







说到Redis的数据结构你首先想到的是什么?会脱口而出当然是String、List、Map、Set、Sorted Set,其实这些只是Redis对外暴露出来的键值对的值,我们使用Redis一般是当做<K, V>型数据库,而刚才脱口而出的只不过是其中的value值得类型。那么在Redis中这几种常用的数据类型到底是如何实现的呢,接下来我们来看看。
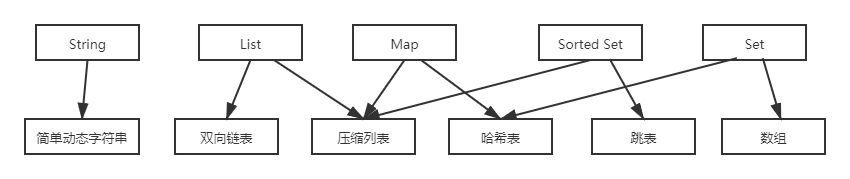
对于String在Redis底层实现只采用了一种数据结构来实现,那就是简单动态字符串,而其余的几种数据结构底层都用分别采用两种数据结构实现。除去String其余四种数据结构可以统称为集合,那么何种情况下会对于不同的数据结构实现呢?下面的图进行了总结

这里对于简单动态字符串我们平时并不经常接触,Redis没有有采用传统的字符串实现方式,而是自己实现了字符串结构,简单字符串的结构如下图

这里有几个字段需要说明一下,zlbytes、zltail、zllen,这前三个字段zlbytes表示列表长度,zltail表示列表尾的偏移量,zllen表示列表中entry的个数,列表最后一个zlend表示列表的结束。有这些字段我们可以在O(1)的时间内找的列表的头部和尾部节点。这种数据结构非常紧凑,没有多余的字段节省了不少的内存开销,而且连续的存储结构对cup缓存比较友好。
那么Redis底层为什么要搞这么多的数据结构来实现数据的存储呢,其实这里还是为了找寻时间和空间的一个平衡。如果数据量不大的话(很多情况下是比较小的值),那么使用压缩就可以节省内存空间,但是当数据量比较大的话依然使用这种压缩格式的话查询效率就比较低,这时可以使用哈希表跳表等结构提升查询效率。
以上介绍的这些数据结构都是Redis中的V,我们使用Redis的时候都是通过key value的形式进行操作的,所以Redis内部是有个全局哈希表的(准确的说应该是两个,另外一个用于扩容),我们通过key的hash算法找的对应的数组下表,然后数组中存储着entry的引用地址,找的entry对象后entry对象内部存放了key和要操作集合的对象引用地址(value),找的value后才可以对集合对象进行操作。















 8万+
8万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









