







1. 安装scrapy爬虫框架
命令行pip install scrapy
.
一般会出现twisted安装失败的信息,原因是没有获取正确的windows版本,这时候到https://www.lfd.uci.edu/~gohlke/pythonlibs/ 下载twisted,打开链接后直接ctrl+F搜索Twisted,下载对应版本,比如我是64位Windows

然后到下载目录cmd执行:pip install Twisted‑18.7.0‑cp36‑cp36m‑win_amd64.whl
之后再次执行pip install scrapy即可,如果有其他安装不上的,自己下载安装包,操作如上。
2.使用scrapy爬取简书专题信息
(1)爬取内容分析
https://www.jianshu.com/recommendations/collections?utm_medium=index-collections&utm_source=desktop
需求:爬取该页的热门专题信息,包括标题、简介、文章数、关注数。
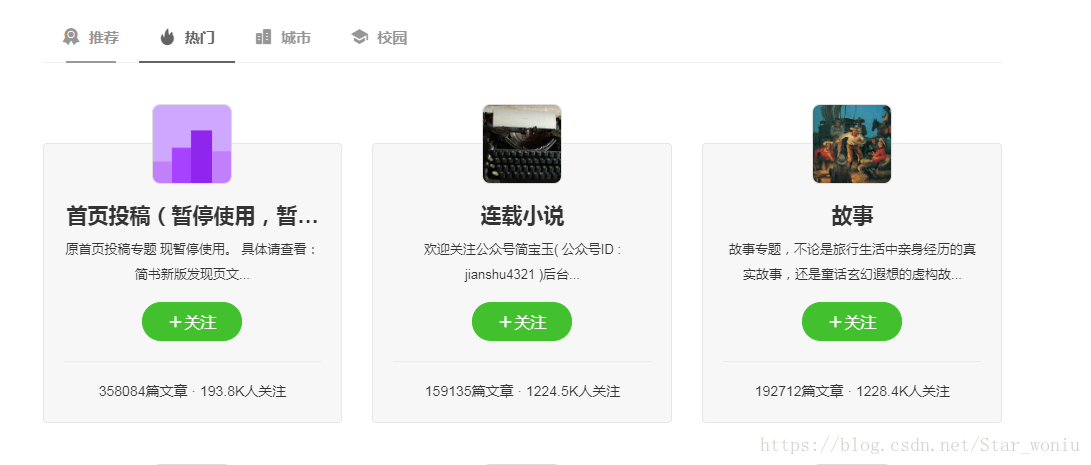
拉到最底下可以看到加载更多,点击之后并没有刷新界面而是直接加载出来了,证明这部分内容使用的是ajax异步加载。
如何获取异步加载链接?
使用F12(或者ctrl+shift+i)打开谷歌自带的工具,切换到network栏目,
点击网页最底下的加载更多按钮,发现network的name那一栏出现新的链接:

多重复几次会发现在框出的2的位置会递增,所以每次加载我们只要修改链接的数字就行
接下来使用谷歌工具的选取功能,分析如何获取想要的数据

点击标题部分
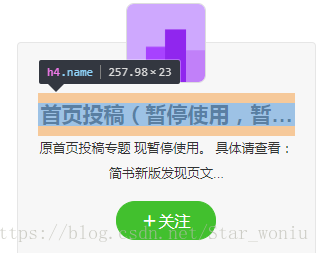
工具栏会出现对应的代码

右键高亮处选择Copy->Copy XPath,多个要获取的内容依次得到如下信息
//*[@id="list-container"]/div[1]/div/a[1]/h4
//*[@id="list-container"]/div[1]/div/a[1]/p
//*[@id="list-container"]/div[1]/div/div/a
//*[@id="list-container"]/div[1]/div/div/text()
可以直接使用这个相对路径获取信息,观察也可发现这几部分都在class="collection-wrap"的div下

所以也可以使用这个div的相对路径获取。
3.创建工程及编写代码
进入工程目录输入scrapy startproject + 工程名字,创建工程
打开工程目录

分析下目录结构(红框处为自建文件),主要文件有四个:
(1)items.py 定义爬取字段
(2)piplines.py 爬虫数据处理,入库
(3)setting.py 项目设置
(4)jianshuspider.py 用户自建文件,编写爬虫逻辑
代码部分不做详解,直接上,
items.py代码:
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
from scrapy.item import Item,Field
class JianshuItem(Item):
# define the fields for your item here like:
# name = scrapy.Field()
name = Field()
content = Field()
article = Field()
fans = Field()(2)piplines.py(使用Mongodb数据库,没有的话可以直接写到txt文件里)
使用数据库:
import pymongo
class JianshuPipeline(object):
def __init__(self):
client = pymongo.MongoClient('localhost', 27017)
mydb = client['mydb']
jianshu = mydb['jianshu']
self.post = jianshu
def process_item(self, item, spider):
info = dict(item)
self.post.insert(info)
return item使用txt文件:
class XiaozhuPipeline(object):
def process_item(self, item, spider):
fp = open('F:/wxx/testpycode/jianshu/jianshu/jianshu.txt','a+')#文件路径自己改
fp.write(item['name']+'\n')
fp.write(item['content']+'\n')
fp.write(item['article']+'\n')
fp.write(item['fans']+'\n')
fp.close()
return item(3)setting.py
BOT_NAME = 'jianshu'
SPIDER_MODULES = ['jianshu.spiders']
NEWSPIDER_MODULE = 'jianshu.spiders'
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.92 Safari/537.36'#设置代理
ROBOTSTXT_OBEY = False
DOWNLOAD_DELAY = 3#设置爬虫每一页的间隔
ITEM_PIPELINES = {
'jianshu.pipelines.JianshuPipeline': 300,
}
(4)jianshuspider.py
from scrapy.spiders import CrawlSpider
from scrapy.selector import Selector
from scrapy.http import Request
from jianshu.items import JianshuItem
class jianshu(CrawlSpider):
name = 'jianshu'
start_urls = ['https://www.jianshu.com/recommendations/collections?page=1&order_by=hot']
def parse(self,response):
item = JianshuItem()#创建对象
selector = Selector(response)
infos = selector.xpath('//div[@class="collection-wrap"]')#同一个div下的数据
for info in infos:#获取数据
name = info.xpath('a[1]/h4/text()').extract()[0]
content = info.xpath('a[1]/p/text()').extract()
article = info.xpath('div/a/text()').extract()[0]
fans = info.xpath('div/text()').extract()[0]
if content:
content = content[0]
else:
content = ''
item['name'] = name
item['content'] = content
item['article'] = article
item['fans'] = fans
yield item
urls = ['https://www.jianshu.com/recommendations/collections?page={}&order_by=hot'.format(str(i)) for i in range(2,21)]#配置链接,只爬取20页
for url in urls:
yield Request(url, callback=self.parse)(5)main.py
from scrapy import cmdline
cmdline.execute('scrapy crawl jianshu'.split())#调用命令行,也可以不创建该文件,直接在工程目录使用命令行执行scrapy crawl jianshu执行main.py即可得到结果,结果打印,数据库也会插入相应的数据

以上所有知识来源于网易云课堂《看文档学爬虫》,干货满满的视频课,只是整理总结了一下,有误请纠正,互相学习谢谢~!














 845
845











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









