






环境:
数据库版本:8.0.21
数据量级:百万级数据;
innodb引擎数据:
mysim引擎数据:
表结构:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HoHZIg7A-1656078006417)(mysql%E6%B5%8B%E8%AF%95.assets/image-20220624213618496.png)]](https://img-blog.csdnimg.cn/578512a9aec64e228f8f0b6abbf252b3.png)
知识点前瞻:
explain字段详解:
全字段讲解:https://blog.csdn.net/sinat_16998945/article/details/124862635
研究过程:
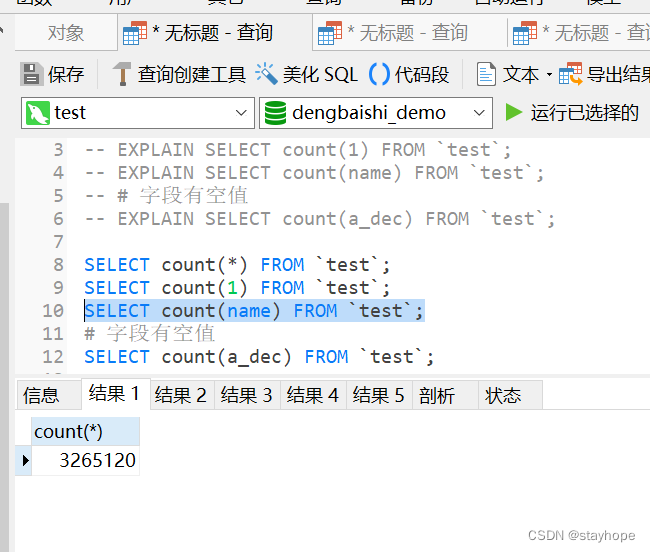
一、在innodb引擎下
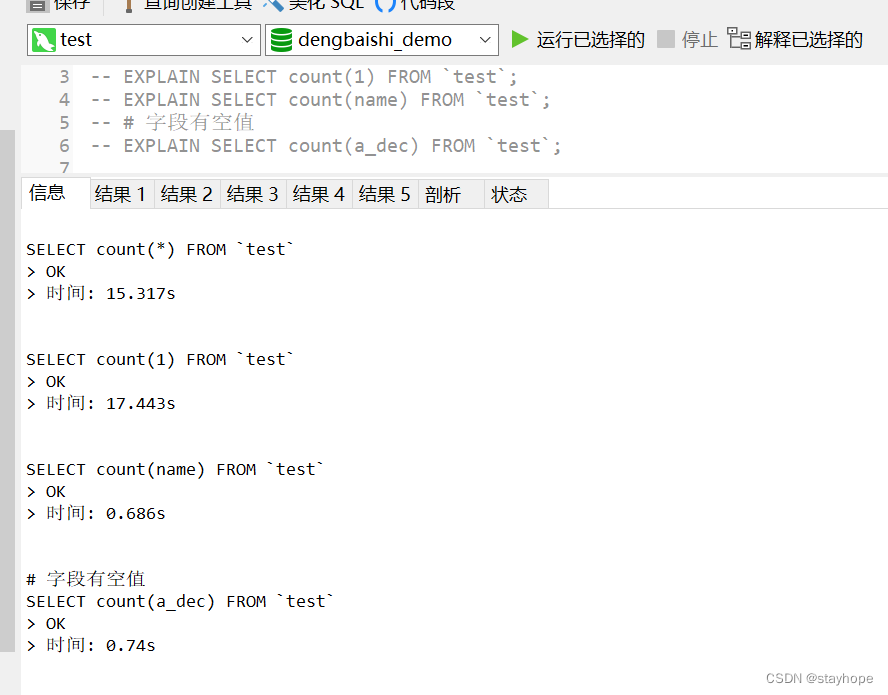
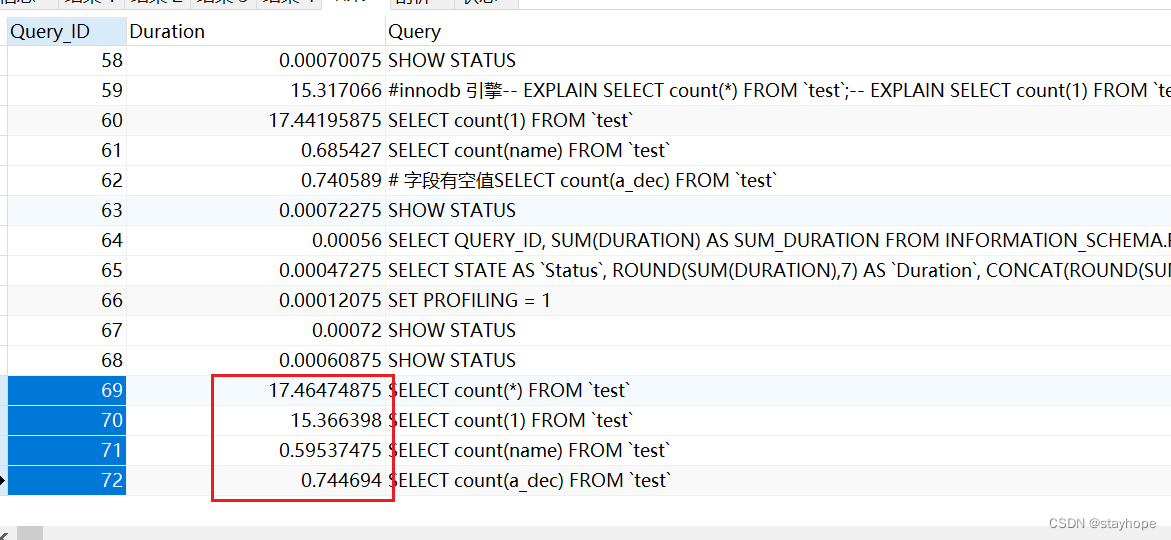
比较结果:从上面的结果比较中,很清楚的能看到count(字段)的查询效率要高于count(*)和count(1);而带有空值的字段列又比没有空值的字段快;
原因:
不同count的用法:
-
count(主键ID)
innodb引擎会遍历整张表,把每一行的ID值都那出来,然后返回给server层,server层拿到ID后,判断不可能为空,进行累加
-
count(1)
同样遍历整张表,但不取值,server层对返回的每一行,放一个数字1进去,判断是不可能为空的,按行累加。
-
count(*)
会被优化,不取出全部字段,直接按行累加(走的主键,主键不可能为空)
-
count(字段)
分为两种情况,字段定义为not null和null:
- 为not null时:逐行从记录里面读出这个字段,判断不能为null,累加
- 为 null时:执行时,判断到有可能是null,还要把值取出来再判断一下,不是null才累加。
结论:
按照效率:字段>*>1
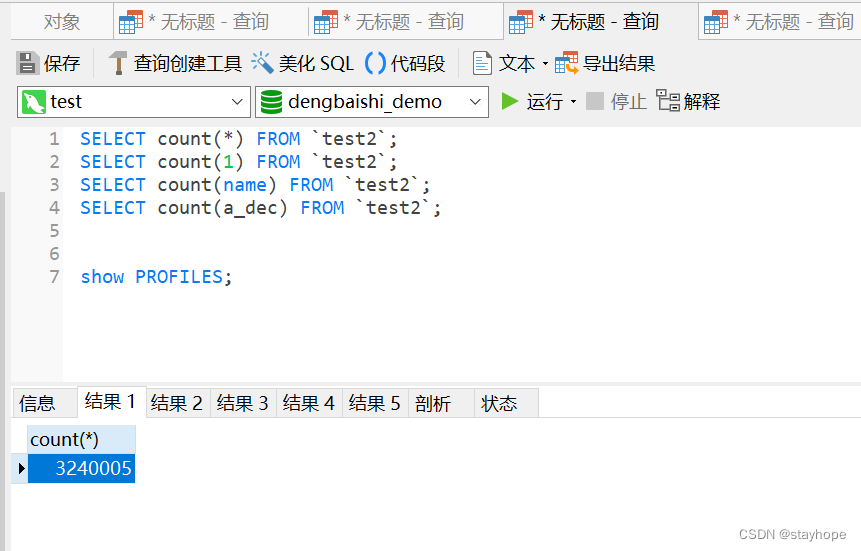
二、在myisam引擎下
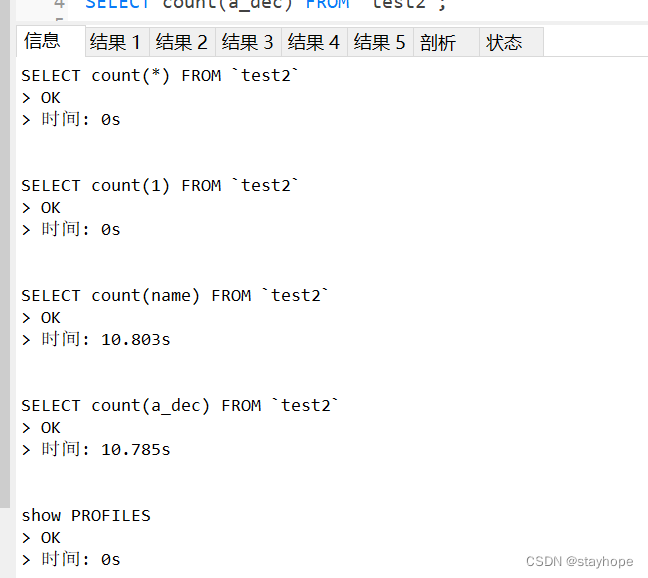
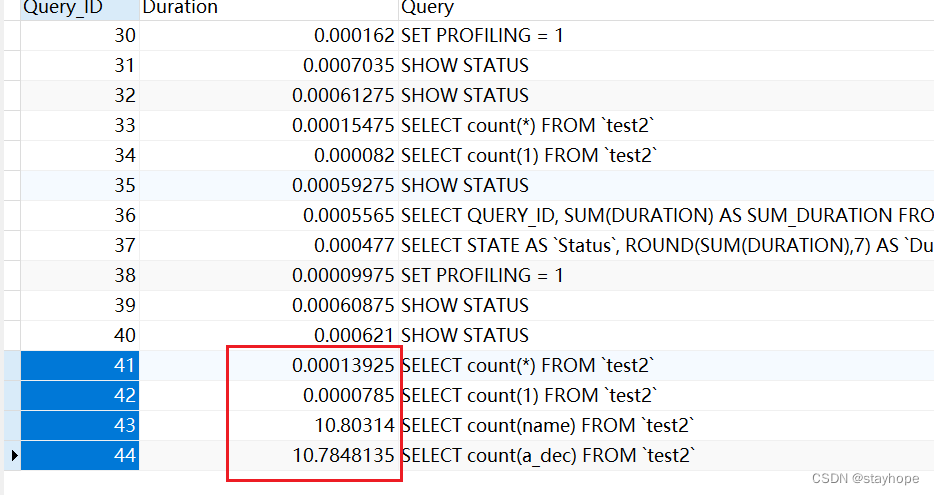
比较结果:从上面的结果比较中,很清楚的能看到count(*)和count(1)的查询效率要高于count(字段);
原因:
mysiam会记录表的行数,但是遇到count(*)包含where或者某个具体字段时,也会去扫描全表;
结论:
按照效率:count(*)>count(1)>count(字段)
全文总结:
mysiam在count查询上,效率要明显高于innodb;















 699
699











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









