说明);
3. lpWideCharStr,一个指向待转的Unicode字符串的指针;
4. cchWideChar,待转字符串的长度,如果传入的字符串是以null结尾的话,可以设置成-1
如果这个参数是-1,该函数将会处理整个传入字符串包括null结束符;
5. lpMultiByteStr,转换结果存放的Buf;
6. cbMultiByte,第五个参数的大小;
7. lpDefaultChar,如果在转化过程中,指定代码页中没有指定的字符,那么就会用到这个指针指向的字符集;如果该参数设定为NULL,那么就会使用系统默认的字符。
8. lpUsedDefaultChar,用于判断函数是否使用默认字符。
返回值:如果成功则返回写入lpMultiByte中的字节数。
下面我们还是用一个具体的例子来说明这个函数。
wchar_t str[] = L"中国";
BOOL bUseDefaultChar = FALSE;
int len = WideCharToMultiByte(CP_UTF8,0,str,-1,NULL,0,NULL,FALSE);
char * strRes = new char[len];
memset(strRes, 0, sizeof(char)*len);
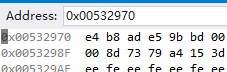
WideCharToMultiByte(CP_UTF8, 0, str, -1, strRes, len, NULL, FALSE);第一次调用WideCharToMultiByte是为了计算输出字符串的大小。真正的转换在第二次调用中。转换完成之后可以查看strRes的结果便是:
六、结尾
本文是博主查看了许多资料并结合自己在编程时遇到一些问题而写成的。刚开始查到编码的资料仔细一看,才发现以前对字符编码转换时多么无知甚至在使用中还是错误的使用。
所以对于一些基础性质的概念还是需要多加了解。















 1713
1713

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









