







萌新的学习笔记,写错了恳请斧正。
目录
4.阶码全为1,尾数不全为0(非数,NaN,Not a Number)
大小端字节序
什么是大小端
首先,我们要知道,整数(short、int、long、long long)在内存中以补码的形式存储,无符号整数(unsigned)在内存中以原始二进制序列存储。
当数据长度小于等于一个字节时 ,很显然计算机就直接存储在一个字节内(内存存储的基本单元是字节)。而大小端字节序,则是超过一个字节的数据在内存中存储的两种方式。
为了更清楚的理解大小端字节序,下面我们创建一个变量a:
#include <stdio.h>
int main()
{
int a = 0x12345678;
return 0;
}我们知道int整型占4个字节,也就是说12、34、56、78会分别存储在4个字节单元中。那么,这4个字节单元在内存中是从高地址向低地址排列还是由低向高就成了一个问题。
我们把78这一头叫做数据的低位字节,12那一头叫做高位字节。那么:
- 将数据的低位字节存储在内存的高位,就叫大端存储,对应大端机器
- 将数据的低位字节存储在内存的低位,就叫小端存储,对应小端机器
下面我们在Visual Stodio(x86 Debug)环境下调试上方代码, 并打开内存窗口,观察变量a的内存空间:

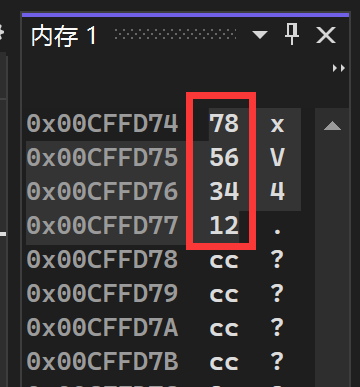
这就是将数据的低位字节(78)储存在了内存的低位,是小端存储模式。
我们常用的大多数环境(x86、x64…)都是小端结构( 有计算优势),但是仍然存在大端模式的机器(如KEIL C51)。甚至有些ARM处理器可以让硬件选择采用大端还是小端。
写一个判断大小端的程序
其实很简单,我们截取数字1在内存中的第一个字节即可。
如果输出是1就是小端机器,如果是0就是大端机器。
#include <stdio.h>
int check_sys()
{
int i = 1;
return *(char*)&i;
}
int main()
{
if (check_sys())
printf("该机器为小端字节序机器\n");
else
printf("该机器为大端字节序机器\n");
return 0;
}这里先取a的地址、强制类型转换为char*再解引用来取出a在内存中的第一个字节。
注意:这里不能直接将a强制类型转换为char类型来读取第一个字节,因为这样永远只会截取数据最低位的字节,和大小端机器无关。
或者我们也可以用联合体的方式取第一个字节(联合体相关内容在之后的笔记):
int check_sys()
{
union
{
int i;
char c;
} u;
u.i = 1;
return u.c;
}浮点数在内存中的存储(IEEE 754规则)
引入
浮点数包括float、double、long double等类型,可写成小数形式(3.14)或科学计数法(1.1E2)
不同浮点数的数据范围在float.h头文件中被规定
下面我们看一段代码:
#include <stdio.h>
int main()
{
int n = 9;
float* p = (float*)&n;
printf("n的值为:%d\n", n);
printf("*p的值为:%f\n", *p);
*p = 9.0;
printf("n的值为:%d\n", n);
printf("*p的值为:%f\n", *p);
return 0;
}这段代码的输出结果为:
n的值为:9
*p的值为:0.000000
n的值为:1091567616
*p的值为:9.000000明明n与*p在内存中是同一个数,为什么会出现上方的情况呢?
这与浮点数在内存中的存储有关
存储规则解释
浮点数在内存中的存储遵循IEEE 754规则,由电气与电子工程师协会(IEEE)规定
以单精度浮点数为例,我们将其分为3个部分存储在内存中(都是01组成的二进制):
- 符号位S:1位,0代表正数,1代表负数
- 阶码E:8位,就是科学计数法的指数部分加127(因为其表示精度的是-126次方到127次方,要加上127让阶码从数字1到254便于存储,因此单精度浮点数也叫余127码)(阶码0与255有特殊含义,见下方读取相关内容)
- 尾数M:23位,就是科学计数法中数字小数点后的部分
以数字5.0为例:
- 其为正数,则S=0
- 其可以表示成二进制科学计数法1.01*2^2,则尾数M为01000000000000000000000
- 其科学计数法指数为2加上127得到阶码E=129=10000001(二进制)
- 合起来就能得到数字5.0在内存中的存储:0100 0000 1010 0000 0000 0000 0000 0000
对于双精度浮点数,其规则与单精度浮点数类似,但是阶码变为11位(余1023码),尾数变为52位。总字节数由4字节变为8字节。
读取规则解释
读取时有3种情况:
1.阶码不全为0或全为1(规格化数)
读取时阶码减去127(或1023)得到指数部分,尾数加1得到数字部分
所以说单精度浮点数规格化数的指数范围是-126到127
2.阶码全为0(非规格化数)
读取时阶码加一再减去127(或1023)得到指数部分(加一使浮点数取值连续),尾数不加1,用于表示极其接近0的数字
如果尾数也全为0,则代表浮点数的±0
3.阶码全为1,尾数全为0(inf)
被判定为浮点数的无穷,正负由符号位决定,用代码inf表示
4.阶码全为1,尾数不全为0(非数,NaN,Not a Number)
用代码NaN表示,用于表示异常数据(比如某个数除以0就会返回NaN,也有可能输出IND-indeterminate不确定的)
练习
1.浮点数
这时上面浮点数存储开头的那一段代码就好理解了
首先第一部分将整型9当做浮点数输出,整型9在内存中存储为:
0000 0000 0000 0000 0000 0000 0000 1001
将其当做浮点数,则S=0,阶码E=00000000,由上面非规格化数内容我们知道这是一个趋近于0的数,所以输出了0.000000
第二部分将浮点数9.0当做整数输出,浮点数9在内存中存储为:
0100 0001 0001 0000 0000 0000 0000 0000
将其当做整型输出即补码转换为原码为:1091567616
2.整型存储
a.下面程序的输出为
#include <stdio.h>
int main()
{
char a = -1;
signed char b = -1;
unsigned char c = -1;
printf("a=%d,b=%d,c=%d", a, b, c);
return 0;
}就是很简单的截取,输出a=-1,b=-1,c=255
b.下面两个程序的输出为
#include <stdio.h>
int main()
{
char a = -128;
printf("%u\n", a);
return 0;
}#include <stdio.h>
int main()
{
char a = 128;
printf("%u\n", a);
return 0;
}两个程序的输出结果均为4294967168
也是简单的整型提升的问题
比如第一段程序-128的补码为1111 1111 1111 1111 1111 1111 1000 0000
截取到a为1000 0000,整型提升回1111 1111 1111 1111 1111 1111 1000 0000
其直接二进制转换十进制为4294967168
第二段等价,对于char来说127之上就循环回到-128,所以128与-128在这里没有区别
c.下面程序的输出为
#include <stdio.h>
int main()
{
char a[1000];
int i;
for (i = 0; i < 1000; i++)
{
a[i] = -1 - i;
}
printf("%d", strlen(a));
return 0;
}此代码输出为255
同样的,对于char类型,-128在减一就循环回到了127。所以这里就是从-1一直降到-128,在从127降到1(strlen遇到“\0”结束,其ASCII码为0,所以之后的没意义)
d.下面两个程序的输出为
#include <stdio.h>
unsigned char i = 0;
int main()
{
for (i = 0; i <= 255; i++)
{
printf("hello world\n");
}
return 0;
}
#include <stdio.h>
int main()
{
unsigned int i;
for (i = 9; i >= 0; i--)
{
printf("%u\n", i);
}
return 0;
}这两段代码都是死循环,很简单
e.下面程序的输出为(假设小端环境)
#include <stdio.h>
int main()
{
int a[4] = { 1, 2, 3, 4 };
int* ptr1 = (int*)(&a + 1);
int* ptr2 = (int*)((int)a + 1);
printf("%x,%x", ptr1[-1], *ptr2);
return 0;
}其输出结果为4,2000000(有可能引发读取访问权限冲突)
很好理解,指针1减一指向数组第4个元素,指针2指向第一个元素向后偏移一位字节,也就是略过了数字1内存第一个字节又加上了数字2内存第一个字节。在小端环境下即为0x02000000
















 767
767











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











