







Netty源码解读之底层原理
Netty源码编译
版本:4.1.40.Final-SNAPSHOT
编译 Netty 常遇问题
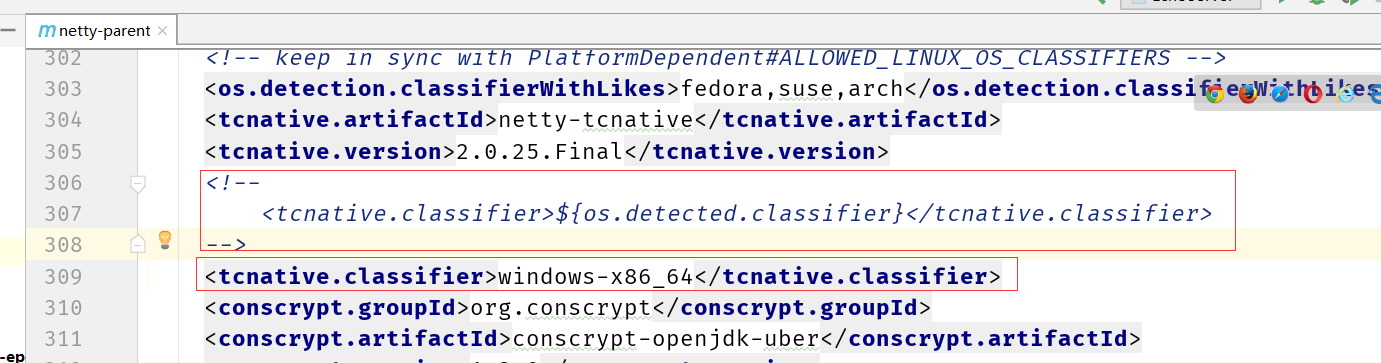
重新编译一次
Netty 源码核心包
1、工具类:
2、底层协议(transport)
TCP的不同实现(linux(epoll)、Mac(kqueue),unix)
3、人性化协议
包括编解码codec、还有handler

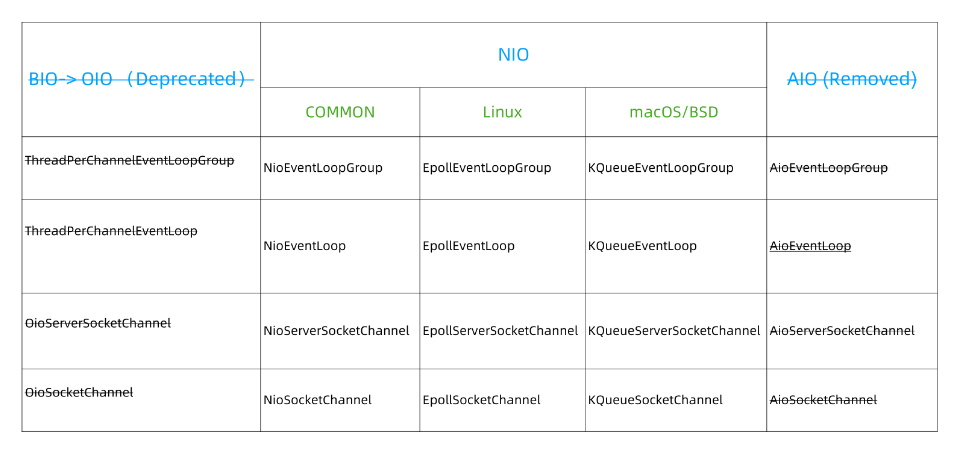
Netty对三种I/O 模式的支持
Netty对BIO,NIO,还有AIO,BIO也称之为OIO(已被弃用)。
AIO也进行了相关的移除。
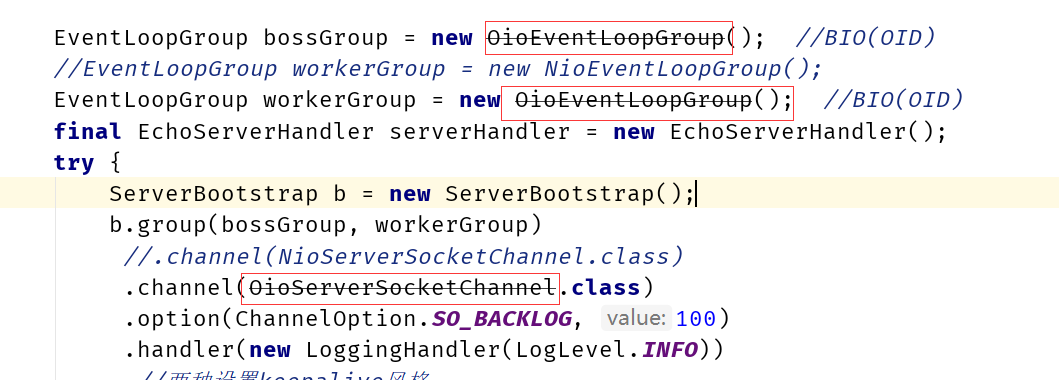
但是我们还是来看下Netty是如何做到对三种I/O模式的切换。
代码比较简单:
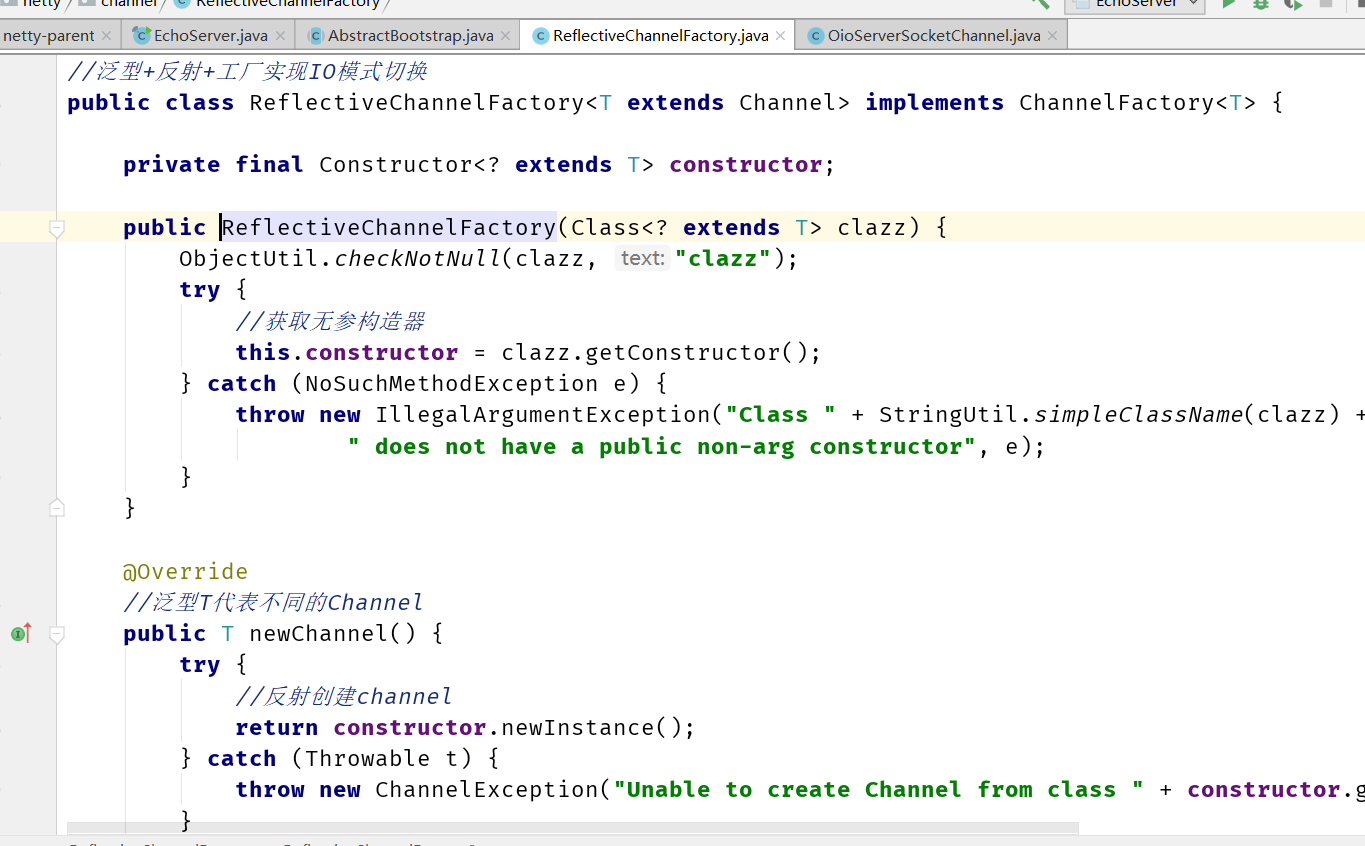
ServerSocketChannel:工厂模式+泛型+反射实现
Netty对Reactor模式的支持
Reactor 是一种开发模式,模式的核心流程:
注册感兴趣的事件 -> 扫描是否有感兴趣的事件发生 -> 事件发生后做出相应的处理
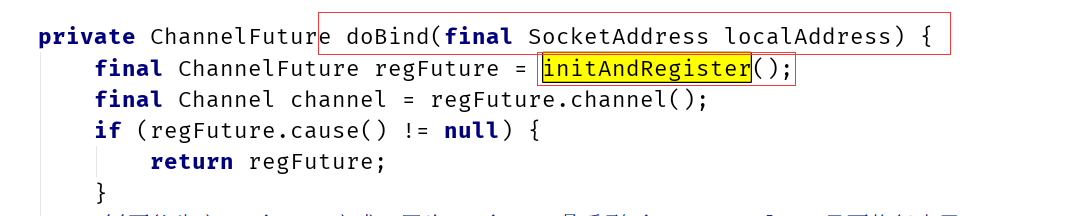
NioEventLoop.run()

mainReactor

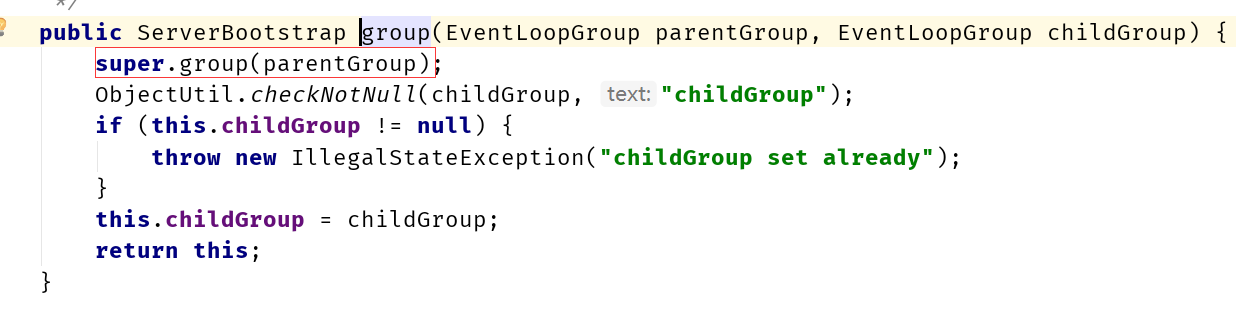




这里只会调用一次,也就是这里一般也只会有一个线程
subReactor
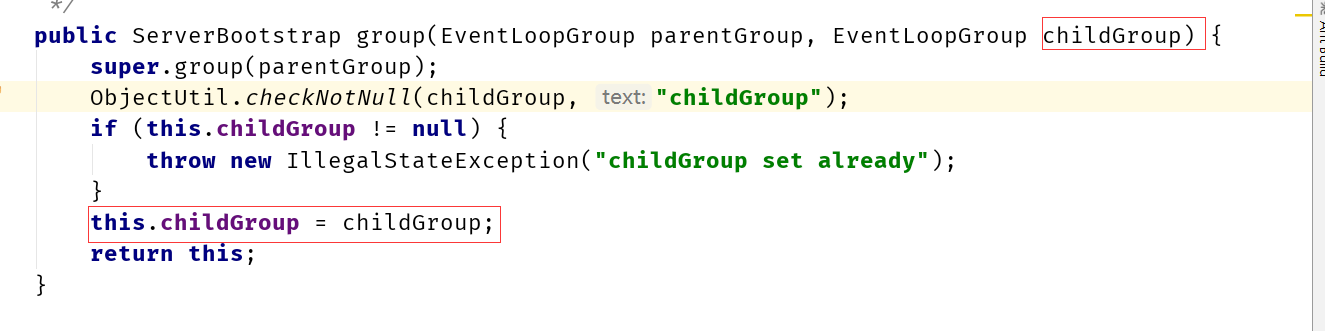
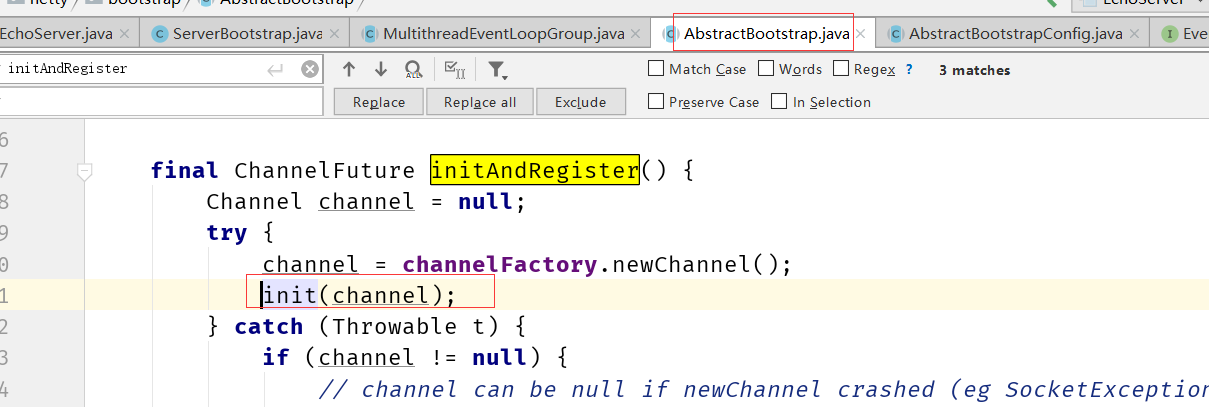
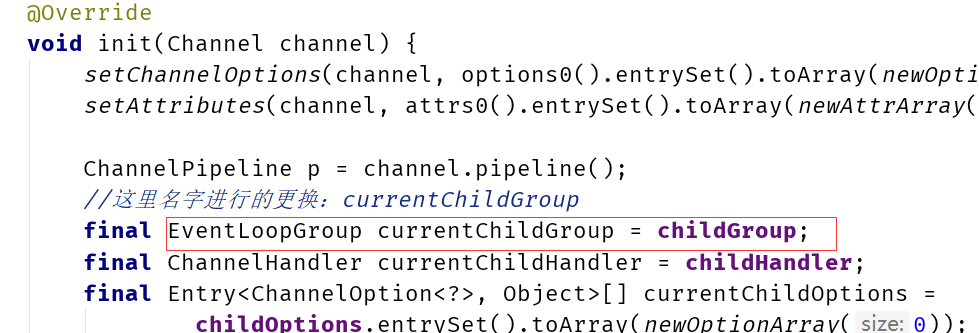
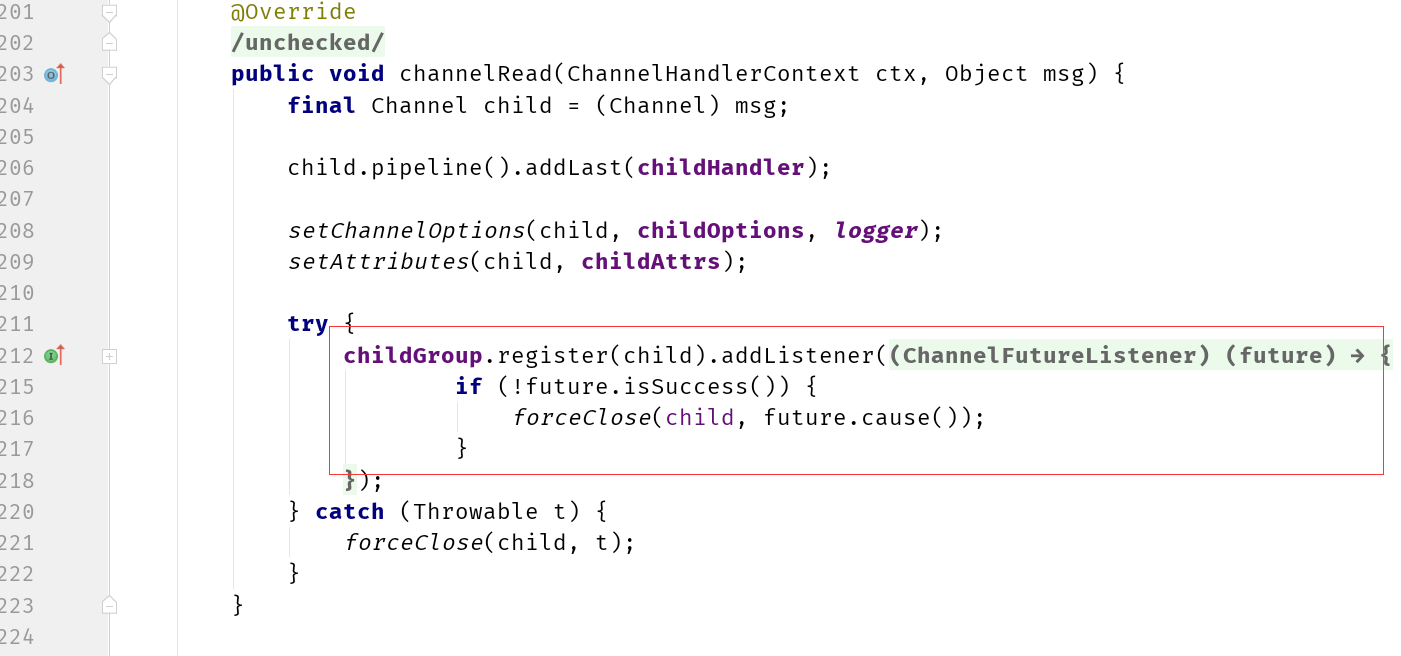
Netty 给 Channel 分配 NIO event loop 的规则是什么
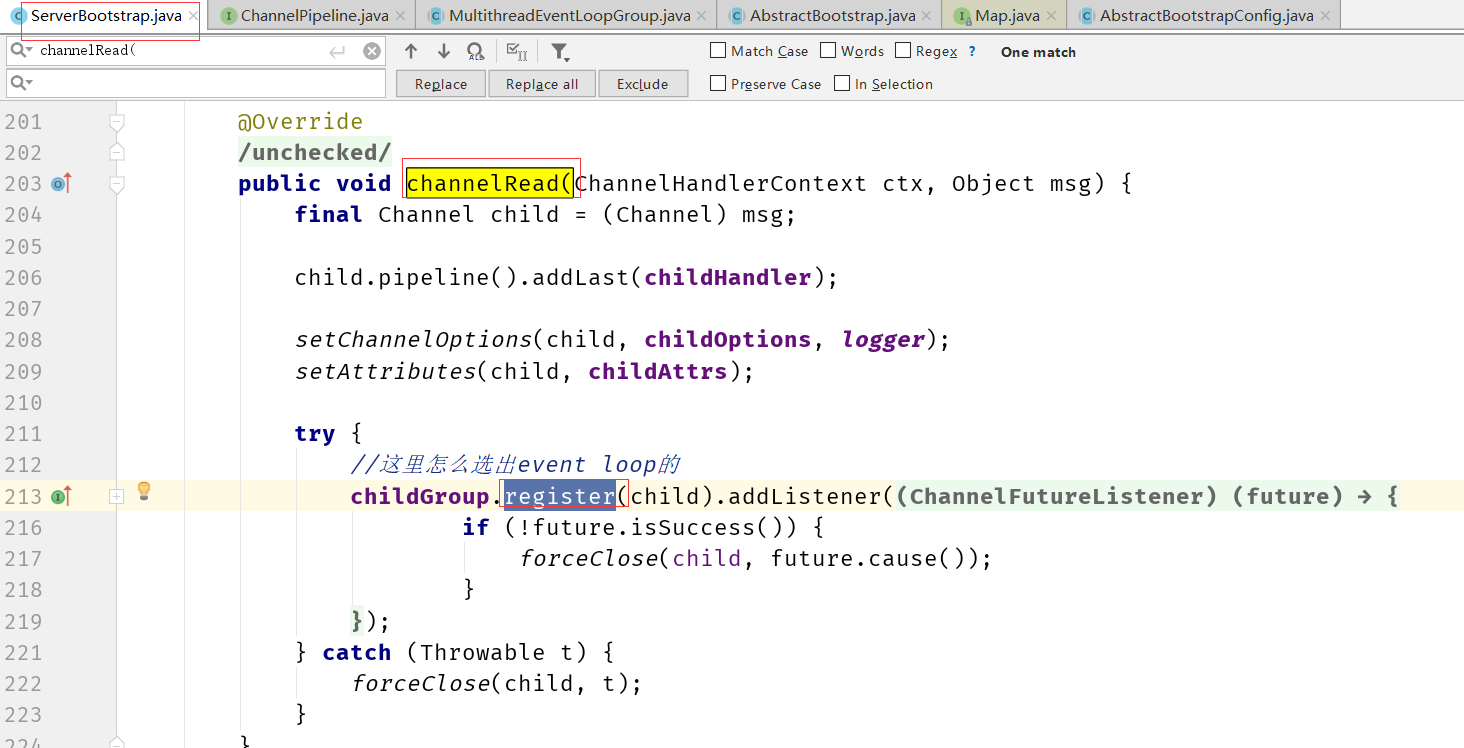
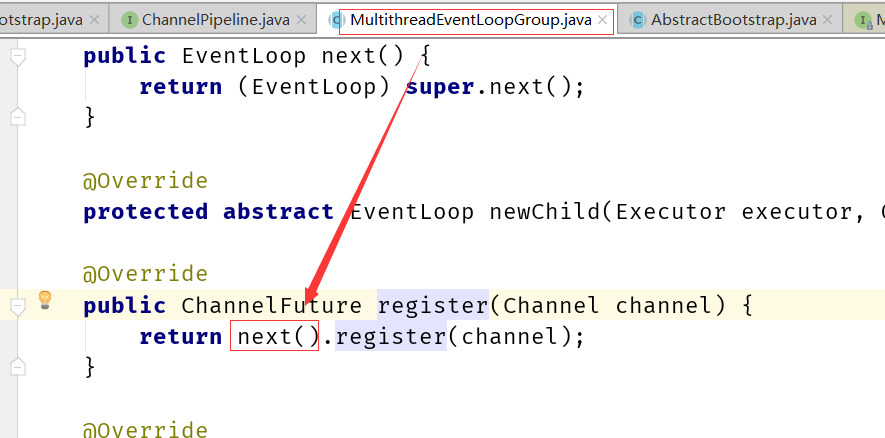


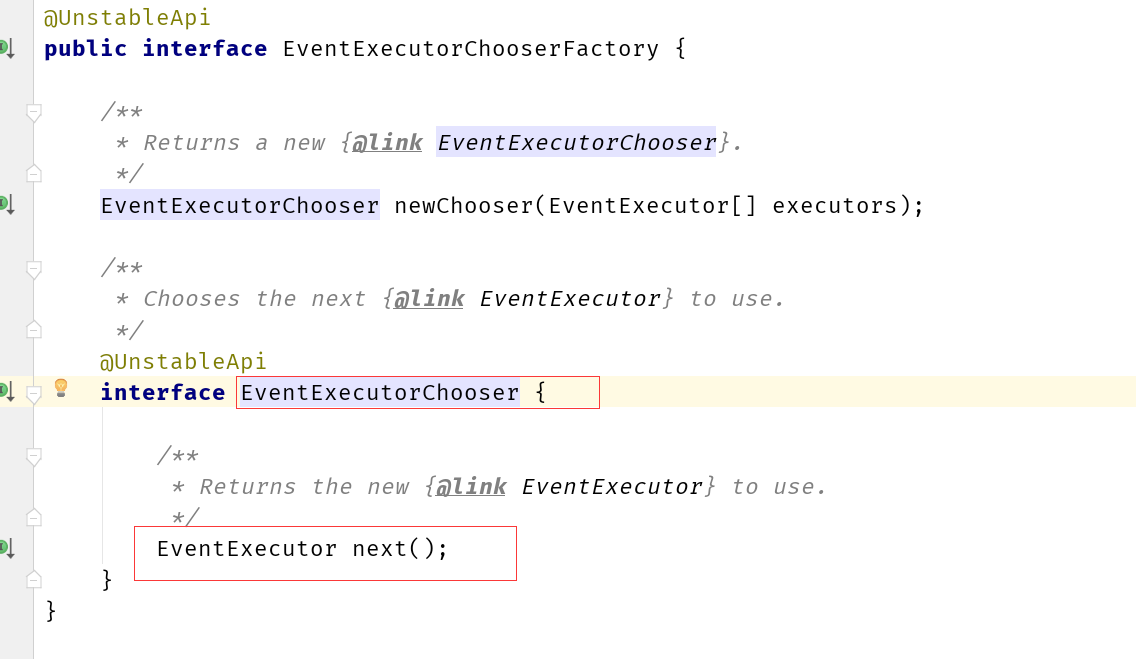

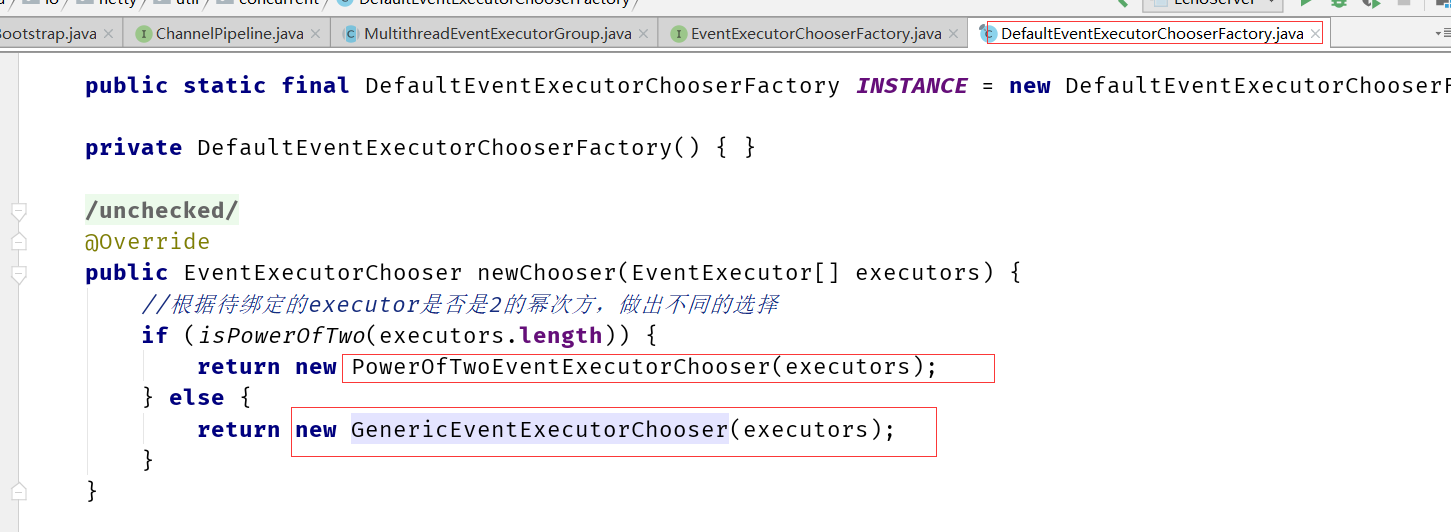

所以这里可以看到,在选择的算法删,&运算比%运算效率要高,但是必须基数是2的次方(这种跟HashMap中的取模运算是一样),这里是极致的追求高性能!
实现多路复用器是怎么跨平台的
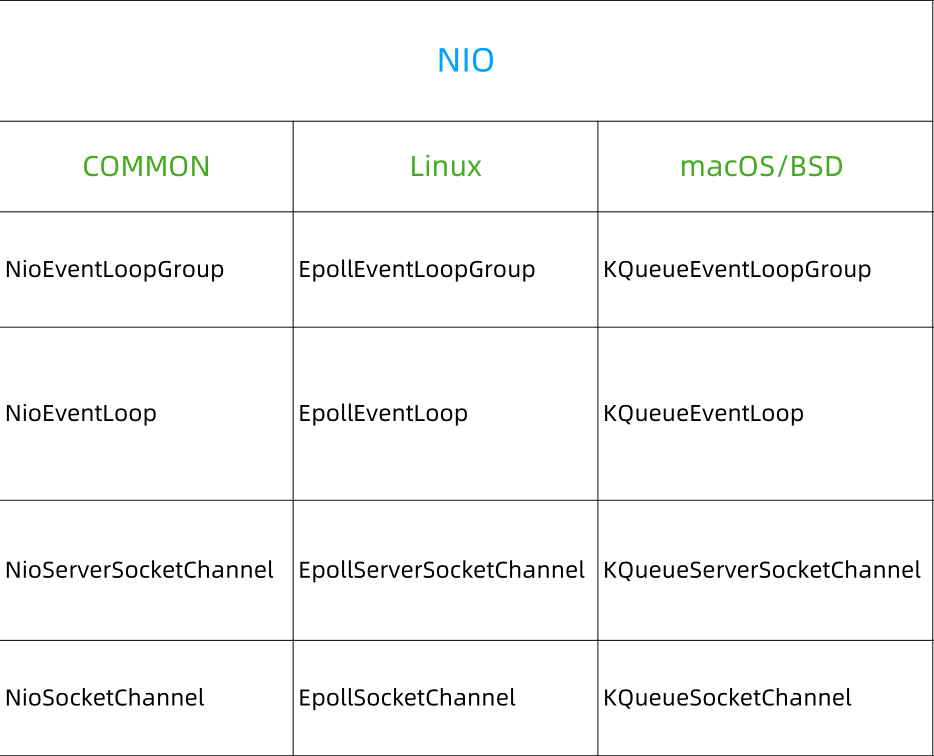
在不同的操作系统上,NIO怎么去实现多路复用的。我可以看下,

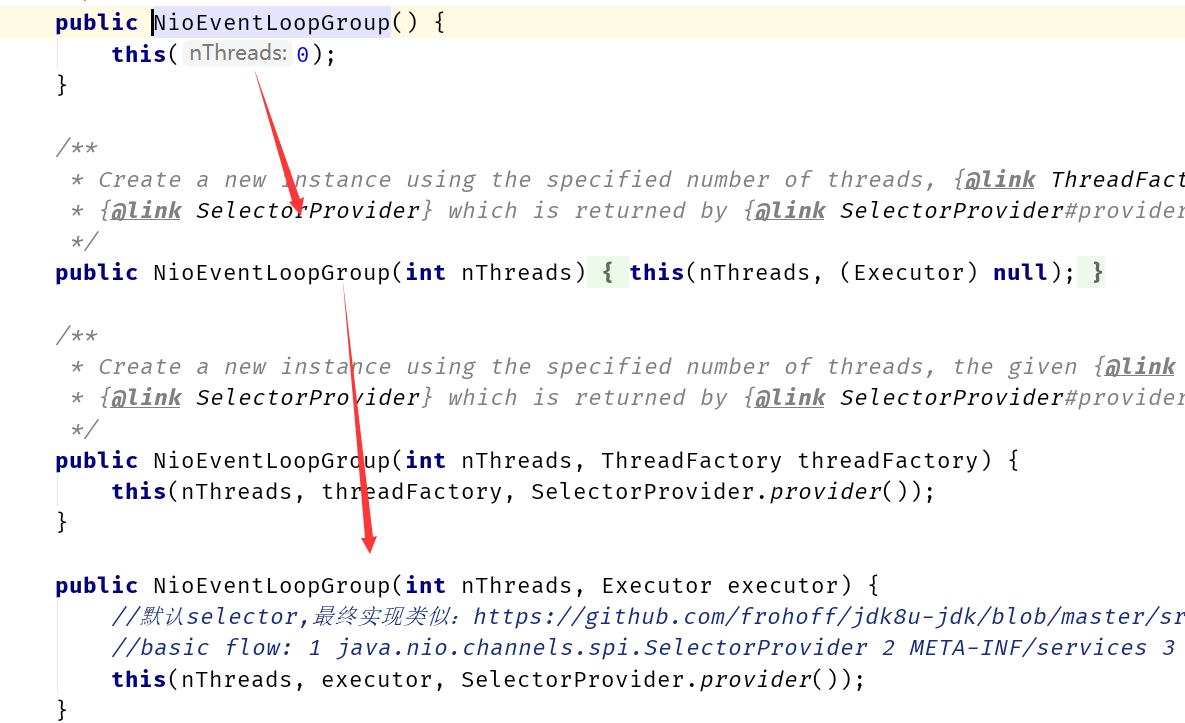

mac系统
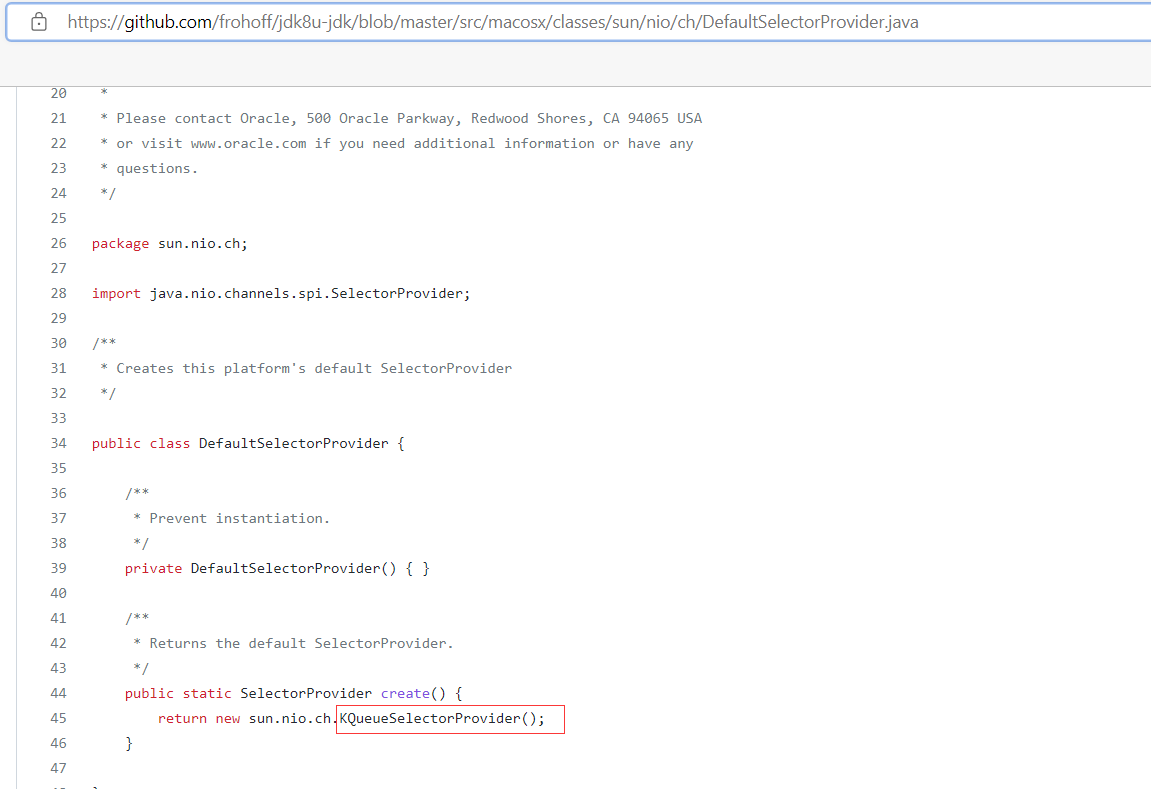
jdk8u-jdk/DefaultSelectorProvider.java at master · frohoff/jdk8u-jdk · GitHub
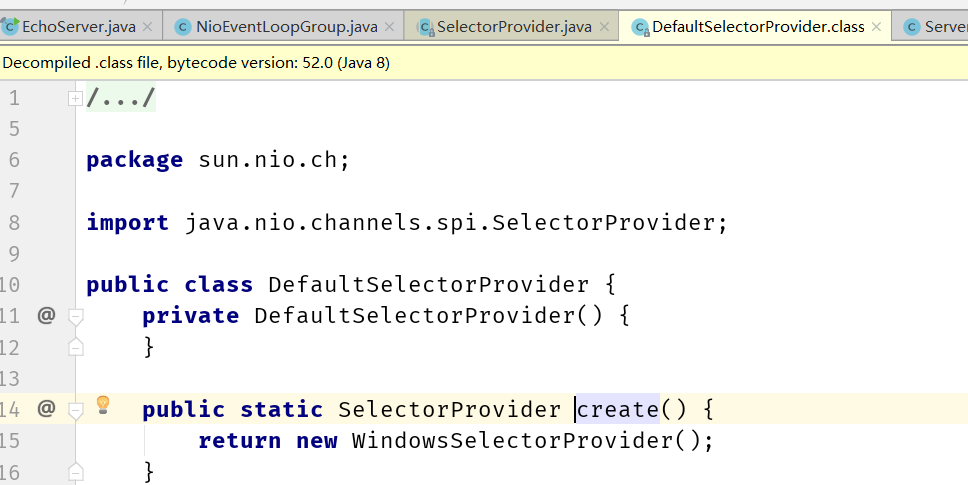
windows系统
Netty对处理粘包/半包的支持
什么是粘包和半包?

假设客户端分别发送了两个数据包ABC和DEF给服务端,由于服务端一次读取到的字节数是不确定的,故可能存在以下4种情况
1、服务端分两次读取到了两个独立的数据包,分别是ABC和DDEF,没有粘包和拆包;
2、服务端一次接收到了两个数据包,ABC和DEF粘合在一起,被称为TCP粘包;
3、服务端分两次读取到了两个数据包,第一次读取到了完整的ABC包和DEF包的部分内容(ABCD),第二次读取到了DEF包的剩余内容(EF),这被称为TCP拆包
4、服务端分两次读取到了两个数据包,第一次读取到了ABC包的部分内容(AB),第二次读取到了CD,第三次读到了EF(这种有粘包和半包问题)
TCP粘包/半包发生的原因
根本原因:TCP 是流式协议,消息无边界。
UDP 像邮寄的包裹,虽然一次运输多个,但每个包裹都有“界限”,一个一个签收,所以无粘包、半包问题。
TCP收发
一个发送可能被多次接收,多个发送可能被一次接收
TCP传输
一个发送可能占用多个传输包,多个发送可能公用一个传输包
TCP粘包/半包解决实战
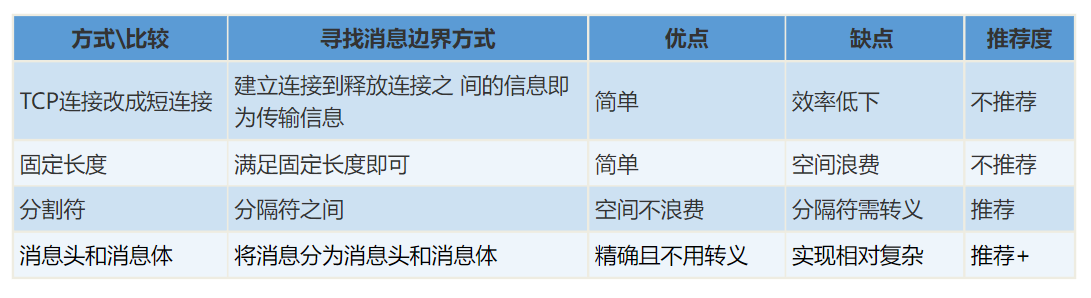
固定长度
消息定长,例如每个报文的大小为固定长度200字节,如果不够,空位补空格;
参见com.msb.netty.splicing.fixed下的代码。
消息定长:FixedLengthFrameDecoder类
不过确定很明显,如果消息不定长,那么空间非常浪费,所以这种方式不推荐!!!
分割符
在包尾增加分割符,比如回车换行符进行分割,例如FTP协议;
参见com.msb.netty.splicing.linebase(回车换行符进行分割)
行分隔符类:LineBasedFrameDecoder
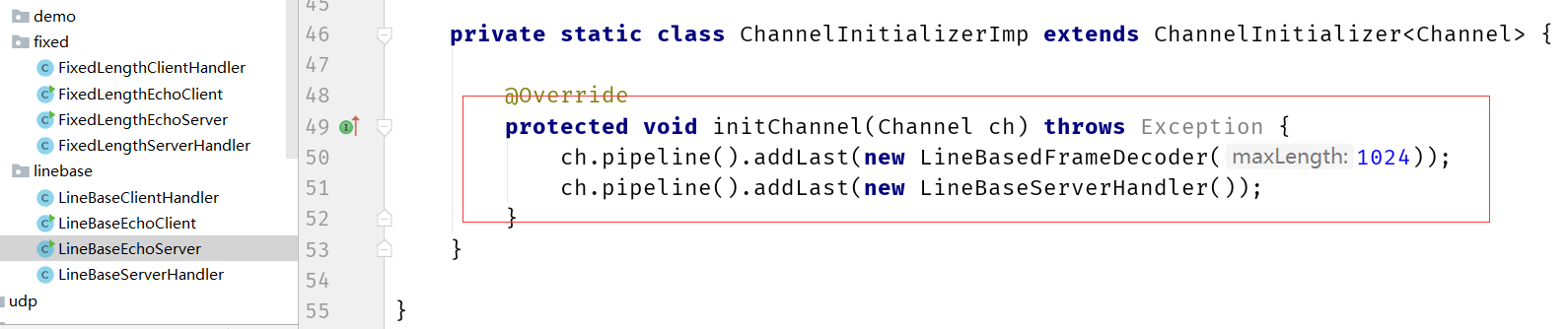
com.msb.netty.splicing.delimiter(自定义分割符)
自定义分隔符类:DelimiterBasedFrameDecoder

消息头和消息体
将消息分为消息头和消息体,消息头中包含表示消息总长度(或者消息体长度)的字段,通常设计思路为消息头的第一个字段使用int32来表示消息的总长度,使用LengthFieldBasedFrameDecoder
Netty的编解码器
解码器: 将字节解码为消息
编码器: 将消息编码为字节
一次解码器
一次解码器: 解决半包粘包问题的常用三种解码器
io.netty.buffer.ByteBuf (原始数据流)-> io.netty.buffer.ByteBuf (用户数据)
二次解码器
二次解码器: 需要和项目中所使用的对象做转化的编解码器
- Java 序列化
- Marshaling
- XML
- JSON
- MessagePack
- Protobuf
- 其他

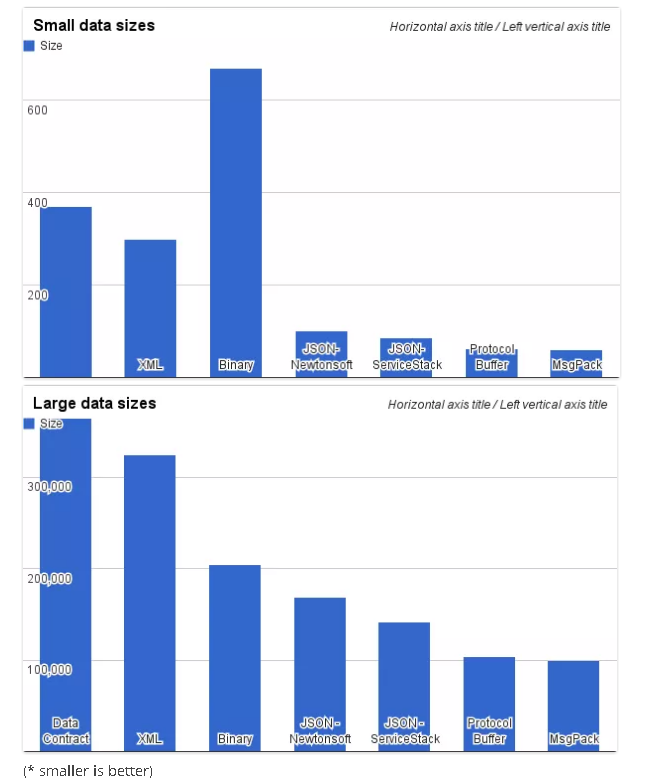
编解码速度对比:
2017-05-06 10_30_22-Serialization Performance comparison(XML,Binary,JSON,P…) | HowToAutomate.in.th
MessagePack
MessagePack: It's like JSON. but fast and small. (msgpack.org)
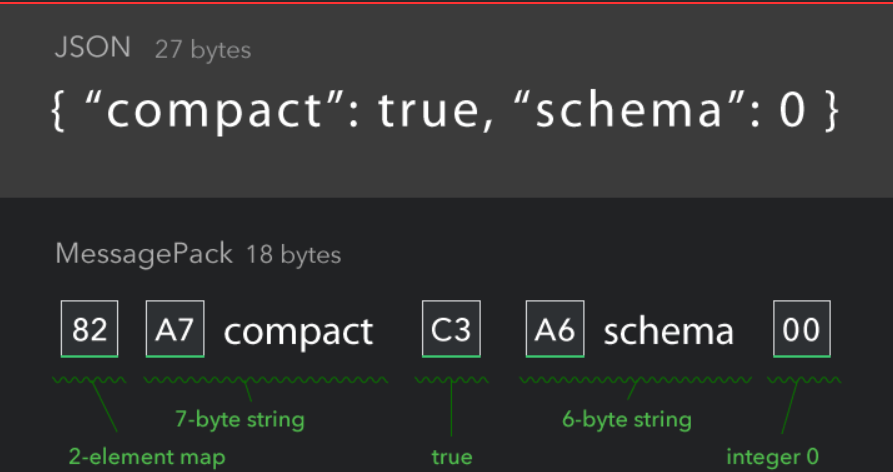
优点:压缩包比高,语言支持丰富,缺点:难懂
编解码器源码分析
NETTY的String编解码器
比较简单,转成字符串
NETTY的Java序列化编解码器
核心类,你可以看出继承了 LengthFieldBasedFrameDecoder
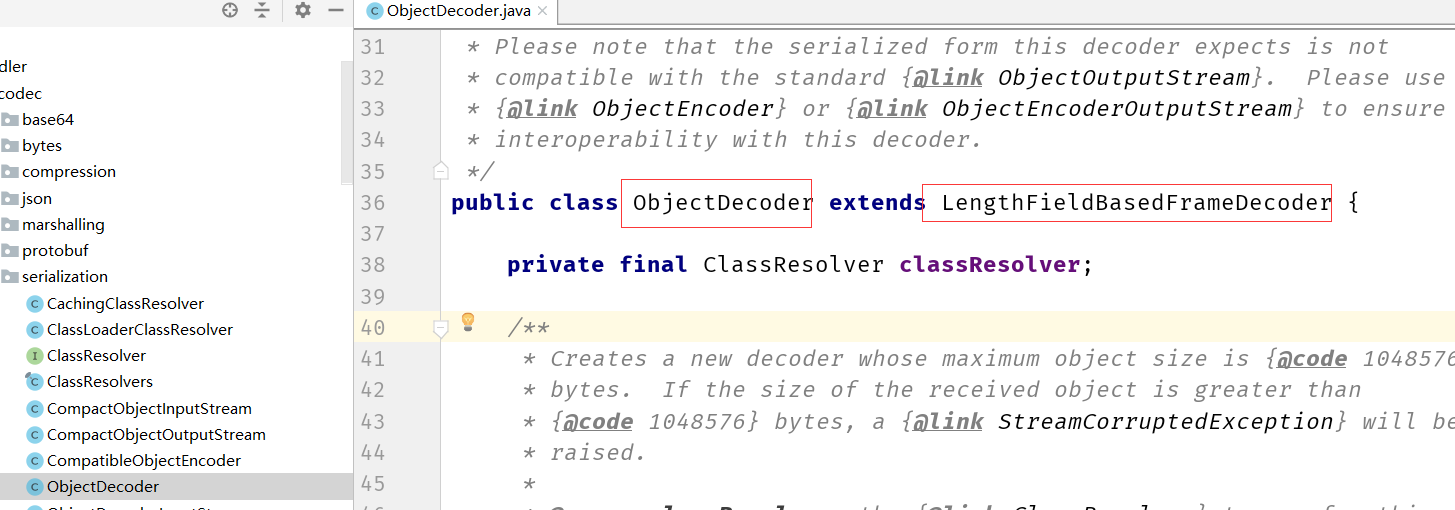
再到编码器中: ObjectEncoder
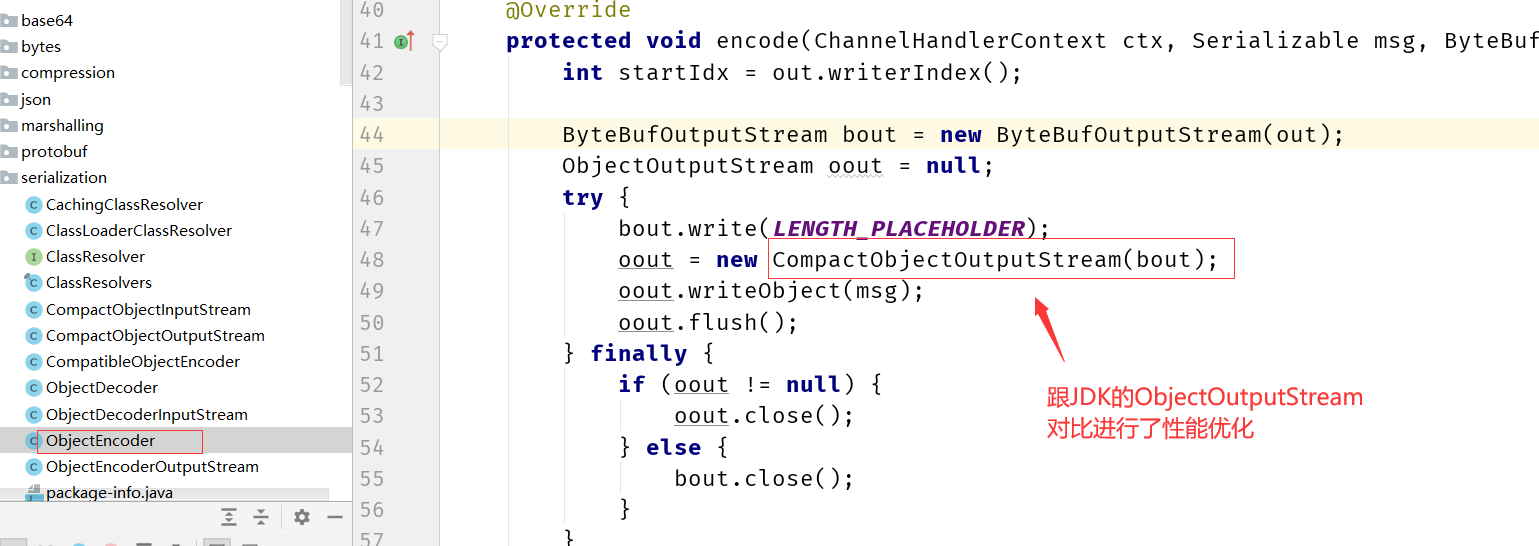
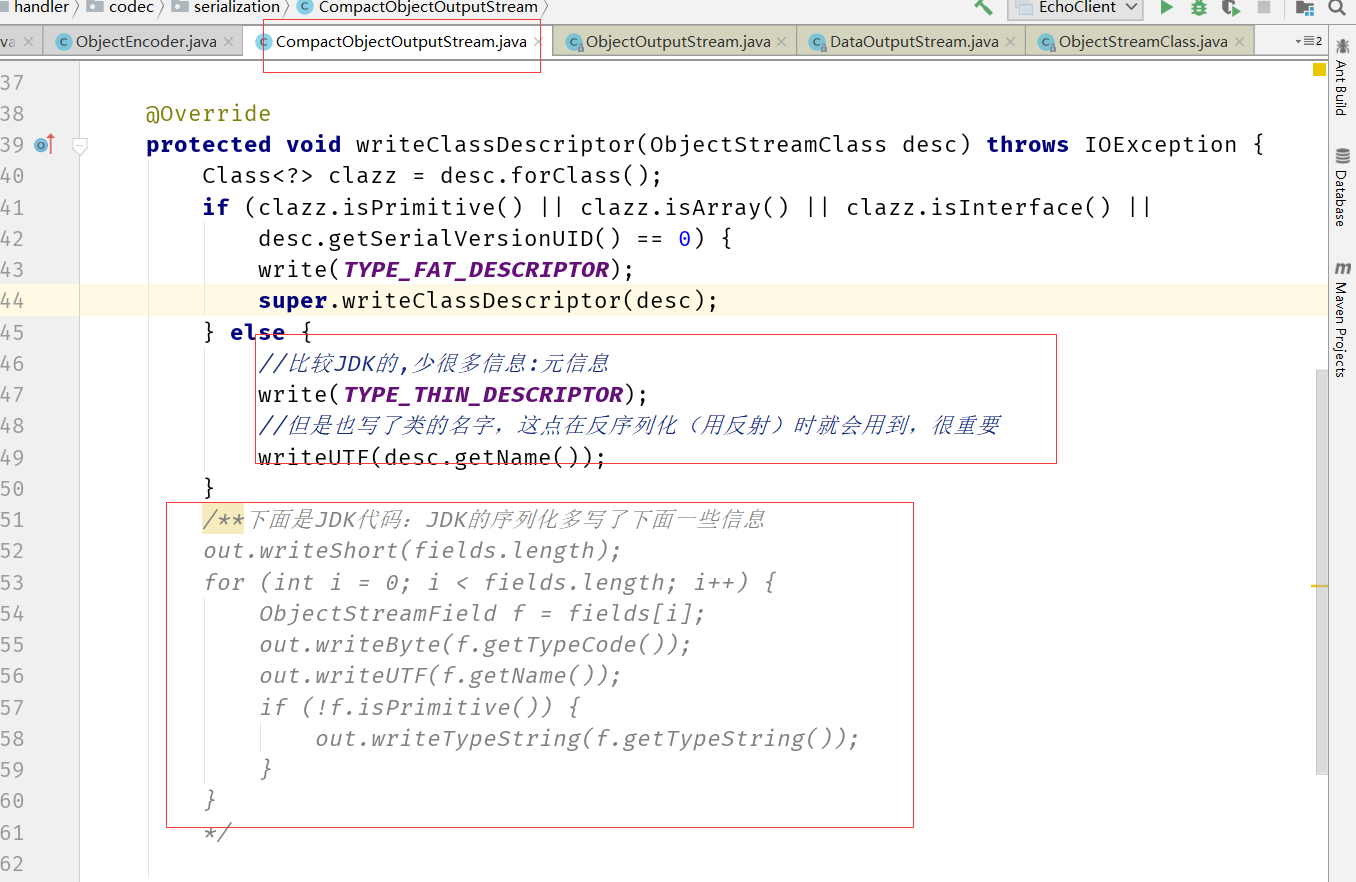
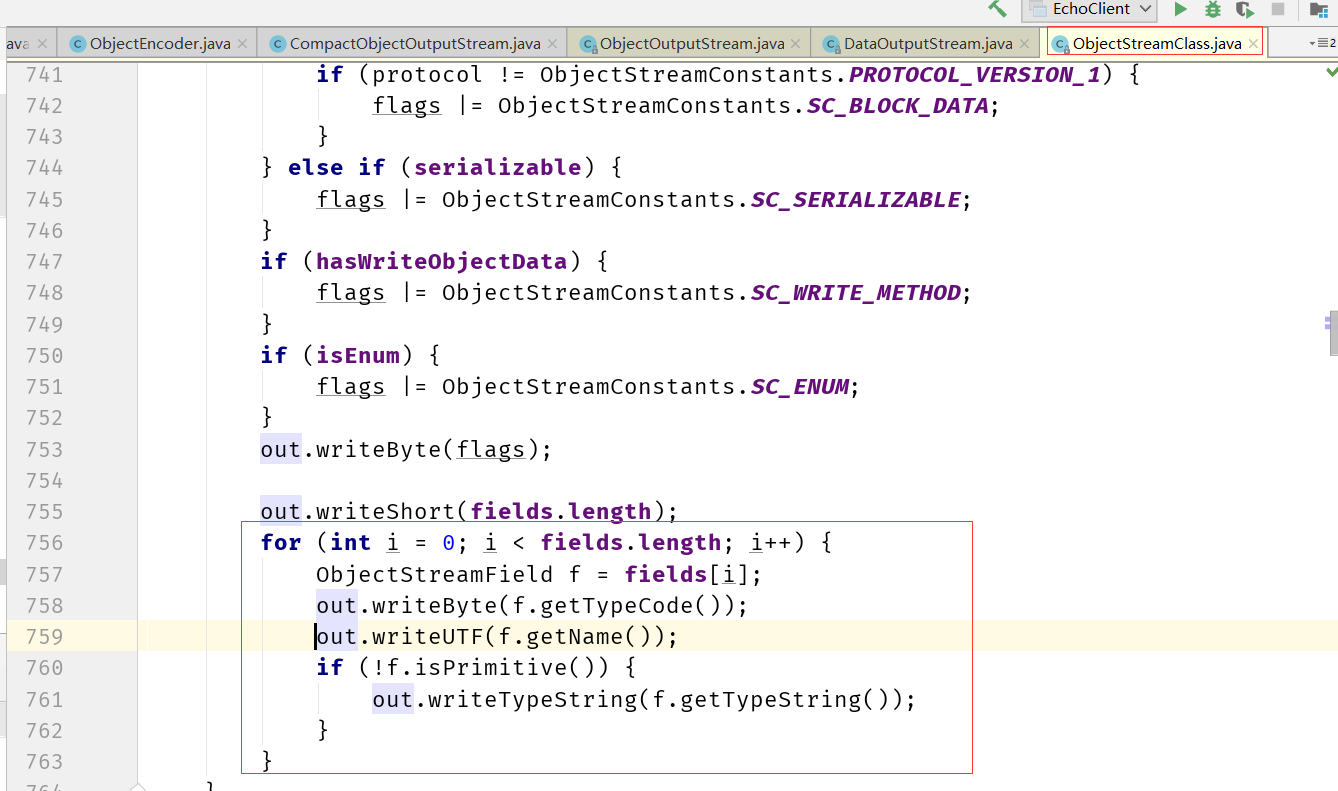
通过看源码可知,NETTY针对JDK的序列化也做了优化(虽然JDK的序列化本身效率低)
protobuf编解码器
Release Protocol Buffers v21.2 · protocolbuffers/protobuf · GitHub



源码分析
ProtobufVarint32FrameDecoder

这里可以看出来,protobuf采用的是不定长,报文头不是定长的,站在性能角度来说,是可以不浪费空间的。
这样看也大致大知道protobuf非常高效
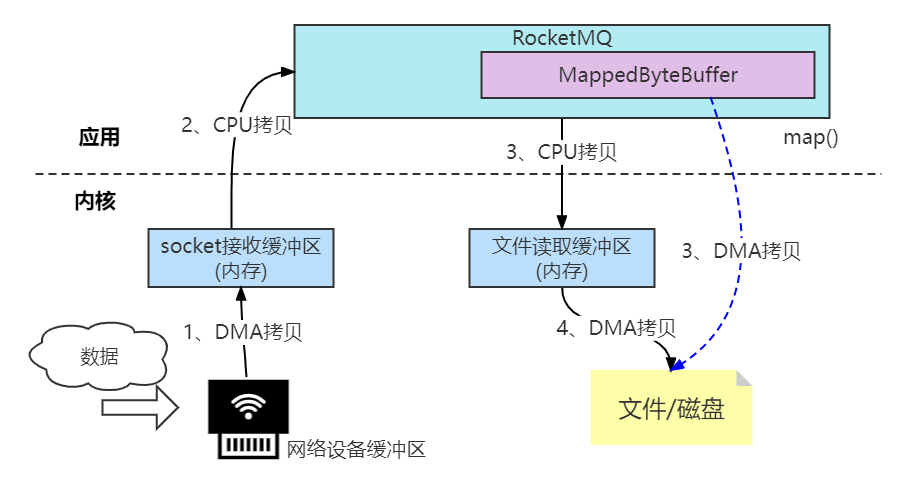
Netty中的零拷贝
什么是零拷贝?
零拷贝(英语: Zero-copy) 技术是指计算机执行操作时,CPU不需要先将数据从某处内存复制到另一个特定区域。这种技术通常用于通过网络传输文件时节省CPU周期和内存带宽。
➢零拷贝技术可以减少数据拷贝和共享总线操作的次数,消除传输数据在存储器之间不必要的中间拷贝次数,从而有效地提高数据传输效率
➢零拷贝技术减少了用户进程地址空间和内核地址空间之间因为上:下文切换而带来的开销
可以看出没有说不需要拷贝,只是说减少冗余[不必要]的拷贝。
下面这些组件、框架中均使用了零拷贝技术:Kafka、Netty、Rocketmq、Nginx、Apache。
Linux的I/O机制与DMA
在早期计算机中,用户进程需要读取磁盘数据,需要CPU中断和CPU参与,因此效率比较低,发起IO请求,每次的IO中断,都带来CPU的上下文切换。因此出现了——DMA。
DMA(Direct Memory Access,直接内存存取) 是所有现代电脑的重要特色,它允许不同速度的硬件装置来沟通,而不需要依赖于CPU 的大量中断负载。DMA控制器,接管了数据读写请求,减少CPU的负担。这样一来,CPU能高效工作了。现代硬盘基本都支持DMA。
实际因此IO读取,涉及两个过程:
1、DMA等待数据准备好,把磁盘数据读取到操作系统内核缓冲区;
2、用户进程,将内核缓冲区的数据copy到用户空间。
这两个过程,都是阻塞的。
传统数据传送机制
比如:读取文件,再用socket发送出去,实际经过四次copy。
伪码实现如下:
buffer = File.read()
Socket.send(buffer)
1、第一次:将磁盘文件,读取到操作系统内核缓冲区;
2、第二次:将内核缓冲区的数据,copy到应用程序的buffer;
3、第三步:将应用程序buffer中的数据,copy到socket网络发送缓冲区(属于操作系统内核的缓冲区);
4、第四次:将socket buffer的数据,copy到网卡,由网卡进行网络传输。
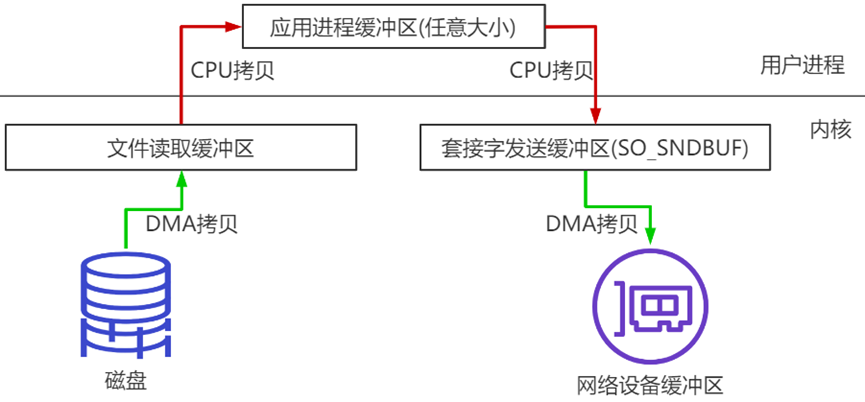
分析上述的过程,虽然引入DMA来接管CPU的中断请求,但四次copy是存在“不必要的拷贝”的。实际上并不需要第二个和第三个数据副本。应用程序除了缓存数据并将其传输回套接字缓冲区之外什么都不做。相反,数据可以直接从读缓冲区传输到套接字缓冲区。
显然,第二次和第三次数据copy 其实在这种场景下没有什么帮助反而带来开销,这也正是零拷贝出现的背景和意义。
sendfile零拷贝
linux 2.1支持的sendfile
当调用sendfile()时,DMA将磁盘数据复制到kernel buffer,然后将内核中的kernel buffer直接拷贝到socket buffer。在硬件支持的情况下,甚至数据都并不需要被真正复制到socket关联的缓冲区内。取而代之的是,只有记录数据位置和长度的描述符被加入到socket缓冲区中,DMA模块将数据直接从内核缓冲区传递给协议引擎,从而消除了遗留的最后一次复制(CPU copy)。
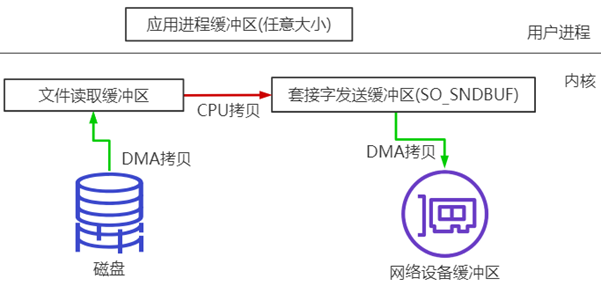
一旦数据全都拷贝到socket buffer,sendfile()系统调用将会return、代表数据转化的完成。socket buffer里的数据就能在网络传输了。
sendfile会经历:3次拷贝,1次CPU copy ,2次DMA copy;
硬件支持的情况下,则是2次拷贝,0次CPU copy, 2次DMA copy。
Netty源码分析
Netty 中也通过在 DefaultFileRegion 中包装了 NIO 的 FileChannel.transferTo() 方法实现了零拷贝:io.netty.channel.DefaultFileRegion#transferTo

案例性能对比
代码如下,使用传统的四次传输,对比使用了sendfile技术的零拷贝技术

传统四次传输:耗时

senfile技术:耗时

Netty中的锁机制
锁优化技术:
1、减少锁的粒度
2、减少锁对象的空间占用
3、提高锁的性能
4、根据不同的业务场景选择适合的锁
5、能不用锁则不用锁
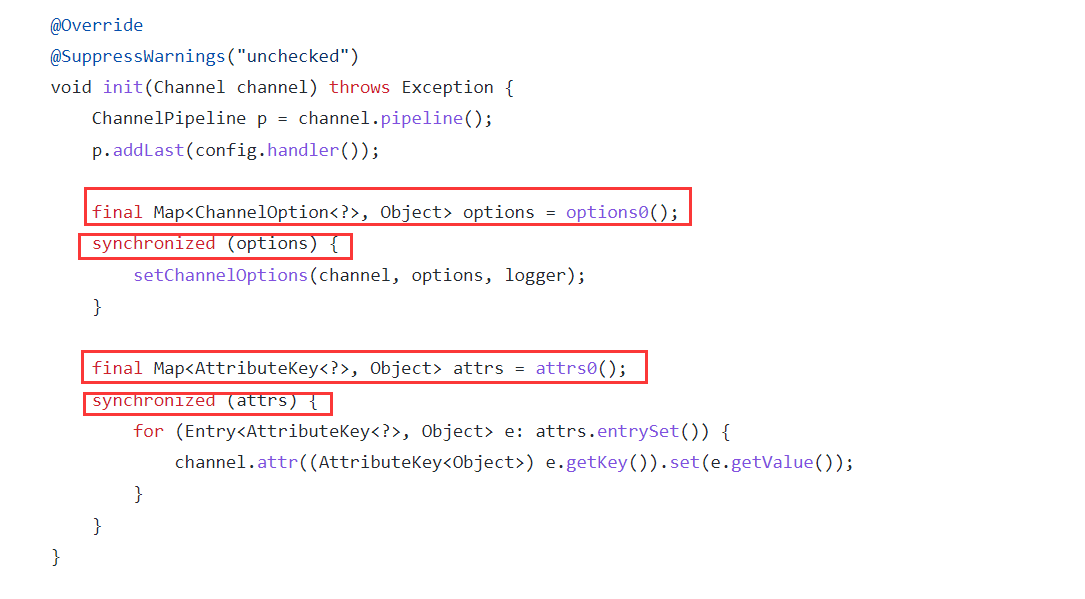
减少锁的粒度
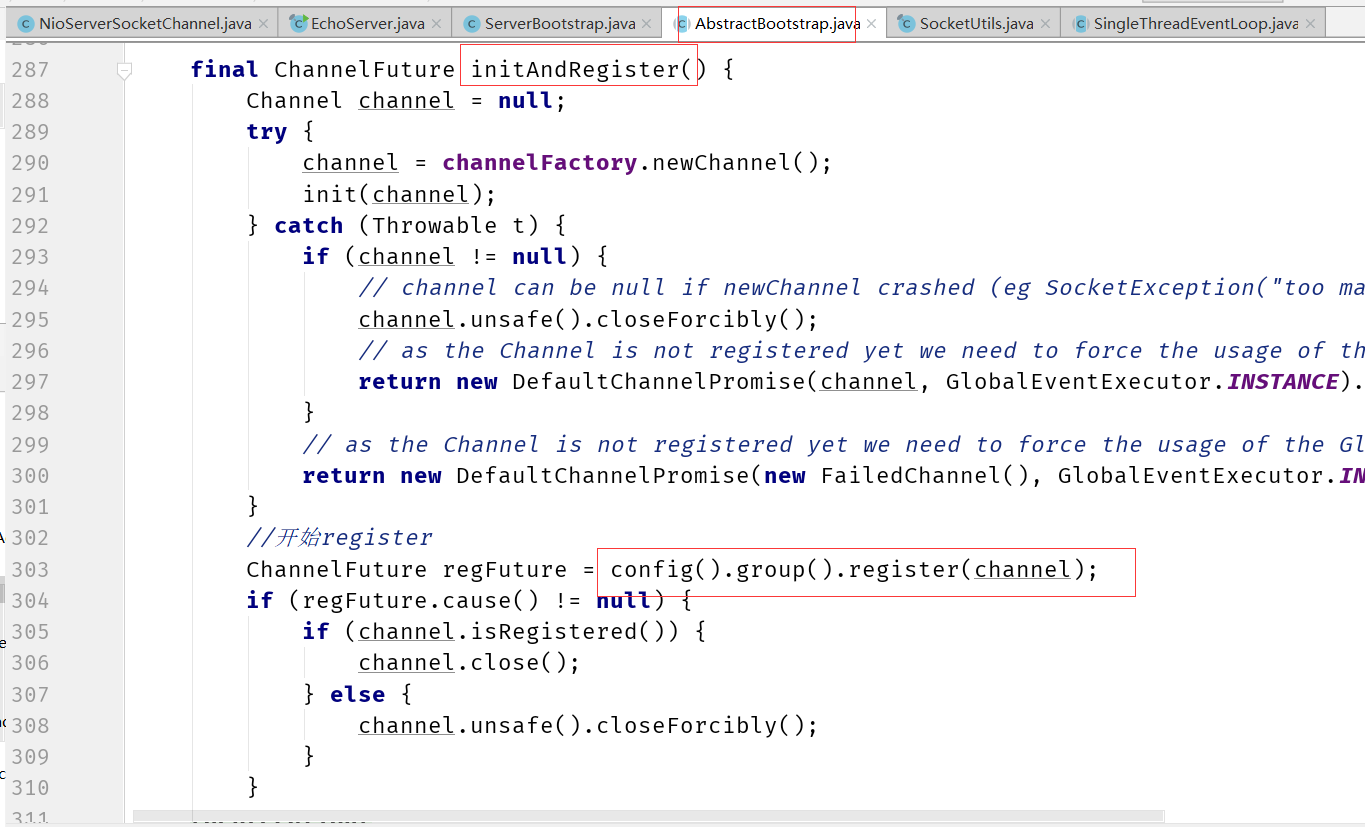
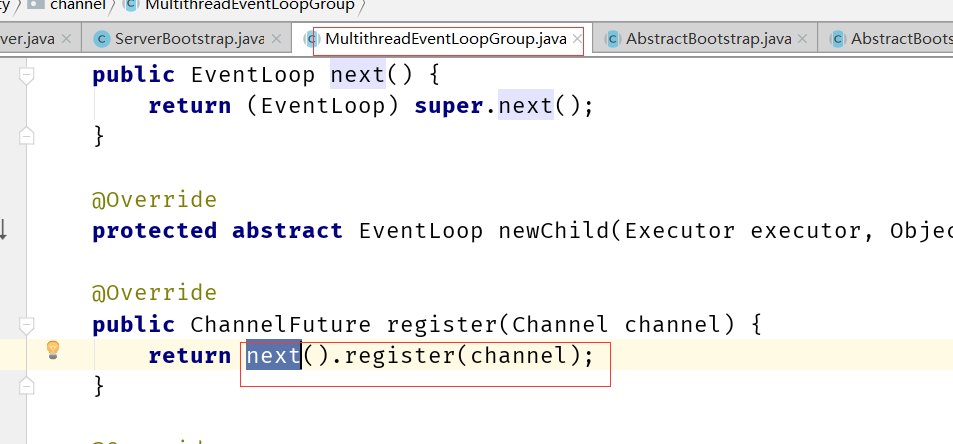
io.netty.bootstrap.ServerBootstrap#init
请注意,因为这个方法已经被重构了,但是这个地方比较经典:展示需要找老版本
netty/Bootstrap.java at netty-4.1.15.Final · netty/netty · GitHub
减少锁对象的空间占用
注意锁的对象本身大小 -> 减少空间占用
io.netty.channel.ChannelOutboundBuffer
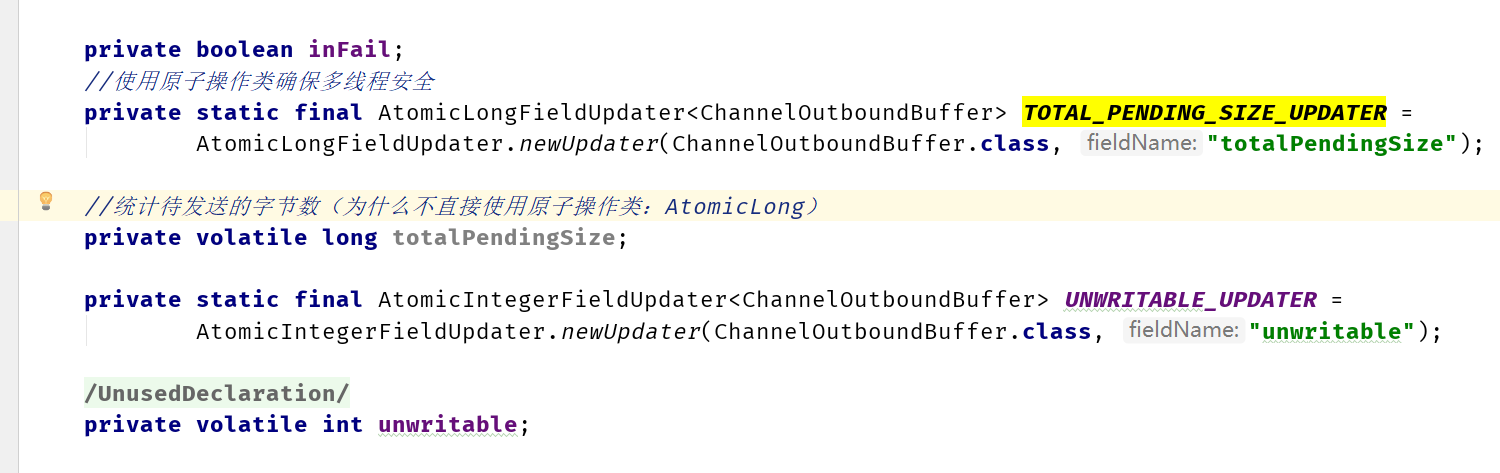
Atomic long VS long
Atomic long:是一个对象,包含对象头(object header)以用来保存 hashcode、lock 等信息,32 位系统占
用8字节;64 位系统占 16 字节。
AtomicLong = 8 bytes (volatile long)+ 16bytes (对象头)+ 8 bytes (引用) = 32 bytes
而如果使用long,则只有8个字节。
虽然代码实现麻烦一些,但是能够节约至少24个字节。
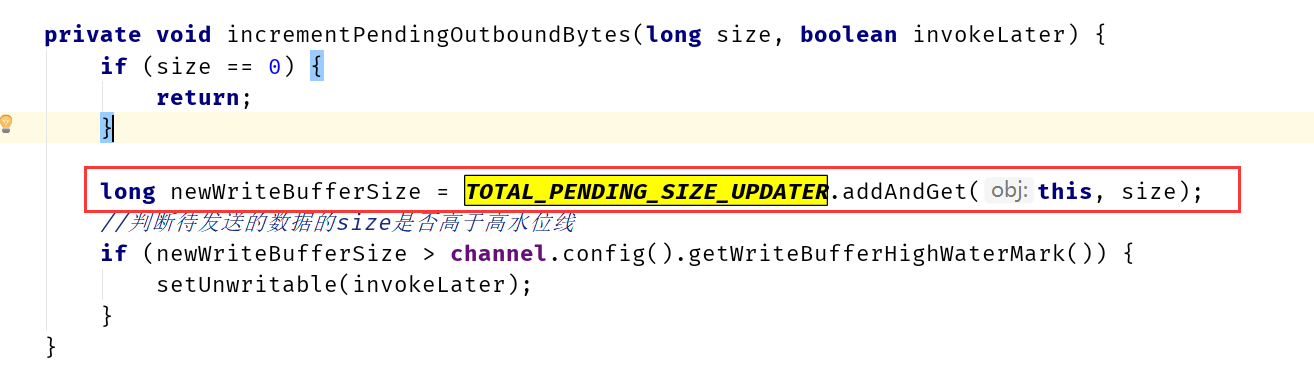
提高锁的性能
io.netty.util.internal.PlatformDependent#newLongCounter()
记录内存分配字节数


高并发时:java.util.concurrent.atomic.AtomicLong -> java.util.concurrent.atomic.LongAdder (JDK1.8)
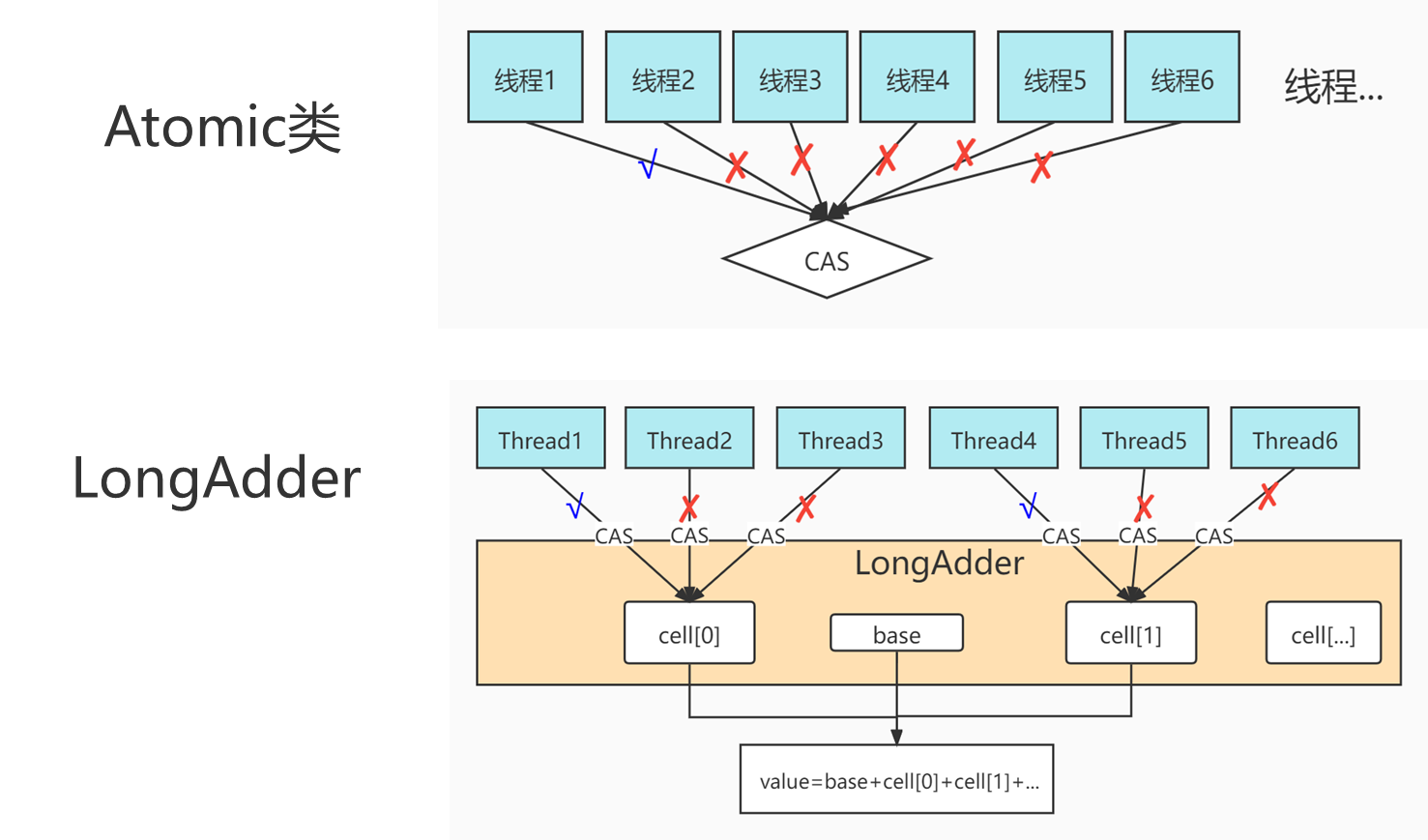
另外阿里的开发手册中也明确的说明这点:

根据不同的业务场景选择适合的锁
io.netty.util.concurrent.SingleThreadEventExecutor#threadLock
关闭和等待关闭事件执行器



请注意这里,这里为什么不简单使用Object.wait/notify 而使用CountDownLatch
在实际运用过程中Object.wait/notify,这个用起来比较简单,但是实际使用的时候,往往非常复杂。因为你使用的时候,必须要放到一个同步代码块中(监视器中),如果不放的话,它就会直接报错。对于新人来说非常不友好。
而使用CountDownLatch它的业务就非常简单了。
能不用锁则不用锁
io.netty.util.Recycler#threadLocal
用 ThreadLocal 来避免资源竞争,轻量级的线程池实现



ThreadLocal使用的时候要避免内存泄漏,具体的在并发编程中有详细的讲解,这里不再重复述说。















 901
901











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











