







文章排名包括两个阶段:文章检索和文章重排序,这对信息检索(IR)领域的学术界和业界来说都是重要而具有挑战性的课题。然而,常用的文章排名数据集通常集中在英语语言上。对于非英语场景,如中文,现有的数据集在数据规模、细粒度相关性注释和假阴性问题方面受到限制。为了解决这个问题,我们引入了T2排名,一个大规模的中国通过排名基准。T2排名包括超过300K的查询和超过200万个独特的段落,来自现实世界的搜索引擎。专家注释者被招募来为查询通道对提供4级分级的相关性评分(细粒度),而不是二进制的相关性判断(粗粒度)。为了缓解假阴性问题,在执行相关性注释时,会考虑更多具有更高多样性的段落,特别是在测试集中,以确保更准确的评估。除了文本查询和通道数据外,还提供了其他辅助资源,如查询类型和文档的XML文件哪些段落被产生,以促进进一步的研究。为了评估数据集,实现了常用的排名模型,并在T2排名上进行了测试。实验结果表明,T2排名具有挑战性,仍有改进的空间。
一、资料
论文
https://arxiv.org/pdf/2304.03679.pdf
中文论文摘取
SIGIR 2023 | 30万真实查询、200万互联网段落,中文段落排序基准数据集发布 - 掘金
github地址
GitHub - THUIR/T2Ranking: T2Ranking: A large-scale Chinese benchmark for passage ranking.
二、测试数据规模与质量
200w条段落数据
30w条查询数据
数据经过处理,去除了一些干扰数据。并且由全职标注人员,人工标注过,标注了query个相关段落的相关性
三、都有哪些测试数据集
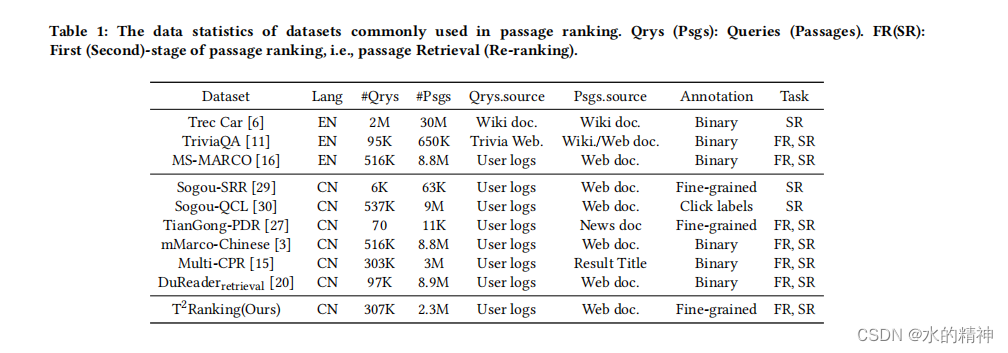
为了支持段落排名研究,我们构建了各种基准数据集。其中一些任务同时支持第一阶段检索(FR)和第二阶段重新排序(SR)任务,而另一些任务则专注于SR任务。我们在表1中总结了一些常见数据集的数据统计数据。常用的数据集侧重于英语场景。例如,Trec复杂答案检索(Car)[6],TriviaQA [11]和MS-MARCO [16]。其中,MS-MARCO是一个拥有880万条通道的大规模数据集。这些查询是基于问题的,并且人工生成的答案由注释器提供。随后,通过确定段落中是否存在与查询相关的答案,可以获得二元相关性得分;即,包含答案的段落为相关的(1),而不相关的段落为不相关的(0)。随着MS-MARCO的成功,在非英语社区中也构建了类似的数据集,比如华人。例如,mMarco-中文[3]是借助机器翻译的中文版本。数据检索[20]采用了类似的范式,从人类生成的答案中为查询-通道对生成二元相关性判断。Multi-CPR [15]是一个用于通道检索的多领域中文数据集,具有三个不同的领域和一定数量的人工注释的查询-通道对。此外,搜狗-SRR[29]搜狗-QCL[30]和TianGong-PDR [27]是基于中国热门搜索引擎搜狗2的用户日志提供的。
四、数据集发布团队介绍
该数据集由清华大学计算机系信息检索课题组(THUIR)和腾讯公司 QQ 浏览器搜索技术中心团队共同发布,得到了清华大学天工智能计算研究院的支持。THUIR 课题组聚焦搜索与推荐方法研究,在用户行为建模和可解释学习方法等方面取得了典型成果,课题组成果获得了包括 WSDM2022 最佳论文奖、SIGIR2020 最佳论文提名奖和 CIKM2018 最佳论文奖在内的多项学术奖励,并获得了 2020 年中文信息学会 “钱伟长中文信息处理科学技术奖” 一等奖。QQ 浏览器搜索技术中心团队是腾讯 PCG 信息平台与服务线负责搜索技术研发的团队,依托腾讯内容生态,通过用户研究驱动产品创新,为用户提供图文、资讯、小说、长短视频、服务等多方位的信息需求满足。
五、国内下载
会发现从huggingface上,因为网络原因下载不到。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









