







今天好颓废……晚上刚看到微信里的头脑王者小程序,玩了俩小时,把学习计划推到了现在……
2.1 经验误差与过拟合
上一章后面讲了NFL,这并不能阻挡我们现实中对具体问题各种候选模型进行择优的激情。这一章我们学习模型的评估和选择方法。先看几个简单的概念。
误差:学习器的实际预测输出和样本的真实输出之间的差异;
训练误差:学习器在训练集上的误差。也叫经验误差;
泛化误差:在新样本上的误差。
我们构建的模型,最终极的目的就是想让它在新的样本上表现优秀,即泛化误差小。然而我们事先并不知道新样本,手里只有训练样本。所以我们只有努力把训练误差降到最低。
那是不是训练误差越小越好呢?举个例子:我们想设计一个学习器判断一个生物是不是人。训练样本是姚明。如果学习器训练误差很小,即很出色的学习了样本的细节特征(极端特征也学会了)。那么这个学习器适用性如何?
很显然不行,比如我给它一个小朋友,它会判断你不是人,因为你的身高不到2米。So terrible!
那增大训练误差呢(学习特征不足)?可以想象这样的学习器判断一只猪时可能也会给“是人”的答案。因为它说这个样本有眼睛。
前一种我们成为“过拟合”,学习器学习能力太强大了;后一种成为“欠拟合”,学习能力低下。
一般而言,欠拟合易解决,过拟合是难题,且无法避免,只可缓解。
2.2 评估方法(实验估计法)
考虑现实问题:最理想的是评估泛化误差,但无法直接获得;用训练误差又因为存在过拟合问题。所以有没有别的办法来评估与选择模型呢?
肯定有啊,嘿嘿。
我们的思路是再多加一个数据集,叫“测试集”,用它来测试学习器的误差,作为泛化误差的近似。其实说白了,一般我们是把原来的训练集分成两部分,一部分训练,一部分测试,这可以保证二者互斥(这点很重要)。怎么分呢?
介绍三种经典的分法:
A、留出法
直接把数据集分成两部分,训练集容量和测试集之比一般为2:1到4:1。
这里注意用“分层采样”以及随机划分、重复实验取平均的技巧。
B、交叉验证法
将D划分为k个大小相似的互斥子集。(D通过分层采样得到每个子集Di,保持数据分布一致性)。每次用k-1个子集的并集作为训练集,余下那个作测试集。即可获得K组训练/测试集,进行K次训练和测试,最终返回k个测试结果的均值。也称”k折交叉验证”。

同留出法,也是需要随机划分、多次实验取平均。
交叉验证法特例:m个样本划分成m个子集,每个子集包含一个样本。留一法中被实际评估的模型与期望评估的用D训练出来的模型很相似,因此,留一法的评估结果往往被认为比较准确。当然也有弊端,数据集太大的话,计算量大的要死。
C、自助法
回想刚才的几种方法,均是对训练集的容量有缩减,这就必然会引入误差。如果能保持训练样本数不变,还能有训练样本来测试就好了。
这就是自助法的意义了。
从m个样本的数据集D,随机采样(选)一个样本,拷贝入训练D’,放回,继续随机挑选,直至m次。
样本在m次采样中始终不被采到的概率(1-1/m)^m。
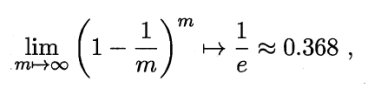
实际评估的模型与期望评估的模型都使用m个训练样本,而仍有约1/3的没有在训练集的样本用于测试。
自助法一般在数据集小时采用。数据集充足时,还是用留出法和交叉验证法更多一些。
2.3性能评估
上面的实验估计已经用测试集得到了测试样本的预测。拿到这些预测,我们怎么判断谁好谁坏呢?这需要建立性能度量的评价标准。
最常见的“均方误差”:
给定样例集D={(x1,y1),(x2,y2),……,(xm,ym)},yi是对xi的真实标记,要评估学习器f的性能,就要把学习器预测结果f(x)与真实标记y进行比较。
均方误差:
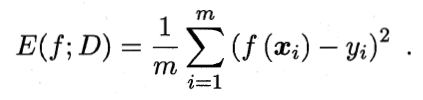
更一般地,数据分布D和概率密度函数p(.),均方误差:

A、分类任务中,常见性能度量是“错误率”与“精度”。
对样例集D,分类错误率定义为:
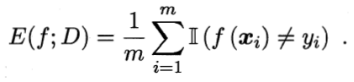
II(.)是指示函数,里边为真则值为1,反之为0。
精度为很简单,1-E(f;D)即可。
B、查准率、查全率和F1
错误率和精度在有些情况不合适。比如,还是挑西瓜,一车西瓜我买了一部分,我更关系的是我挑出来的有多少好瓜,我对整个一车的判别情况不感兴趣(错误率)。
先看二分类问题混淆矩阵:

分类结果无外乎这四种。
定义查准率P:

可以想象,我挑的瓜我肯定以为都是好瓜,即(TP+FP),但是里面真正是好瓜的只有TP。体现了一个正确率。
查全率R:

可以想象,原来一车瓜里有100个好瓜(TP+FN),我挑了100个,里面只有50(TP)个好瓜。二者之比体现的是全面性。
自己可以简单推想,P和R二者一般是负相关的。
有了这两个指标怎么判断两个学习器优劣?不是说P和R负相关吗?那一般肯定是一个大一个小。不好比较。
思路是根据学习器的预测结果对样例排序。最可能是正例的放前面,往后以此可能性降低。比如说正例为1,反例为0(label)。我现在预测的结果是{0.3,0.1,0,7,0.9}。我就应该这么排样例{0.9,0.7,0.3,0.1}。因为0.9标记的样例很显然更有可能是正例。
按顺序把样例按正例预测,得到”P-R图”如下:

很容易理解,曲线B代表的学习器性能优于C(面积更大)。对A和B,分别求其平衡点(BEP),谁高谁优越。
(平衡点即是P=R)。
如果觉得BEP太简单了,可以用F1度量:

谁大选谁。
如果想对P和R有不同的重视程度,可以把F1一般化:

β越大,查全率越重要。
好了,上面是一次训练/测试,那一般我们是多次训练/测试,怎么算P、R?
很自然的想到,要么我每次都算一组Pi和Ri,最后平均一下就好了,然后用平均的值,来算F1;要么我提前就把TP、FP、FN这些求平均,再计算P和R,F1。
这样想是没问题的,前者对应宏查准率,宏查全率,以及宏F1。后者对应微查准率,微查全率,以及微F1。(式子很简单,不写了)
C、ROC和AUC
引入两个定义:

TPR其实和前面查全率写法一致,我们叫真正例率。
FPR:(TN+FP),所有客观的反例,FP,被误判为真例的假例。FPR叫做假正例率。
我们还是按照画P-R图的方法画ROC图,只不过把横轴换成FPR,纵轴换成TPR。如下:

左边是理想的很多测试样例的绘制结果,右边是现实有限的样例绘制结果。
关注几个点:
(0,0)点:阈值设置的极高,把所有样例都划成反例。
(0,1)点:理想情况,所有正例被完美的排序在反例前面。
(1,0)点:最糟糕了,所有预测都是错的
(1,1)点:包括其在内的整个对角线,我们把它看作是随机猜想,就是瞎几把排序。
与P-R曲线一样,如果一个学习器的ROC曲线被另一个完全包围了,那么我们认为后者性能更好。若交叉,则判断AUC,即ROC下面的面积。
D、代价敏感错误率和代价曲线。
提出这个是考虑到现实中犯各类错误成本是不一样的,试想判断一个健康的人有病和判断有病的人健康,代价能一样吗?
看一下二分类代价矩阵:

代价敏感错误率:
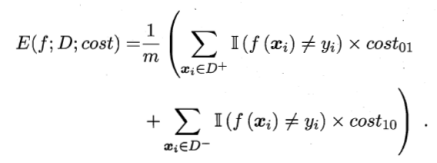
代价曲线:

横轴:正例概率代价
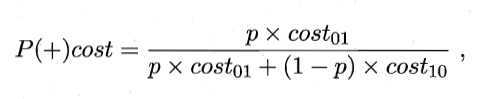
纵轴:归一化代价
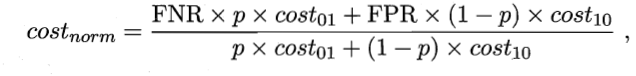
画法是从ROC的一点映射到代价曲线的一条线。所有线画完,取所有线的下界,围成面积即期望总体代价。
2.4比较检验
(其实机器学习概率统计知识真的是非常多,当年没认真学,所以一些东西还得从头翻书……)
这一步是干嘛呢?很简单,就是你用有限的测试集得出学习器A和B的性能度量,并且判断A优于B,那么这个判断靠谱吗?明明学习器面向的是未知的浩瀚样本,你凭什么靠有限的测试集就做判断了?
这个就是要靠假设检验了,他的目的是,我如果在测试集上判断A优于B,那么A的泛化性能是不是在统计意义上优于B?这个把握有多大?(置信度嘛)
提前说明,一般这一步我们习惯用错误率є来作性能度量。
A、假设检验
对一个学习器的一次训练/测试,得到测试错误率。那么任务是由来估计泛化错误率є。
直接这么说吧,包含m个样本的测试集上,泛化错误率为的学习器被测得测试错误率为的概率:

求导的话,可得є=时,P最大。什么意思呢?就是这个学习器的泛化错误率你是不知道的,但是如果你测试的话,那么你的测试错误率等于泛化错误率的概率是最大的,你有理由估计说є很可能是。
好,现在我们想检验这样的假设“є<=є0”。置信度1-ɑ。怎么做?
可以求一个临界值:

如果测试错误率小于临界值,则接受假设。反之拒绝。
类似的,我们还是会做重复实验,那么得到多个测试错误率。此时用“t检验”。假定k个测试错误率。
平均测试错误率μ和方差σ²为:

这k个独立同分布。则:
服从自由度k-1的t分布。є0为泛化错误率。
对假设μ-和显著度ɑ,考虑双边假设。若平均错误率μ与之差|μ-|位于临界值范围内,则可认为泛化错误率为,置信度为1-α;否则,认为在该显著度下可认为泛化错误率与有显著不同。
B、交叉验证t检验
上面的假设检验我认为已经为每个学习器的泛化错误率估计提供了依据,也就是用上面的知识就可以解决问题了。这里再说一个比较两个学习器的方法。
两个学习器A、B,若使用k折交叉验证法得到的测试错误率分别为,其中是在相同的第i折训练/测试集上得到的结果,可用k折交叉验证”成对t检验”来进行比较检验。,使用相同的训练/测试集的测试错误率相同,两个学习器性能相同。
k折交叉验证产生k对测试错误率:对没对结果求差;若性能相同则是0。用,t检验,计算差值的均值μ和方差σ²。
若变量小于临界值,则认为两个学习器的性能没有显著差别;否则,可认为两个学习器性能有显著差别,错误平均率小的那个学习器性能较优。
以上假设检验前提是测试错误率均为泛化错误率的独立采样,但是你看像交叉验证这种方法,样本有限,每次训练集一定有重合,所以这个前提其实是不成立的。解决方法有”5*2交叉验证”。不多赘述。
2.5偏差和方差
这个我觉得不用对详细的推导清楚,大概感性体会一下这个式子:
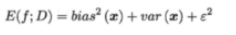
E(f:D)是学习算法的期望泛化误差;
bias^2(x)是期望输出与真实标记的差,叫偏差;
Var(x)是使用样本数相同的不同训练集产生的方差。
Є^2是噪声。
结合这个图分析一波:
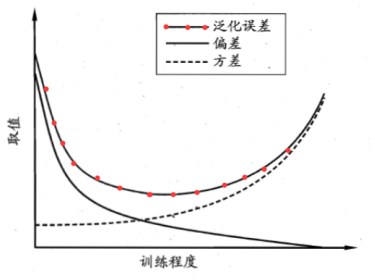
训练程度不足时,偏差对泛化误差起显著影响;训练充足后,偏差减小,但训练数据的扰动被学到,方差开始占主导作用。到最后,过拟合,数据轻微扰动会使学习器显著变化。
不难看出,偏差和方差是有冲突的,控制住一个,另一个又不理想了。这叫“偏差-方差窘境”。
See You.















 2922
2922

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









