







集合的由来:
当我们存放多个对象时, 可以使用数组和集合。数组在初始化的时候是需要定义长度的,而且操作过程中不能修改数组长度的大小。 当我们不确定对象个数或中间需要动态添加或修改元素, 就需要用到集合。
集合的特点
1,用于存储对象的容器。
2,集合的长度是可变的。
3,集合中不可以存储基本数据类型值。(集合中存放的是对象的引用,实际内容都在堆上面或者方法区里面,现在基本数据类型都有了其对应的封装的对象,当把基本数据类型存入集合中,系统会自动将其装箱成封装类)
1 集合框架说明
Java平台集合框架的核心接口为Collection、List(列表)、Set(集合)和Map(映射)。

Collection是集合继承树中最顶层的接口,几乎所有的Java集合框架成员都继承实现了Collection接口,或者与其有密切关系。Collection提供了关于集合的通用操作。Set接口和List接口都继承了Collection接口,而Map接口没有继承Collection接口。因此,Set对象和List对象都可以调用Collection接口的方法,而Map对象则不可以。
接口对象的具体说明:
1 Collection:集合层次中的根接口,JDK 没有提供这个接口直接的实现类,主要子接口List, Set。(*Collection接口其实含父类接口Iterable ,该接口定义了返回Iterator对象的方法)
2 Iterator: 迭代器,定义了hasNext(),next(),remove()方法,集合Collection可以通过迭代器遍历操作元素。实现了Collection和子接口都可以通过迭代器操作元素
3 List: 列表,有序(存入和取出的顺序一致),元素都有索引(角标),可以通过角标操作元素并且元素可以重复。
4 Set: 无序(存入和读取的顺序不一定一致),并且元素不能重复
5 Map: 映射, 包含了 key-value 对。Map 不能包含重复的 key。
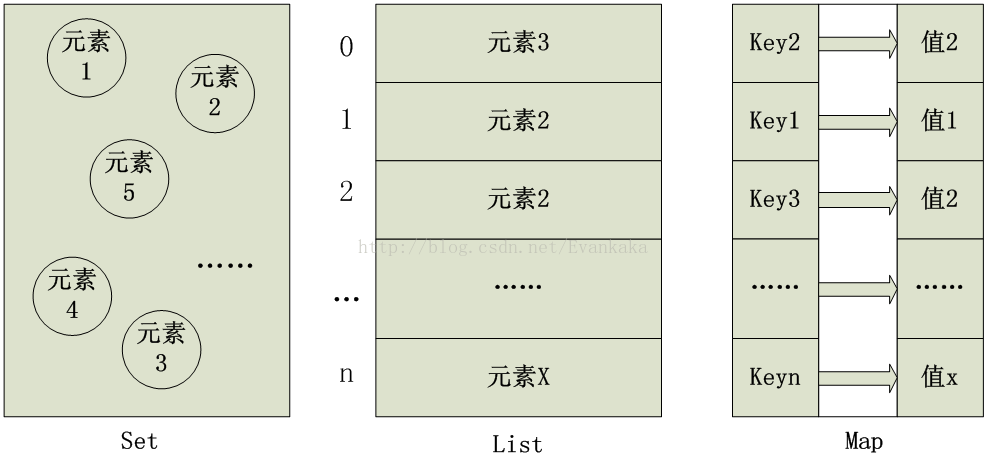
Set,List,Map 数据保存形式
2 Collection用法案例
Collection 不能实例化,我们实例化一个ArrayList。
package cjr;
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
public class CollectionDemo {
public static void main(String[] args) {
Collection<String> c=new ArrayList<String>();
c.add("1");
c.add("2");
c.add("3");
c.add(null);
c.add("2");
c.add("2");
System.out.println(c);
c.remove("2");
System.out.println(c);
System.out.println("=======遍历集合方式1=========");
Iterator<String> it=c.iterator();
while(it.hasNext()){
System.out.println(it.next());
}
System.out.println("=======遍历集合方式2=========");
for(String s : c){
System.out.println(s);
}
}
}
运行结果:
[1, 2, 3, null, 2, 2]
[1, 3, null, 2, 2]
=======遍历集合方式1=========
1
3
null
2
2
=======遍历集合方式2=========
1
3
null
2
2
[1, 3, null, 2, 2]
=======遍历集合方式1=========
1
3
null
2
2
=======遍历集合方式2=========
1
3
null
2
2
注:colllection可以添加多个重复元素, remove只移除一次该集合中元素
3 List总结
List的主要特征是可以通过角标操作元素,完成增删改查(Collection只能增删查),集合中允许存放重复对象。List接口主要的实现类包括:
(1)ArrayList:内部存储是数组数据结构。允许对元素进行快速的随机访问,但是向ArrayList中插入与删除元素的速度较慢。
(2)LinkedList :在实现中采用链表数据结构,元素之间是双链接。对顺序访问进行了优化,向List中插入和删除元素的速度较快,随机访问速度则相对较慢,随机访问是指检索位于特定索引位置元素。
(3)Vector :内部存储是数组数据结构,是ArrayList的线程安全版本,性能比ArrayList要低,现在已经很少使用。
(1)ArrayList:内部存储是数组数据结构。允许对元素进行快速的随机访问,但是向ArrayList中插入与删除元素的速度较慢。
(2)LinkedList :在实现中采用链表数据结构,元素之间是双链接。对顺序访问进行了优化,向List中插入和删除元素的速度较快,随机访问速度则相对较慢,随机访问是指检索位于特定索引位置元素。
(3)Vector :内部存储是数组数据结构,是ArrayList的线程安全版本,性能比ArrayList要低,现在已经很少使用。
List接口增加了通过角标操作集合的几个方法,具体如下:
(2)get(int index) 返回列表中指定位置的元素。
(4)remove(int index) 移除指定位置的元素
(5)size() 返回列表中的元素个数
ArrayList案例
package cjr;
import java.util.ArrayList;
public class ArrayListDemo {
public static void main(String[] args) {
ArrayList<String> lsStr = new ArrayList<String>();
lsStr.add("1");
lsStr.add("2");
lsStr.add("3");
lsStr.add(0, "0");
System.out.println(lsStr.get(2));
lsStr.set(2, "22");
System.out.println(lsStr.get(2));
System.out.println("============遍历List===============");
for(int i=0,size=lsStr.size();i<size;i++){
System.out.println(lsStr.get(i));
}
}
}运行结果:
2
22
============遍历List===============
0
1
22
3
4 Set
Set 中元素不可以重复且无序, 方法和父接口Collection一致。主要实现类HashSet,TreeSet。
(1)HashSet:内部数据结构是哈希表 ,是不同步的(非线程安全)。HashSet通过对象的hashCode和equals方法来完成对象唯一性,如果对象的hashCode值不同,那么不用判断equals方法,就直接存储到哈希表中;如果对象的hashCode值相同,那么要再次判断对象的equals方法是否为true;如果为true,视为相同元素,不存。如果为false,那么视为不同元素,就进行存储。
注:如果自定义对象要存储到HashSet集合中,必须覆盖hashCode方法和equals方法,建立对象判断是否相同的依据。
(2)TreeSet:可以对Set集合中的元素进行排序,是不同步的。TreeSet判断元素唯一性的方式:就是根据比较方法的返回结果是否为0,为0,就是相同元素,不存
注:TreeSet对自定义元素进行排序,主要有两种方式。
1 让元素自身具备比较功能,让元素实现Comparable接口,覆盖compareTo方法。
2 让集合自身具备比较功能。定义一个类实现Comparator接口,覆盖compare方法,将该类对象作为参数传递给TreeSet集合的构造函数。
(3)LinkedHashSet 同样是根据元素的hashCode值来决定元素的存储位置,但是它同时使用链表维护元素的次序。这样使得元素看起 来像是以插入顺序保存的,也就是说,当遍历该集合时候,LinkedHashSet将会以元素的添加顺序访问集合的元素。
注: LinkedHashSet在迭代访问Set中的全部元素时,性能比HashSet好,但是插入时性能稍微逊色于HashSet。
HashSet案例
自定义一个Person类,含name和age属性,将多个person对象存入HashSet , 当元素的name属性相同, 我们就认为同一个元素。 我需重写Person的hashCode 和 equal 方法。
package cjr;
import java.util.HashSet;
import java.util.Iterator;
public class HashSetDemo {
public static void main(String[] args) {
HashSet<Person> setPers = new HashSet<Person>();
setPers.add(new Person("刘备", 30));
setPers.add(new Person("关羽", 29));
setPers.add(new Person("张飞", 28));
setPers.add(new Person("关羽", 16));
Iterator<Person> itPers = setPers.iterator();
while (itPers.hasNext()) {
Person person = itPers.next();
System.out.println("Name:" + person.name +" ; Age:" + person.age);
}
}
}
class Person
{
String name;
int age;
public Person(String name,int age){
this.name = name;
this.age = age;
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + ((name == null) ? 0 : name.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Person other = (Person) obj;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name))
return false;
return true;
}
}运行结果:
Name:关羽 ; Age:29
Name:刘备 ; Age:30
Name:张飞 ; Age:28
Name:刘备 ; Age:30
Name:张飞 ; Age:28
从运行结果中, 可以看出, 当HashSet遇到重复元素, 不会进行覆盖操作, 而是直接忽略存储。
6 Map
Collection 一次添加一个元素,Map一次添加一对元素(即一个键值对)。因此Collection集合称为单列集合,Map也称为双列集合。Map中健必须保持唯一,当健重复添加时, 新的一组键值对会覆盖原来的键值对。
Map的常用方法:
(1)value put(key,value):返回前一个和key关联的值,如果没有返回null.
(2)void clear():清空map集合。
(3)value remove(key):根据指定的key翻出这个键值对。
(4)boolean containsKey(key)
boolean containsValue(value)
boolean isEmpty()
(5)value get(key):通过键获取值,如果没有该键返回null。
(6)int size(): 获取键值对的个数。
Map常用的子类有,Hashtable,HashMap,TreeMap
Hashtable :内部结构是哈希表,是同步的。不允许null作为键,null作为值。
HashMap : 内部结构是哈希表,不是同步的。允许null作为键,null作为值。
TreeMap : 内部结构是二叉树,不是同步的。可以对Map集合中的键进行排序。
HashMap案例
<pre name="code" class="java">package cjr;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
public class HashMapDemo {
public static void main(String[] args){
HashMap<String, String> mapStr = new HashMap<String, String>();
mapStr.put("first","刘备");
mapStr.put("second", "关羽");
mapStr.put("third", "张飞");
mapStr.put("second", "关云长");
System.out.println("===================通过Map.keySet遍历key和value:===================");
for (String key : mapStr.keySet()) {
System.out.println("key= " + key + " ; value= " + mapStr.get(key));
}
System.out.println("===================通过Map.entrySet使用iterator遍历key和value:===================");
Iterator<Map.Entry<String, String>> it = mapStr.entrySet().iterator();
while (it.hasNext()) {
Map.Entry<String, String> entry = it.next();
System.out.println("key= " + entry.getKey() + " ; value= "
+ entry.getValue());
}
System.out.println("===================通过Map.entrySet遍历key和value:===================");
for (Map.Entry<String, String> entry : mapStr.entrySet()) {
System.out.println("key= " + entry.getKey() + " ; value= "
+ entry.getValue());
}
}
}
运行结果:
===================通过Map.keySet遍历key和value:===================
key= second ; value= 关云长
key= third ; value= 张飞
key= first ; value= 刘备
===================通过Map.entrySet使用iterator遍历key和value:===================
key= second ; value= 关云长
key= third ; value= 张飞
key= first ; value= 刘备
===================通过Map.entrySet遍历key和value:===================
key= second ; value= 关云长
key= third ; value= 张飞
key= first ; value= 刘备
key= second ; value= 关云长
key= third ; value= 张飞
key= first ; value= 刘备
===================通过Map.entrySet使用iterator遍历key和value:===================
key= second ; value= 关云长
key= third ; value= 张飞
key= first ; value= 刘备
===================通过Map.entrySet遍历key和value:===================
key= second ; value= 关云长
key= third ; value= 张飞
key= first ; value= 刘备
从运行结果,可以看到Map遇到key重复数据, 会直接覆盖。 而Set遇到两个元素相同,则不再存储第二个元素。
7 Collections集合工具类
Collections是Java为操作集合提供的相关工具类。个人觉得相关作用不大, 实际情况中用到的比较少。现列举几个可能用到的方法。
(2)
disjoint(Collection<?> c1, Collection<?> c2) 如果两个指定 collection 中没有相同的元素,则返回 true。
(4)frequency(Collection<?> c, Object o) 返回指定 collection 中等于指定对象的元素数。
(5)
max(Collection<? extends T> coll) 根据元素的自然顺序,返回给定 collection 的最大元素。
max(Collection<? extends T> coll, Comparator<? super T> comp) 根据指定比较器产生的顺序,返回给定 collection 的最大元素。
(6)replaceAll(List<T> list, T oldVal, T newVal) 使用另一个值替换列表中出现的所有某一指定值。
sort(List<T> list, Comparator<? super T> c) 根据指定比较器产生的顺序对指定列表进行排序。
(10)
synchronizedCollection(Collection<T> c) 返回指定 collection 支持的同步(线程安全的)collection。















 1110
1110

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









