






常见数据源
1. 站点数据
- 1.1 中国气象数据网(这是最官方的数据平台)
- 1.2 AWOS 机场观测数据
- 1.3 NOAA 全球地面站观测数据
- 1.4 全球探空数据
- 1.5 全国空气质量观测数据
- 1.6 MODIS 极轨卫星数据
- 1.7 国家冰川冻土沙漠科学数据中心
2. 格点数据
- 2.1 NCEP FNL 再分析数据 常用的气象再分析数据
- 2.2 NCEP-DOE Reanalysis 2 再分析数据
- 2.3 ERA5 数据
- 2.4 GFS/GDAS 数据 最常用的气象预报数据
- 2.5 葵花 8 号 Himawari-8 卫星数据
3. 其他(欢迎补充)
- 3.1 TEMIS遥感数据
- 3.2 我国台风历史轨迹数据
- 3.3 CMIP6 国际耦合模式比较计划
1. 站点数据
1.1 中国气象数据网
官方的数据平台 (代码待补充)
中国气象数据网是官网平台,需要注册才能使用,分普通用户,个人实名用户,科研用户。数据种类很丰富,唯一的不足是下载需要权限。当然,很多气象数据的密级为秘密,大家在使用分享时一定要注意哦!网站也提供接口服务,可以免费使用7天。
不多说,上链接国家气象科学数据中http://data.cma.cn/site/index.html
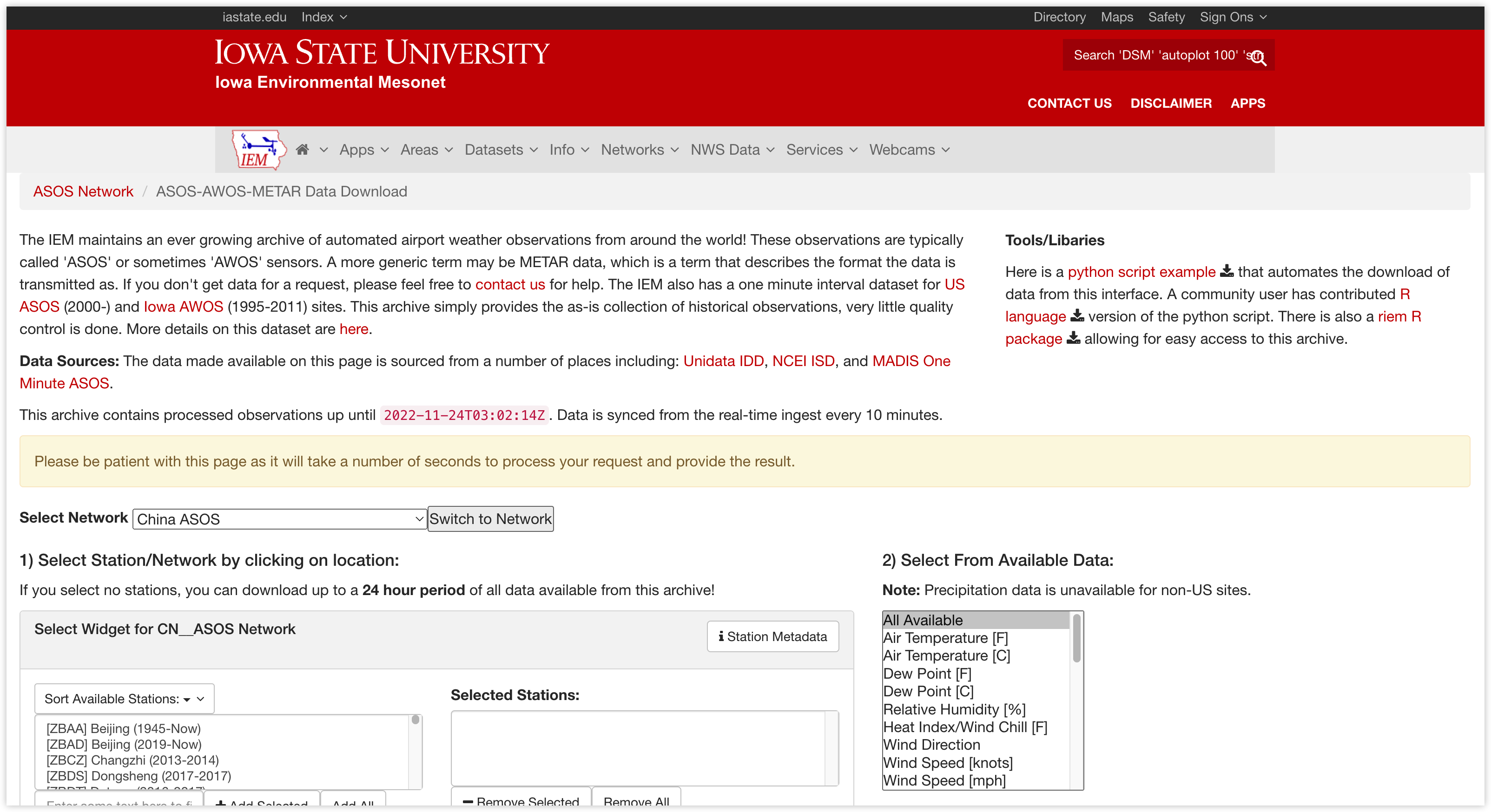
1.2 AWOS 机场观测数据
网站链接:https://mesonet.agron.iastate.edu/request/download.phtml?network=CN__ASOS
网站页面:
1.3 NOAA 全球地面站观测数据
“The Global Historical Climatology Network (GHCN) is an integrated database of climate summaries from land surface stations across the globe that have been subjected to a common suite of quality assurance reviews. The data are obtained from more than 20 sources. Some data are more than 175 years old while others are less than an hour old. GHCN is the official archived dataset, and it serves as a replacement product for older NCEI-maintained datasets that are designated for daily temporal resolution (i.e., DSI 3200, DSI 3201, DSI 3202, DSI 3205, DSI 3206, DSI 3208, DSI 3210, etc.).”
数据网站:https://www.ncei.noaa.gov/products/land-based-station
网站页面:
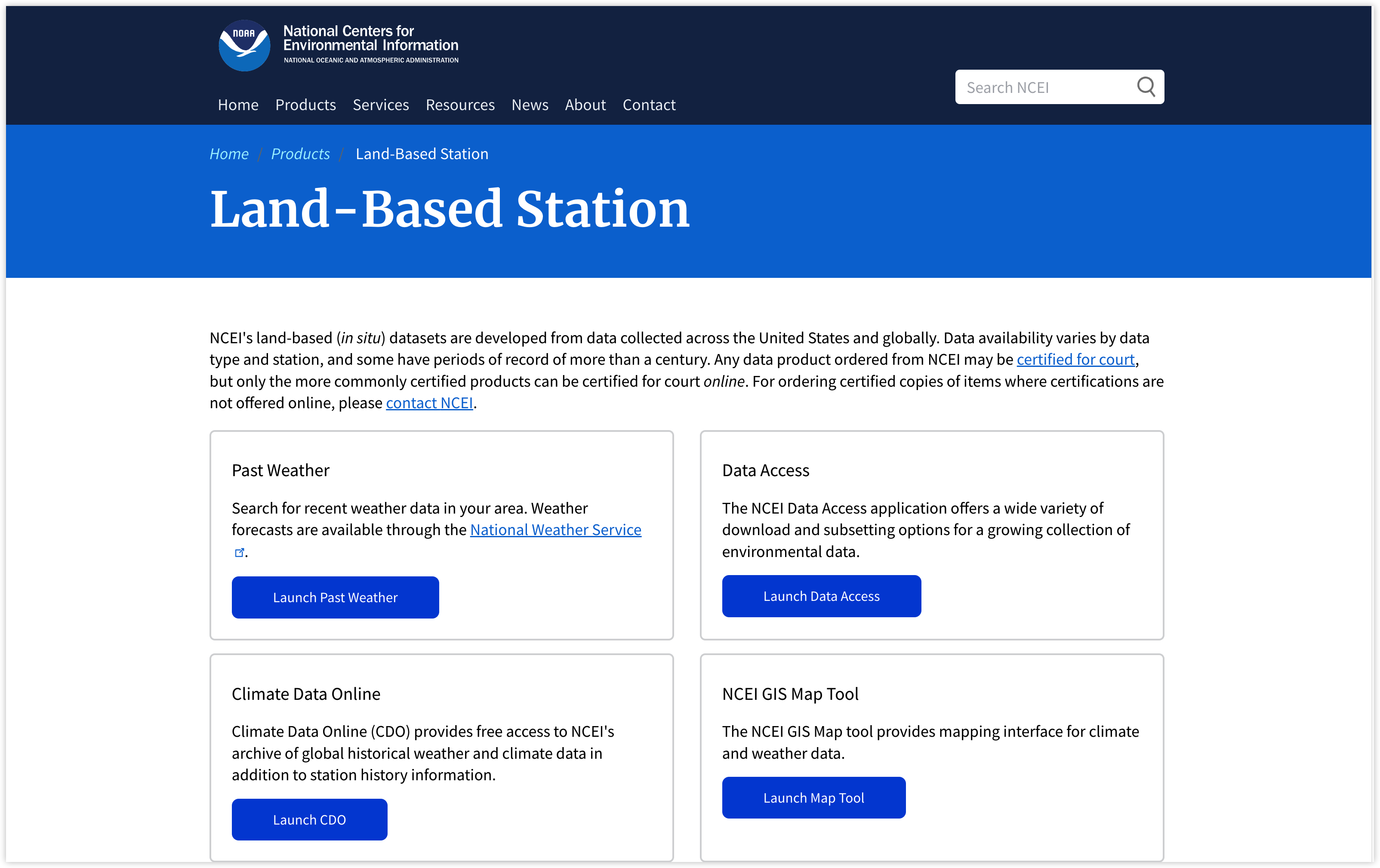
数据是按站点存放的,可以根据需求下载需要的数据。在数据下载链接的根目录下,“readme.txt”文件对数据的存在格式等进行了说明。准实时更新~
1.4 全球探空数据
探空站一般是为探测高空气象要素而建立的,通过探空气球来收集每天8点和20点的高空气象数据,遇到特殊天气(台风等)会进行加密观测。可以获近地层、850、700、500、200百帕的温度、温度露点差、位势高度、风速风向等气象要素。探空数据在天气预报有着重要的指示作用,可以分析出高空引导气流的位置、强度,及到达本地的时间和对当地天气的影响情况。
数据来自怀俄明大学:http://weather.uwyo.edu/upperair/seasia.html
我国的探空站表格:http://data.cma.cn/article/showPDFFile.html?file=/pic/static/doc/B/B.0011.0001C/UPAR_CHN_MUL_STATION.pdf
1.4.1 批量下载数据
#导入模块
import datetime
from metpy.units import units
from siphon.simplewebservice.wyoming import WyomingUpperAir
# 设置下载时段(这里是UTC时刻)
start = datetime.datetime(2020, 1, 1, 0)
end = datetime.datetime(2020, 1, 3, 0)
datelist = []
while start<=end:
datelist.append(start)
start+=datetime.timedelta(hours=12)
# 选择下载站点(以上海宝山站为例)
stationlist = ['58362']
# 批量下载
for station in stationlist:
for date in datelist:
try:
df = WyomingUpperAir.request_data(date, station)
df.to_csv(station+'_'+date.strftime('%Y%m%d%H')+'.csv',index=False)
print(date.strftime('%Y%m%d_%H')+'下载成功')
except:
print(date.strftime('%Y%m%d_%H')+'下载失败')
pass
1.4.2 读取示例数据
数据包含气压、高度、气温、露点、风向、风速、经向风速、纬向风速,还包含探空战观测时刻、经纬度和高程信息。
import pandas as pd
df = pd.read_csv('./58362_2020010100.csv')
df
1.5 全国空气质量观测数据
大佬将中国环境监测总站的全国城市空气质量实时发布平台的数据爬下来分享,免费下载,每周更新~
网址:https://quotsoft.net/air/
全国国控监测点数据 CSV格式 https://quotsoft.net/air/data/china_sites_[日期].csv
https://quotsoft.net/air/
全国城市数据 CSV格式 https://quotsoft.net/air/data/china_cities_[日期].csv
北京PM2.5/PM10/AQI数据 CSV格式 https://quotsoft.net/air/data/beijing_all_[日期].csv
北京SO2/NO2/O3/CO数据 CSV格式 https://quotsoft.net/air/data/beijing_extra_[日期].csv
例如:
https://quotsoft.net/air/data/china_sites_20200820.csv
填写日期即可
(by 洋流)
网站:http://www.pm25.in
参考:爬取实时空气质量数据
1.5.1 批量下载数据
import csv
import os
import requests
from bs4 import BeautifulSoup
def get_city_aqi(city_pinyin):
url = "http://www.pm25.in/" + city_pinyin
r = requests.get(url,timeout=30)
soup = BeautifulSoup(r.text,"html.parser")
div_list = soup.find_all("div",{"class":"span1"})
city_aqi = []
livetime = soup.find_all("div",{"class":"live_data_time"})
city_aqi.append(livetime[0].text.strip()[7:])
for i in range(8):
div_content = div_list[i]
value = div_content.find("div",{"class":"value"}).text.strip()
caption = div_content.find("div",{"class":"caption"}).text.strip()
city_aqi.append(value)
#print(city_aqi)
return city_aqi
def get_all_cities():
url = "http://www.pm25.in/"
r = requests.get(url, timeout=30)
soup = BeautifulSoup(r.text, "html.parser")
city_list = []
city_div = soup.find_all("div",{"class":"bottom"})[1]
city_link_list = city_div.find_all("a")
for city_link in city_link_list:
city_name = city_link.text
city_pinyin = city_link["href"][1:]
city_list.append((city_name,city_pinyin))
return city_list
def main():
city_list = get_all_cities()
header = ["city","time","AQI","PM2.5/1h","PM10/1h","CO/1h","NO2/1h","O3/1h","O3/8h","SO2/1h"]
with open("city_air_quality_aqi.csv","w",encoding="utf-8",newline="") as f:
writer = csv.writer(f)
writer.writerow(header)
for i, city in enumerate(city_list):
if (i+1)%10 == 0:
print("Saving {} Data (Total {} Data)".format(i + 1,len(city_list)))
city_name = city[0]
city_pinyin = city[1]
city_aqi = get_city_aqi(city_pinyin)
row = [city_name] + city_aqi
writer.writerow(row)
if __name__ == "__main__" :
main()
1.5.2 读取示例数据
import pandas as pd
df = pd.read_csv('./city_air_quality_aqi.csv')
df
1.6 MODIS 极轨卫星数据
MODIS数据目前比较全面的是在 LAADS 或者地理空间数据云
进入以后注册NASA账户,记得申请apikey
这个网站下载推荐python脚本方法
我常用的下载命令:
python laads-data-download.py -s https://ladsweb.modaps.eosdis.nasa.gov/archive/orders/501412572 -d E:\temp\ -t <这里写apikey,不要两侧的括号>
1.7 国家冰川冻土沙漠科学数据中心
**数据网址:**http://www.ncdc.ac.cn/portal/
网站注册完成后,对所需数据进行检索并提交数据申请。
2. 格点数据
2.1 NCEP FNL 再分析数据(常用的气象再分析数据)
数据下载自NCAR:https://rda.ucar.edu/
需要自行注册账户,最好是edu结尾的邮箱。
NCEP的FNL资料:http://rda.ucar.edu/data/ds083.2
空间分辨率:1°×1°
时间分辨率:逐6小时
2.1.1 批量下载数据
import requests
import datetime
# 定义登录函数
def builtSession():
email = "xxxxxxx" #此处改为注册邮箱
passwd = "xxxxxxxx" #此处为登陆密码
loginurl = "https://rda.ucar.edu/cgi-bin/login"
params = {"email":email, "password":passwd, "action":"login"}
sess = requests.session()
sess.post(loginurl,data=params)
return sess
# 定义下载函数
def download(sess, dt):
g1 = datetime.datetime(1999,7,30,18)
g2 = datetime.datetime(2007,12,6,12)
if dt >= g2:
suffix = "grib2"
elif dt >= g1 and dt <g2:
suffix = "grib1"
else:
raise StandardError("DateTime excess limit")
url = "http://rda.ucar.edu/data/ds083.2"
folder = "{}/{}/{}.{:0>2d}".format(suffix, dt.year, dt.year, dt.month)
filename = "fnl_{}.{}".format(dt.strftime('%Y%m%d_%H_00'), suffix)
fullurl = "/".join([url, folder, filename])
r = sess.get(fullurl)
with open(filename, "wb") as fw:
fw.write(r.content)
print(filename + " downloaded")
# 批量下载
if __name__ == '__main__':
print("downloading...")
s = builtSession()
for i in range(2): #共下载多少个时次
startdt = datetime.datetime(2018, 5, 16, 0) #开始时次
interval = datetime.timedelta(hours = i * 6)
dt =startdt + interval
download(s,dt)
print("download completed!")
2.1.2 读取示例数据
import xarray as xr
ds = xr.open_dataset('./fnl_20180516_00_00.grib2',engine='pynio')
ds
2.2 NCEP-DOE Reanalysis 2 再分析数据
NCEP-DOE Reanalysis 2 is an improved version of the NCEP Reanalysis I model that fixed errors and updated paramterizations of physical processes.
这个数据比较好下,页面点一下就好了。
数据下载:https://psl.noaa.gov/data/gridded/data.ncep.reanalysis2.html
空间分辨率:2.5°×2.5°
时间分辨率:逐6小时
时间尺度:1979/01/01 to 2020/07/31
2.2.1 批量下载
主要3个参数
- start[int]:数据下载起始年份
- end[int]:数据下载种植年份
- url[string]:待下载数据连接
import requests
import lxml.html
import urllib
def dload_gfs(url, start, end, out_path=''):
try:
html = requests.get(url).text
except Exception as e:
print(e)
else:
doc = lxml.html.fromstring(html)
results = doc.xpath('//a/@href')
for link in results:
if '.nc' in link:
time = int(link.split('.')[-2])
print(link)
if time >= start and time <= end:
print(f'downloading {link} ...')
try:
r = urllib.request.urlopen(link, timeout=30).read()
except Exception as e:
print(e)
else:
with open(out_path + link.split('/')[-1], "wb") as f:
f.write(r)
if __name__ == "__main__":
url = 'https://psl.noaa.gov/cgi-bin/db_search/DBListFiles.pl?did=59&tid=81620&vid=4241'
start = 1979
end = 1981
out_path = ''
dload_gfs(url, start, end, out_path)
2.3 ERA 数据
ERA-Interim
ERA-Interim is a global atmospheric reanalysis that is available from 1 January 1979 to 31 August 2019. It has been superseded by the ERA5 reanalysis.
The data assimilation system used to produce ERA-Interim is based on a 2006 release of the IFS (Cy31r2). The system includes a 4-dimensional variational analysis (4D-Var) with a 12-hour analysis window. The spatial resolution of the data set is approximately 80 km (T255 spectral) on 60 levels in the vertical from the surface up to 0.1 hPa.
For a detailed documentation of the ERA-Interim Archive see Berrisford et al. (2011).
An open-access journal article describing the ERA-Interim reanalysis is available from the Quarterly Journal of the Royal Meteorological Society. Additional details of the modelling and data assimilation system used to produce ERA-Interim can be found in the IFS documentation Cy31r1. We are aware of several quality issues with ERA-Interim data.
下载地址:https://apps.ecmwf.int/datasets/data/interim-full-daily/levtype=sfc/
接口下载:批量下载ECMWF数据的正确姿势
ERA5
A first segment of the ERA5 dataset is now available for public use (1979 to within 5 days of real time). ERA5 provides hourly estimates of a large number of atmospheric, land and oceanic climate variables. The data cover the Earth on a 30km grid and resolve the atmosphere using 137 levels from the surface up to a height of 80km. ERA5 includes information about uncertainties for all variables at reduced spatial and temporal resolutions.
Quality-assured monthly updates of ERA5 are published within 3 months of real time. Preliminary daily updates of the dataset are available to users within 5 days of real time.
The entire ERA5 dataset from 1950 to present is expected to be available for use in 2020.
ERA5 combines vast amounts of historical observations into global estimates using advanced modelling and data assimilation systems.
ERA5 replaces the ERA-Interim reanalysis which stopped being produced on 31 August 2019. You can read about the key characteristics of ERA5 and important changes relative to ERA-Interim.
下载网站:https://cds.climate.copernicus.eu/
步骤:
1、注册账号,最好是edu结尾的邮箱
2、获取api秘钥,存在工作区下的.cdsapirc
3、检索数据
4、构建下载脚本,主要参数如下,支持grib格式和nc格式
接口下载详见:ERA5降水数据下载与绘图
# 在 K-Lab 里这个文件是隐形的,不过问题不大,修改代码如下
!echo -e 'url: https://cds.climate.copernicus.eu/api/v2\nkey: xxxxx:xxxxxxxxxx' > /home/kesci/work/.cdsapirc # 记得在 url 与 key 中间加上\n
!cat /home/kesci/work/.cdsapirc # 查看修改后的.cdsapirc文件内容
# 一个简单的下载示例
import cdsapi
c = cdsapi.Client()
c.retrieve(
'reanalysis-era5-single-levels',
{
'product_type': 'xxxxx',
'variable': 'xxxxx',
'year': 'xxxxx',
'month': 'xxxxx',
'day': 'xxxxx',
'time': 'xxxxx',
'format': 'grib',
},
'download.grib')
2.4 GFS/GDAS 数据 最常用的气象预报数据
The Global Forecast System (GFS) has been in NWS operations since 1980 and is continuously improved by the Global Climate and Weather Modeling Branch which conducts a program of research and development in support of the Environmental Modeling Center (EMC) (www.emc.ncep.noaa.gov) of the National Centers for Environmental Prediction (NCEP) (www.ncep.noaa.gov).
空间分辨率:0.25°×0.25°
时间分辨率:1h
下载地址:https://nomads.ncep.noaa.gov/
参考下载代码(以径向、纬向风为例):https://github.com/mapbox/webgl-wind/blob/master/data/download.sh
#!/bin/bash
GFS_DATE="20161120"
GFS_TIME="00"; # 00, 06, 12, 18
RES="1p00" # 0p25, 0p50 or 1p00
BBOX="leftlon=0&rightlon=360&toplat=90&bottomlat=-90"
LEVEL="lev_10_m_above_ground=on"
GFS_URL="http://nomads.ncep.noaa.gov/cgi-bin/filter_gfs_${RES}.pl?file=gfs.t${GFS_TIME}z.pgrb2.${RES}.f000&${LEVEL}&${BBOX}&dir=%2Fgfs.${GFS_DATE}${GFS_TIME}"
curl "${GFS_URL}&var_UGRD=on" -o utmp.grib
curl "${GFS_URL}&var_VGRD=on" -o vtmp.grib
grib_set -r -s packingType=grid_simple utmp.grib utmp.grib
grib_set -r -s packingType=grid_simple vtmp.grib vtmp.grib
2.5 葵花 8 号 Himawari-8 卫星数据
葵8数据下载需要注册,科研用途免费,通过也很快的。
JAXA Himawari Monitor:https://www.eorc.jaxa.jp/ptree/index.html
2.5.1 批量下载数据
#下载某类型数据简单示例
import urllib,os
import calendar
filepath = "路径"
year = 2018
for month in range(7,8):
for day in range(22,calendar.monthrange(year,month)[1]+1):
date_str = "%d%02d/"%(year,month)
time_str = "%d%02d/%02d/"%(year,month,day)
filenames = []
lines=urllib.request.urlopen("ftp://账号密码@ftp.ptree.jaxa.jp/jma/netcdf/"+time_str).readlines()
for line in lines:
if '06001' in line.decode("utf-8") :
filenames.append(line.split()[-1])
if not os.path.exists(filepath+"/"+date_str):
os.makedirs(filepath+"/"+date_str)
for filename in filenames:
if not os.path.exists(filepath+"/"+date_str+date_str+filename.decode("utf-8")):
f=urllib.request.urlopen("ftp://账号密码@ftp.ptree.jaxa.jp/jma/netcdf/"+time_str+filename.decode("utf-8"))
with open(filepath+"/"+date_str+filename.decode("utf-8"),"wb") as code:
code.write(f.read())
# 加强版
import os
import sys
import click
import ftplib
import ntpath
from tqdm import tqdm
from datetime import datetime
from datetime import timedelta
def files_list(d1, d2, tstep, product):
files = []
step = timedelta(minutes=tstep)
seconds = (d2-d1).total_seconds()
# generate basenames
for i in range(0, int(seconds), int(step.total_seconds())):
files.append(d1 + timedelta(seconds=i))
# get all files from sdate to edate by tstep
files = [date.strftime('%Y%m/%d/%H/') +
f'*H08_{date.strftime("%Y%m%d_%H%M")}_*_FLDK*nc'
for date in files]
return files
def downloadFiles(ftp, source, product, file, destination, debug):
# omit 'bet' version
files = [os.path.basename(f) for f in ftp.nlst(source+product) if os.path.basename(f).isdigit()]
# get the newest version
version = sorted(files, key=lambda x: float(x))[-1]
try:
ftp.cwd(os.path.dirname(source+product+'/'+version+'/'+file))
except OSError:
pass
except ftplib.error_perm:
print('Error: could not change to ' + os.path.dirname(source+product+'/'+version+'/'+file))
return 0
filename = ntpath.basename(file)
try:
filename = ftp.nlst(filename)[0]
ftp.sendcmd('TYPE I')
filesize = ftp.size(filename)
# create directory
if not os.path.exists(os.path.dirname(destination)):
os.makedirs(os.path.dirname(destination))
# download data
with open(os.path.dirname(destination)+'/'+filename, 'wb') as f:
# set progress bar
def file_write(data):
f.write(data)
ftp.retrbinary('RETR ' + filename, file_write)
if debug > 0:
print('Downloaded')
except:
print('Error: File could not be downloaded ' + filename)
return 0
return 1
def main(save_path, sdate, edate, tstep, product, username, password, debug):
server = 'ftp.ptree.jaxa.jp' # JAXA data server
source = '/pub/himawari/L2/'
save_path = os.path.join(save_path, "")
# get the list of datetime from sdate to edate by day
d1 = datetime.strptime(sdate, '%Y-%m-%d_%H:%M')
d2 = datetime.strptime(edate, '%Y-%m-%d_%H:%M')
# get filenames based on dates
files = files_list(d1, d2, tstep, product)
ftp = ftplib.FTP(server)
ftp.login(username, password)
for file in tqdm(files, desc='total progress'):
# iterate and download files
filename = ntpath.basename(file)
destination = os.path.join(save_path+file)
if debug > 0:
print('Downloading ' + filename + ' ...')
file_exist = downloadFiles(ftp, source, product, file, destination, debug)
# skip following steps if file isn't found
if not file_exist:
continue
# 下载Cloud Property (CLP)产品
if __name__ == '__main__':
main('./work','2020-08-01_11:00','2020-08-01_11:30',10,'CLP','xxx','xxx',1)
# 下载Aerosol Property (ARP)产品
if __name__ == '__main__':
main('./work','2020-08-01_11:00','2020-08-01_11:30',10,'ARP','xxx','xxx',1)
# 下载Photosynthetically Available Radiation (PAR)产品
if __name__ == '__main__':
main('./work','2020-08-01_11:00','2020-08-01_11:30',10,'PAR','xxx','xxx',1)
2.6 JRA-55 再分析数据
网址:https://jra.kishou.go.jp/JRA-55/index_en.html#
3. 其他(欢迎补充)
3.1 TEMIS遥感数据
网站:Tropospheric Emission Monitoring Internet Service
该网站上有很多关于空气污染监测、气候变化、紫外辐射相关的遥感产品,这里以Clear sky UV index为例提供一种批量下载方式。
3.1.1 批量下载数据
# -*- coding: utf-8 -*-
import urllib
import os
import datetime
def Schedule(a,b,c):
'''''
a:已经下载的数据块
b:数据块的大小
c:远程文件的大小
'''
per = 100.0 * a * b / c
if per > 100 :
per = 100
print('%.2f%%' % per)
def dateRange(start, end, step=1, format="%Y%m%d"):
strptime, strftime = datetime.datetime.strptime, datetime.datetime.strftime
days = (strptime(end, format) - strptime(start, format)).days
return [strftime(strptime(start, format) + datetime.timedelta(i), format) for i in range(0, days, step)]
for i in dateRange('20190901','20190905'):
url = 'http://www.temis.nl/uvradiation/archives/v2.0/'+i[0:4]+'/'+i[4:6]+'/uvief'+i+'.hdf'
local = os.path.join(i+'.hdf')
#urllib.request.urlretrieve(url,local,Schedule) # 显示下载进度
urllib.request.urlretrieve(url,local)
print(i+'下载完成')
3.1.2 读取示例数据
import xarray as xr
ds = xr.open_dataset("/home/kesci/work/20190901.hdf",engine='pynio')
ds
3.2 我国台风历史轨迹数据
台风历史轨迹数据除了BST以外,还可以通过温州台风网进行查询。两者数据略有差异,BST是之后对历史台风路径进行校正后发布的,其经纬度、强度、气压具有更高的可靠性,但是时间分辨率为6小时,部分3小时,这一点不如观测数据,温州台风网的数据是实时发布数据的记录,时间分辨率最高达1小时,对于台风轨迹具有更加精细化的表述。
3.2.1 下载数据
# 导入模块
import json
import urllib.request
import xlwt
import datetime
import os
os.makedirs('./typhoon')
# 设置浏览器参数
headers = {'Connection': 'Keep-Alive',
'Accept': 'text/html, application/xhtml+xml, */*',
'Accept-Language': 'en-US,en;q=0.8,zh-Hans-CN;q=0.5,zh-Hans;q=0.3',
'User-Agent':'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'}
for year in range(2019, 2020):
for num in range(1,30):
try:
number = str(year) + str(num).zfill(2)
chaper_url = 'http://data.istrongcloud.com/v2/data/complex/' + number + '.json'
req = urllib.request.Request(url=chaper_url, headers=headers)
data = urllib.request.urlopen(req).read()
data = json.loads(data)[0]
f = xlwt.Workbook(encoding = 'utf-8')
sheet1 = f.add_sheet(u'sheet1', cell_overwrite_ok = True)
sheet1.write(0,0,'台风编号')
sheet1.write(0,1,'中文名称')
sheet1.write(0,2,'英文名称')
sheet1.write(0,3,'时刻')
sheet1.write(0,4,'经度')
sheet1.write(0,5,'纬度')
sheet1.write(0,6,'强度等级')
sheet1.write(0,7,'气压')
sheet1.write(0,8,'风速')
sheet1.write(0,9,'风级')
sheet1.write(0,10,'移速')
sheet1.write(0,11,'移向')
sheet1.write(0,12,'radius7')
sheet1.write(0,13,'radius10')
sheet1.write(0,14,'radius12')
sheet1.write(0,15,'ne_7')
sheet1.write(0,16,'se_7')
sheet1.write(0,17,'sw_7')
sheet1.write(0,18,'nw_7')
sheet1.write(0,19,'ne_10')
sheet1.write(0,20,'se_10')
sheet1.write(0,21,'sw_10')
sheet1.write(0,22,'nw_10')
sheet1.write(0,23,'ne_12')
sheet1.write(0,24,'se_12')
sheet1.write(0,25,'sw_12')
sheet1.write(0,26,'nw_12')
for i in range(0,len(data['points'])):
sheet1.write(i+1,0,data['tfbh'])
sheet1.write(i+1,1,data['name'])
sheet1.write(i+1,2,data['ename'])
sheet1.write(i+1,3,str(datetime.datetime.strptime(data['points'][i]['time'],'%Y-%m-%dT%H:%M:%S')))
sheet1.write(i+1,4,data['points'][i]['lat'])
sheet1.write(i+1,5,data['points'][i]['lng'])
sheet1.write(i+1,6,data['points'][i]['strong'])
sheet1.write(i+1,7,data['points'][i]['pressure'])
sheet1.write(i+1,8,data['points'][i]['speed'])
sheet1.write(i+1,9,data['points'][i]['power'])
sheet1.write(i+1,10,data['points'][i]['move_speed'])
sheet1.write(i+1,11,data['points'][i]['move_dir'])
sheet1.write(i+1,12,data['points'][i]['radius7'])
sheet1.write(i+1,13,data['points'][i]['radius10'])
sheet1.write(i+1,14,data['points'][i]['radius12'])
if data['points'][i]['radius7_quad'] != 'null':
sheet1.write(i+1,15,data['points'][i]['radius7_quad']['ne'])
sheet1.write(i+1,16,data['points'][i]['radius7_quad']['se'])
sheet1.write(i+1,17,data['points'][i]['radius7_quad']['sw'])
sheet1.write(i+1,18,data['points'][i]['radius7_quad']['nw'])
else:
sheet1.write(i+1,15,'NaN')
sheet1.write(i+1,16,'NaN')
sheet1.write(i+1,17,'NaN')
sheet1.write(i+1,18,'NaN')
if data['points'][i]['radius10_quad'] != 'null':
sheet1.write(i+1,19,data['points'][i]['radius10_quad']['ne'])
sheet1.write(i+1,20,data['points'][i]['radius10_quad']['se'])
sheet1.write(i+1,21,data['points'][i]['radius10_quad']['sw'])
sheet1.write(i+1,22,data['points'][i]['radius10_quad']['nw'])
else:
sheet1.write(i+1,19,'NaN')
sheet1.write(i+1,20,'NaN')
sheet1.write(i+1,21,'NaN')
sheet1.write(i+1,22,'NaN')
if data['points'][i]['radius12_quad'] != 'null':
sheet1.write(i+1,23,data['points'][i]['radius12_quad']['ne'])
sheet1.write(i+1,24,data['points'][i]['radius12_quad']['se'])
sheet1.write(i+1,25,data['points'][i]['radius12_quad']['sw'])
sheet1.write(i+1,26,data['points'][i]['radius12_quad']['nw'])
else:
sheet1.write(i+1,23,'NaN')
sheet1.write(i+1,24,'NaN')
sheet1.write(i+1,25,'NaN')
sheet1.write(i+1,26,'NaN')
f.save('typhoon/' + number + '.xls')
print(number+ '.xls 已下载' )
except:
break
3.2.2 读取示例数据
import pandas as pd
df = pd.read_excel('typhoon/201901.xls')
df
3.3 CMIP6 国际耦合模式比较计划
3.3.1 CMIP简介
官网:https://www.wcrp-climate.org/wgcm-cmip
CMIP是国际耦合模式比较计划(Coupled Model Intercomparison Project)的缩写,最早是在 1995 年由世界气候研究计划(WCRP)下属的耦合模式工作组(WGCM)主持开展的。自 CMIP 诞生以来,一直致力于促进气候模式的发展和完善,并支持气候变化的评估和预估工作。目前已开展了 5 次耦合模式比较计划,当前正在进行的是第 6 次耦合模式比较计划,即 CMIP6。基于 CMIP 计划的气候变化研究,是气候评估和谈判的重要基础,也为 IPCC 气候变化评估报告的撰写提供了参考价值。
美国劳伦斯利弗莫尔国家实验室(LLNL)的气候模式诊断和比较计划项目(PCMDI)多年来一直对 CMIP 计划提供支持,包括确定该计划的 Scope、提供下载的平台等。目前,CMIP6 数据的下载仍主要由 LLNL 支持的网站获取。
WCRP 的大科学挑战(WCRP,2016)是发起和组织 CMIP 计划的重要科学背景。描述 CMIP6 试验设计和组织的文章发表于 2016 年(Erying et al. 2016),此后在 2018 年 CMIP6 共批准了 23 个子计划。这些标准的气候模拟比较计划,凝练出七大迫切需要解决的、并有望在未来 5-10 年取得显著进步的科学问题,包括:
- 冰冻圈消融及其全球影响
- 云、环流和气候敏感度
- 气候系统的碳反馈
- 极端天气和气候事件
- 粮食生产用水
- 区域海平面升高及其海岸带影响
- 面向未来几年到10-20年的近期气候预测
根据以上问题着重于回答以下三大科学问题:
- 地球系统如何响应外强迫;
- 当前气候模式的系统性偏差产生的原因及其影响;
- 在气候系统内部变率、可预报性和未来预估情景不确定的情况下如何对未来气候变化进行预估。

CMIP6 计划的试验设计有三个层次,即:
(i)核心的 DECK 试验。DECK 是气候诊断、评估和描述(Diagnostic,Evalutationand Charcaterization of Klima)的缩写。DECK 试验是 CMIP 计划的入门试验,任何完成 DECK 试验并参与国际共享的模式,即被认为参与了 CMIP 计划。
(ii)第二级的历史气候模拟试验(historical 试验)。historical 试验是 CMIP6 计划的入门试验,任何完成 historical 试验并参与国际共享的模式,即被认为参与了 CMIP6 计划。
(iii)在两级入门试验的外层是 CMIP6 的 23 个模拟比较子计划(MIPs)。关于各子计划的目标和细节,以及更详细的内容,可参看文末提供的参考文章。
参考资料:
1、https://esgf-node.llnl.gov/projects/cmip6/
2、Eyring, V., Bony, S., Meehl, G. A., Senior, C. A., Stevens, B., Stouffer, R. J., and Taylor, K. E.: Overview of the Coupled Model Intercomparison Project Phase 6 (CMIP6) experimental design and organization, Geosci. Model Dev., 9, 1937–1958.
3、周天军, 邹立维, 陈晓龙. 第六次国际耦合模式比较计划(CMIP6)评述. 气候变化研究进展[J], 2019, 15(5): 445-456.
3.3.2 acccmip6 模块安装
!pip install acccmip6
# 测试是否安装成功
!acccmip6
官方文档:https://acccmip6.readthedocs.org/
3.3.3 下载数据
# 查看可下载模式
!acccmip6 -o M -m show
数据搜索
所有搜索都可以使用 acccmip6 -o S,该命令需在命令行模式下输入,具体包含下面几个参数:
OPTINAL ARGUMENTS 1
USE THESE ARGUMENTS WITH ANY COMBINATION AND IN ANY SEQUENCE.
Optinal arguments 1
Use these arguments with any combination and in any sequence.
-m: takes model names-e: takes experiment names-v: takes variable names-f: takes frequency-r: takes realm name
Optional arguments 2
-c: ‘yes’ to check the inputs under optional argumetns 1. Searches through the servers and checks whether the input items are available or not.
Get suggestions: use the -c argument when in doubts whether any input item is available in the current database.
Optional arguments 3
-desc: ‘yes’ to get the description of the experiments searched with -e argument. The descriptions comes at the end of the general search results.
# 查看可下载数据
!acccmip6 -o S -m MIROC6 -v vas -f mon -r atmos
下载数据的命令都以 acccmip6 -o D 开头,后面添加参数,具体如下:
Use these optional arguments with in addition to Optional arguments 1 and Optional arguments 2.
-dir: select directory. If kept blank, acccmip6 will ask for a directory. With no inputs, download will continue in CMIP6 directory.-rlzn: select realization-skip: skip items during download
# 批量下载数据(我示例一下就中断了,不是报错)
!acccmip6 -o D -e hist-piNTCF -v vas -m MIROC6 -dir /home/kesci/CMIP6


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









