







LMDeploy 部署 VLMs 的方法与探讨
感谢LMDeploy项目负责人吕晗老师的分享!
01
LMDeploy简介
LMDeploy 是一个高效且友好的大型语言模型(LLMs)和视觉-语言模型(VLMs)部署工具箱,由上海人工智能实验室模型压缩和部署团队开发,涵盖了模型量化、离线推理和在线服务等功能。
1.1 软硬件平台
支持的软硬件平台包括:
- Linux、Windows 系统 + NVIDIA 显卡。运行时,cuda runtime的最低要求是11.3。支持的 NVIDIA 显卡型号包括:
- Volta(sm70): V100
- Turing(sm75): 20 系列,T4
- Ampere(sm80,sm86): 30 系列,A10, A16, A30, A100 等
- Ada Lovelace(sm89): 40 系列
- Hopper(sm90):H100(尚未深度优化)
- Huawei 910b
1.2 项目结构****
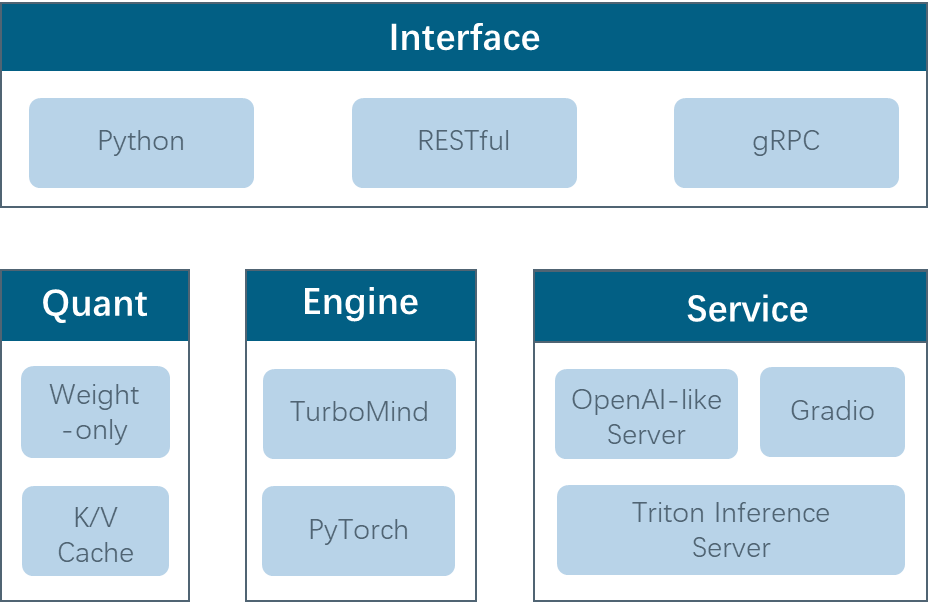
1.2.1 接口层
Python:离线推理
RESTful:访问在线服务
gRPC:访问 triton inference server 接口。没有支持 VLM 模型
1.2.2 量化层
权重量化:支持 AWQ 和 SmoothQuant 算法
K/V Cache:KV在线量化
1.2.3 引擎层
**TurboMind 引擎:**起源于 FasterTransformer,由 C++ 和 CUDA 开发,致力于推理性能的优化
**PyTorch 引擎:**采用纯 Python 开发,kernel 部分使用 openai triton 编写,旨在降低开发者的门槛
两个引擎互为补充,相辅相成,共同打造了 LMDeploy 的基石
1.2.4 服务层
OpenAI-like Server:推理服务,兼容 openai 接口
Gradio:web demo的服务
Triton Inference Server:不支持 VLM。LLM 也不推荐
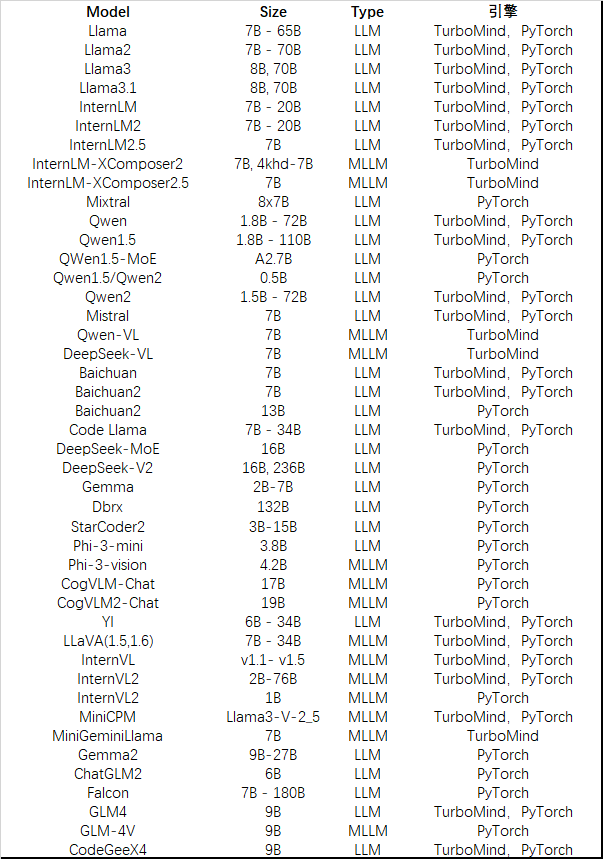
1.3 支持的模型
02
LMDeploy 使用指南之 VLMs 部署
2.1 环境安装
**方案 1:**创建一个干净的 conda 环境,pip安装 lmdeploy。支持的 python 版本是 3.8 - 3.12
conda create -n lmdeploy python=3.8 -y
conda activate lmdeploy
pip install lmdeploy
到这里为止,可以使用 lmdeploy 部署 LLM 模型。
但,如果要部署 VLM 模型,比如 InternVL系列,InternLM-XComposer系列、LLaVA 等等,需要安装上游模型库需要的依赖。原因,LMDeploy 对 VLMs 视觉部分的模型推理以及图像预处理,是复用上游库的。
以 InternVL2 模型为例,还需要安装:
pip install timm
# 建议从https://github.com/Dao-AILab/flash-attention/releases寻找和环境匹配的whl包
pip install flash-attn
因为复用VLMs上游库关于图像的预处理和视觉模型的推理,且不同的VLM依赖各不相同,出于维护性方面的考虑,LMDeploy 没有把 VLMs 的依赖,比如 timm,flash-attn,放在自己的依赖列表里。
但是,torchvision放入了依赖列表。原因是,LMDeploy 依赖 torch,担心用户安装 torchvision 时没留意torch的版本,安装了不匹配的。(后续考虑移除,相信用户)
**方案 2:**docker 镜像
LMDeploy 只提供可以部署 LLM 模型的镜像,不提供部署 VLM 的镜像,理由如上。
推荐用户基于 LMDeploy 镜像构建 VLM 部署镜像,比如:
ARG CUDA_VERSION=cu12
FROM openmmlab/lmdeploy:latest-cu12 AS cu12
FROM openmmlab/lmdeploy:latest-cu11 AS cu11
RUN python3 -m pip install timm
# 建议从https://github.com/Dao-AILab/flash-attention/releases寻找和环境匹配的whl包
RUN python3 -m pip install flash-attn
LMDeploy 镜像的命名方式如下:
openmmlab/lmdeploy:latest-cu12
openmmlab/lmdeploy:latest-cu11
openmmlab/lmdeploy:latest # 和 openmmlab/lmdeploy:latest-cu12 一致
openmmlab/lmdeploy:{tag}-cu12 # 比如 openmmlab/lmdeploy:v0.5.3-cu12
openmmlab/lmdeploy:{tag}-cu11
2.2 离线推理
以 InternVL2-8B 模型为例,最简单的 “Hello, world” 式的推理方式如下:
from lmdeploy import pipeline
from lmdeploy.vl import load_image
pipe = pipeline('OpenGVLab/InternVL2-8B')
image = load_image('https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/tests/data/tiger.jpeg')
response = pipe(('describe this image', image))
print(response)
在构造 pipeline 时,如果没有指定使用 TurboMind 引擎或 PyTorch 引擎进行推理,LMDeploy 将根据它们各自的能力自动分配一个,默认优先使用 TurboMind 引擎。
当然,你可以手动选择一个引擎,我们将在推理引擎配置章节中,详细介绍两种引擎的配置方法。
2.2.1 创建 pipeline
2.2.1.1 API
def pipeline(model_path: str,
model_name: Optional[str] = None,
backend_config: Optional[Union[TurbomindEngineConfig,
PytorchEngineConfig]] = None,
chat_template_config: Optional[ChatTemplateConfig] = None,
log_level='ERROR',
**kwargs):
model_path:模型路径
- 可以是 huggingface hub 上的 model_repo_id
- 可以是 modelscope hub 上的 model_repo_id。在这种情况下,需要安装modelscope,并设置环境变量
pip install modelscope
export LMDEPLOY_USE_MODELSCOPE=Tru
- 对于 LLM 模型来说,它可以是经多 lmdeploy convert 转换后的模型的路径。不支持离线转换 VLMs 模型
model_name:内置对话模板名称
- v0.6.0(尚未发布)将会移除这个参数,用 ChatTemplateConfig 中的 model_name 替代
| backend_config | 推理引擎配置参数 |
|---|---|
| chat_template_config | 对话模板参数 |
| log_level | 日志级别。默认为 ERROR |
| vision_config | 视觉模型推理的配置参数 |
- vision_config 被隐藏在 kwargs 中了
2.2.1.2 推理引擎配置
引擎参数的定义
Turbomind
@dataclass
class TurbomindEngineConfig:
model_format: Optional[str] = None
tp: int = 1
session_len: Optional[int] = None
max_batch_size: int = 128
cache_max_entry_count: float = 0.8
cache_block_seq_len: int = 64
enable_prefix_caching: bool = False
quant_policy: int = 0
rope_scaling_factor: float = 0.0
use_logn_attn: bool = False
download_dir: Optional[str] = None
revision: Optional[str] = None
max_prefill_token_num: int = 8192
num_tokens_per_iter: int = 0
max_prefill_iters: int = 1
Pytorch
@dataclass
class PytorchEngineConfig:
tp: int = 1
session_len: int = None
max_batch_size: int = 128
cache_max_entry_count: float = 0.8
eviction_type: str = 'recompute'
prefill_interval: int = 16
block_size: int = 64
num_cpu_blocks: int = 0
num_gpu_blocks: int = 0
adapters: Dict[str, str] = None
max_prefill_token_num: int = 4096
thread_safe: bool = False
enable_prefix_caching: bool = False
device_type: str = 'cuda'
download_dir: str = None
revision: str = None
引擎通用的参数:
- 单机多卡推理(tp)
tp用于张量并行时的GPU数量,缺省值 1,目前被约束为2n
LMDeploy 只支持单机多卡,不支持多机多卡
Turbomind
from lmdeploy import pipeline
from lmdeploy import TurbomindEngineConfig
pipe = pipeline(
'OpenGVLab/InternVL2-8B',
backend_config=TurbomindEngineConfig(
tp=2))
Pytorch
from lmdeploy import pipeline
from lmdeploy import PytorchEngineConfig
pipe = pipeline(
'OpenGVLab/InternVL2-8B',
backend_config=PytorchEngineConfig(
tp=2))
- 设置内存使用量(cache_max_entry_count)
cache_max_entry_count 表示加载模型权重后 K/V 缓存占用的空闲 GPU 内存的比例。默认值是 0.8。
K/V 缓存分配方式是一次性申请,重复性使用,这就是为什么 pipeline 以及下文中的 api_server 在启动后会消耗大量 GPU 内存。
如果你遇到内存不足(OOM)错误的错误,可能需要考虑降低 cache_max_entry_count 的
Turbomind
from lmdeploy import pipeline
from lmdeploy import TurbomindEngineConfig
pipe = pipeline(
'OpenGVLab/InternVL2-8B',
backend_config=TurbomindEngineConfig(
tp=2))
Pytorch
from lmdeploy import pipeline
from lmdeploy import PytorchEngineConfig
pipe = pipeline(
'OpenGVLab/InternVL2-8B',
backend_config=PytorchEngineConfig(
tp=2))
- 设置最大推理长度(session_len)
session_len表示上下文窗口的最大长度,包括输入的prompt token个数和输出的token个数
Turbomind
from lmdeploy import pipeline
from lmdeploy import TurbomindEngineConfig
pipe = pipeline(
'OpenGVLab/InternVL2-8B',
backend_config=TurbomindEngineConfig(
session_len=8192))
Pytorch
from lmdeploy import pipeline
from lmdeploy import PytorchEngineConfig
pipe = pipeline(
'OpenGVLab/InternVL2-8B',
backend_config=PytorchEngineConfig(
session_len=8192))
- 设置推理最大batch(max_batch_size)
max_batch_size 表示 Continuous batching 推理时,最大的批处理数量
Turbomind
from lmdeploy import pipeline
from lmdeploy import TurbomindEngineConfig
pipe = pipeline(
'OpenGVLab/InternVL2-8B',
backend_config=TurbomindEngineConfig(
max_batch_size=256))
Pytorch
from lmdeploy import pipeline
from lmdeploy import PytorchEngineConfig
pipe = pipeline(
'OpenGVLab/InternVL2-8B',
backend_config=PytorchEngineConfig(
max_batch_size=256))
- 设置 prefix caching 开关(enable_prefix_caching)
Turbomind
from lmdeploy import pipeline
from lmdeploy import TurbomindEngineConfig
pipe = pipeline(
'OpenGVLab/InternVL2-8B',
backend_config=TurbomindEngineConfig(
enable_prefix_caching=True))
Pytorch
from lmdeploy import pipeline
from lmdeploy import PytorchEngineConfig
pipe = pipeline(
'OpenGVLab/InternVL2-8B',
backend_config=PytorchEngineConfig(
enable_prefix_caching=
- 设置prefill chunk的最大token数(max_prefill_token_num)
Turbomind
from lmdeploy import pipeline
from lmdeploy import TurbomindEngineConfig
pipe = pipeline(
'OpenGVLab/InternVL2-8B',
backend_config=TurbomindEngineConfig(
max_prefill_token_num=8192))
Pytorch
from lmdeploy import pipeline
from lmdeploy import PytorchEngineConfig
pipe = pipeline(
'OpenGVLab/InternVL2-8B',
backend_config=PytorchEngineConfig(
max_prefill_token_num=4096))
- 设置模型下载参数(download_dir、revision)
当 model_path 不是本地路径时,LMDeploy 会从 huggingface hub 或者 modelscope hub上下载模型,默认下载最新版本,默认存储在 ~/.cache 下。用户可以通过 revision 指定模型版本,通过download_dir 指定模型存放路径
TurbomindEngine 专用参数:
- 设置Dynamic NTK外推参数(rope_scaling_factor)
from lmdeploy import pipeline, GenerationConfig, TurbomindEngineConfig
backend_config = TurbomindEngineConfig(
rope_scaling_factor=2.5,
session_len=1000000,
max_batch_size=1,
cache_max_entry_count=0.9,
tp=2)
pipe = pipeline('internlm/internlm2_5-7b-chat-1m', backend_config=backend_config)
prompt = 'Use a long prompt to replace this sentence'
gen_config = GenerationConfig(top_p=0.8,
top_k=40,
temperature=0.8,
max_new_tokens=1024)
response = pipe(prompt, gen_config=gen_config)
print(response)
- 设置在线 KV Cache量化精度(quant_policy)
quant_policy 表示 LLM 模型 KV cache 量化策略的参数,4表示 4bit 量化,8表示 8bit 量化。8bit KV cache 几乎不掉点,可认为量化精度无损。
from lmdeploy import pipeline, TurbomindEngineConfig
pipe = pipeline('OpenGVLab/InternVL2-8B',
backend_config=TurbomindEngineConfig(
quant_policy=8))
- 设置模型格式(model_format)
取值范围{None,hf,llama,awq,gptq}。None 根据模型文件结构自动判断,hf 表示 huggingface上类llama结构的模型,llama 表示 meta_llama(pytorch权重格式),awq 表示 awq 量化模型,gptq 表示 gptq 量化模型(0.6.0支持)。
from lmdeploy import pipeline, TurbomindEngineConfig
pipe = pipeline(
'OpenGVLab/InternVL2-8B-AWQ',
backend_config=TurbomindEngineConfig(
model_format='awq'))
from lmdeploy import pipeline, TurbomindEngineConfig
pipe = pipeline(
'OpenGVLab/InternVL2-8B-AWQ',
backend_config=TurbomindEngineConfig(
model_format=None))
- KV block 的大小(cache_block_seq_len)
一个 KV cache block 能够容纳的 token 的数量。默认是 64。如果 GPU compute_capability >= 8.0,应该是32的倍数,否则应该是64的倍数
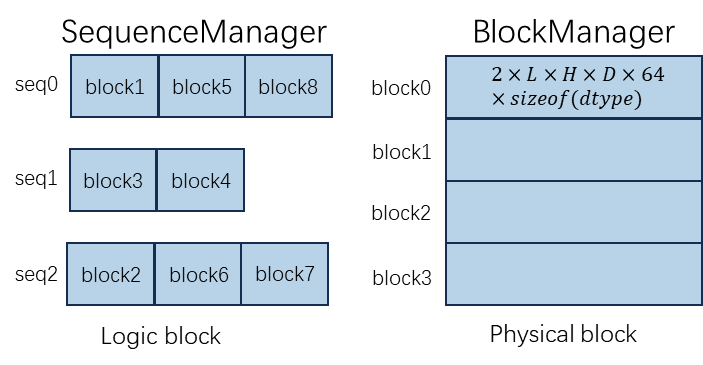
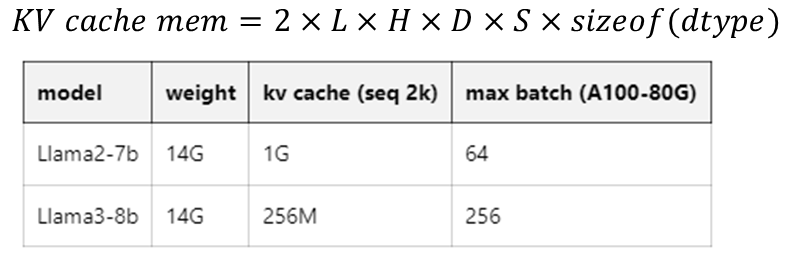
- num_tokens_per_iter
控制一次forward pass 处理的token数量。这包括预填充(prefill)和解码(decoding)。例如,当有8个解码序列和2个预填充序列时,首先为8个解码token分配所需要的资源,然后为num_tokens_per_iter - 8个预填充token分配资源。
它的默认值为 max_prefill_token_num
为了减少long prompt 序列的影响,num_tokens_per_iter的最优值与模型大小、GPU型号和工作负载有关。对于Llama3-8B、A100 80G和128个并发使用情况,该值在128到256之间。如果你使用的是4090显卡,可以从64-128开始。基本上,这个值越小,预填充的影响就越小(但它要大于max_batch_size)。
- max_prefill_iters
控制单个序列预填充的最大迭代次数。
在max_prefill_iters被设定后,num_tokens_per_iter可能会被重新计算。例如,当一个请求有2000个 token 时,如果max_prefill_iters=1,意味着预填充在1次迭代中完成,不管num_tokens_per_iter被设置为多少。所以,为了让num_tokens_per_iter充分发挥其效果,max_prefill_iters应该设置为一个比较大的值。
它的默认值为 (session_len + max_prefill_token_num - 1) // max_prefill_token_num
当找到一个合适的num_tokens_per_iter后,max_prefill_iters用于平衡解码的平滑度和首token延迟。首先将其设置为一个大值(你会观察到首令牌延迟的增加),然后逐渐减小,直到达到可接受的首令牌延迟。
2.2.1.3 对话模板配置
@dataclass
class ChatTemplateConfig:
model_name: str
system: Optional[str] = None
meta_instruction: Optional[str] = None
eosys: Optional[str] = None
user: Optional[str] = None
eoh: Optional[str] = None
assistant: Optional[str] = None
eoa: Optional[str] = None
separator: Optional[str] = None
capability: Optional[Literal['completion', 'infilling', 'chat',
'python']] = None
stop_words: Optional[List[str]] = None
model_name: 对话模板名称
system、meta_instruction、eosys 分别表示 system 角色的名称,system角色的提示词,system角色的提示词的结束符。
以 InternLM2 模型为例,它的对话模板的这3个属性如下:
# InternLM2
system = "<|im_start|>system"
meta_instruction = """You are an AI assistant whose name is InternLM (书生·浦语).
- InternLM (书生·浦语) is a conversational language model that is developed by Shanghai AI Laboratory (上海人工智能实验室). It is designed to be helpful, honest, and harmless.
- InternLM (书生·浦语) can understand and communicate fluently in the language chosen by the user such as English and 中文.
"""
eosys = "<|im_end|>\n"
- user、eoh 分别表示 user 这个角色的名称,user角色的提示词的结束符
- assistant、eoa 分别表示 AI assistant 这个角色的名称,以及这个角色回复内容的结束符
- seperator:两轮对话之间的分隔符
- capability:模型的能力。“completion” 表示文本补全,“chat” 表示对话,“infilling” 表示代码填空(codellama专用)、"python"表示python代码能力(codellama专用)
- stop_words:结束符,用来停止 AI assistant 应答的。当前,LMDeploy 只支持每个 stop_word 只能是 1 个 token_id 的情况
对话模板的作用是用来拼接一个对话序列的。
我们假设一个对话序列为 U1A1U2A2…Un,其中Ui表示User在第i轮对话时输入的提示词(prompt),Ai表示模型或者说AI Assistant在第i轮对话中生成的答案。
在 LMDeploy 中,对话序列的拼接方式有 2 种,分别对应两种推理模式:交互式推理(有状态推理)、非交互式推理(无状态推理)。
这两种推理方式的区别在于,第 i轮对话中,用户侧的输入是什么。交互式推理的输入是 Ui,非交互式推理的输入是 U1A1U2A2…Ui。换言之,交互式推理模式下,用户不需要输入历史对话记录,因为历史对话的信息已经被推理引擎缓存了(包括token、KV、游标等),而非交互式推理模式则需要输入历史对话记录。
LMDeploy 拼接对话序列的两种方式在 BaseChatTemplate 中实现。get_prompt 用户交互式推理模式,messages2prompt 用于非交互式推理模式
class BaseChatTemplate:
def get_prompt(self, prompt, sequence_start=True):
"""Return decorated prompt in interactive inference mode
"""
if sequence_start: # decorate $$U_0$$
return f'{self.system}{self.meta_instruction}{self.eosys}' \
f'{self.user}{prompt}{self.eoh}' \
f'{self.assistant}'
else: # decorate $$U_i$$
return f'{self.user}{prompt}{self.eoh}' \
f'{self.assistant}'
def messages2prompt(self, messages, sequence_start=True, **kwargs):
"""Return decorated prompt in non-interactive inference mode.
Args:
messages (str|List): user's input prompt which is supposed
to be in OpenAI format
"""
if isinstance(messages, str):
# fallback to `get_prompt` when `messages` isn't a list
return self.get_prompt(messages, sequence_start)
# "box" indicates "begin of x (role)"
box_map = dict(user=self.user,
assistant=self.assistant,
system=self.system)
# "eox" indicates "end of x (role)"
eox_map = dict(user=self.eoh,
assistant=self.eoa + self.separator,
system=self.eosys)
for message in messages:
role = message['role']
content = message['content']
ret += f'{box_map[role]}{content}{eox_map[role]}'
在上述代码中,为了突出重点,简化了部分逻辑。完成的代码请参考:https://github.com/InternLM/lmdeploy/blob/main/lmdeploy/model.py
对话模板的使用方式有以下几种:
-
在不指定对话模板配置时,LMDeploy 根据模型的路径名,匹配内置对话模板名
-
指定内置对话模板
from lmdeploy import pipeline, ChatTemplateConfig
pipe = pipeline('/the/path/of/your/finetuned/internvl2/8b/model',
chat_template_config=ChatTemplateConfig(
model_name='internvl-internlm2'
)
lmdeploy list 可以显示内置对话模板。内置对话模板与支持的模型之间的映射关系请参考附录-内置对话模板
- 改变内置对话模板的属性
from lmdeploy import pipeline, ChatTemplateConfig
pipe = pipeline('/the/path/of/your/finetuned/internvl2/8b/model',
chat_template_config=ChatTemplateConfig(
model_name='internvl2-internlm2',
meta_instruction='You are a helpful assistant'
)
LMDeploy 会把非None的属性信息更新到指定的对话模板里
- 自定义对话模板
**方式一:**对话模板的属性定义和拼接方式完全符合BaseChatTemplate的定义
只需设置 ChatTemplateConfig 各字段即可。LMDeploy会创建BaseChatTemplate实例
**方式二:**对话模板的属性或者拼接方式不符合 BaseChatTemplate的定义
@register_module(name="awesome")
class MyChatTemplate:
def __init__(*args, **kwargs):
pass
def get_prompt(self, prompt, sequence_start=True):
if sequence_start:
# TODO: return the decorated prompt when it is the first request of a sequence
pass
else:
# TODO: return the decorated prompt when it is NOT the first request of a sequence
pass
def message2prompt(self, messages, sequence_start=True, **kwargs):
if isinstance(messages, str):
return self.get_prompt(messages, sequence_start)
# TODO: return the prompt after applying the chat template
pipe = pipeline("/the/path/of/your/awesome/model",
chat_template_config=ChatTemplateConfig(
model_name="awesome"))
2.2.1.4 视觉模型推理配置
@dataclass
class VisionConfig:
max_batch_size: int = 1
thread_safe: bool = False
max_batch_size 表示图像批量处理的大小。值越大,OOM 的风险越高,因为 VLM 模型中的 LLM 部分会提前预分配大量的内存。
2.2.2 使用 pipeline
2.2.2.1 API
def __call__(self,
prompts: Union[VLPromptType, List[Dict], List[VLPromptType],
List[List[Dict]]],
gen_config: Optional[GenerationConfig] = None,
**kwargs):
prompts 用户输入的 prompt 和 image。它可以是以下几种形式:
- str:纯文本
- list[str]:纯文本序列
- tuple(str, PIL.Image):文本 + 图像
- tuple(str, list[PIL.Image]):文本 + 图像序列
- list[tuple(str, PIL.Image)]:(文本+图像)序列
- GPT4V的格式
[{
"role":"user",
"content": [{
"type": "text",
"text": "the input text prompt",
},
{
"type": "image_url",
"image_url": {
"url": "data:image/jpeg;base64,{image_base64_data}"
}
},
{
"type": "image_data",
"image_data": {
"data": PIL.Image.Image
}
},
...
{...}]
}]
LMDeploy 会把前 5 种格式处理为 GPT4V 的格式
gen_config 生成token的采样参数
@dataclass
class GenerationConfig:
n: int = 1
max_new_tokens: int = 512
top_p: float = 1.0
top_k: int = 1
temperature: float = 0.8
repetition_penalty: float = 1.0
ignore_eos: bool = False
random_seed: int = None
stop_words: List[str] = None
bad_words: List[str] = None
min_new_tokens: int = None
skip_special_tokens: bool = True
logprobs: int = None
- n:输入请求要求生成的序列的数量,目前只支持 1
- max_new_tokens:输入请求要求的最多生成的token的个数
- top_p:采样时,考虑累积概率超过top_p的最小可能token集合中进行采样
- top_k:采样时,考虑从概率最高的top_k个token中进行采样。top_k=1 表示贪心搜索
- temperature:采样温度。temperature=0.f 表示贪心搜索
- repetition_penalty:防止模型生成重复单词或短语的惩罚。大于1的值会抑制重复。
- ignore_eos:是否忽略 eos_token_id
- random_seed:采样token时使用的种子
- stop_words:token生成的停止符。目前要求每个 stop_word 被 tokenizer 时,只能有一个token_id
- bad_words:永远不会被生成的单词。目前要求每个 bad_word 被 tokenizer 时,只能有一个token_id
- min_new_tokens:输入请求要求生成的最少token数量
- skip_special_tokens:是否在解码中忽略特殊 token。默认为True
- logprobs:每个输出 token 返回的对数概率数量
- 关于生成时采样方式的介绍,推荐阅读 https://huggingface.co/blog/how-to-generate
2.2.2.2 更多示例
- 多图输入
对于多图的场景,在推理时,只要把它们放在一个列表中即可。不过,多图意味着输入 token 数更多,所以通常需要增大推理的上下文长度
from lmdeploy import pipeline, TurbomindEngineConfig
from lmdeploy.vl import load_image
pipe = pipeline('OpenGVLab/InternVL2-8B',
backend_config=TurbomindEngineConfig(session_len=10000))
image_urls=[
'https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/human-pose.jpg',
'https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/det.jpg'
]
images = [load_image(img_url) for img_url in image_urls]
response = pipe(('describe these images', images))
print(response)
- 批量图文输入
from lmdeploy import pipeline, TurbomindEngineConfig
from lmdeploy.vl import load_image
pipe = pipeline('OpenGVLab/InternVL2-8B',
backend_config=TurbomindEngineConfig(session_len=8192))
image_urls=[
"https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/human-pose.jpg",
"https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/det.jpg"
]
prompts = [('describe this image', load_image(img_url)) for img_url in image_urls]
response = pipe(prompts)
print(response)
- 多轮对话
pipeline 进行多轮对话有两种方式,一种是按照 GPT4V 的格式来构造 messages,另外一种是使用 pipeline.chat 接口。
from lmdeploy import pipeline, TurbomindEngineConfig, GenerationConfig
from lmdeploy.vl import load_image
pipe = pipeline('OpenGVLab/InternVL2-8B',
backend_config=TurbomindEngineConfig(session_len=8192))
image = load_image('https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/human-pose.jpg')
gen_config = GenerationConfig(top_k=40, top_p=0.8, temperature=0.6)
sess = pipe.chat(('describe this image', image), gen_config=gen_config)
print(sess.response.text)
sess = pipe.chat('What is the woman doing?', session=sess, gen_config=gen_config)
print(sess.response.text)
- 自定义图像 token 的位置
默认情况下,LMDeploy 会根据算法 repo 提供的对话模版将表示图片的特殊 token 插入到 user prompt 中,但在一些模型中,图片 token 的位置并没有限制,如 deepseek-vl,或者用户需要自定义图片 token 插入的位置。这种情况下,用户需要手动将表示图片的 token 插入到 prompt 中。LMDeploy 使用 <IMAGE_TOKEN> 作为表示图片的特殊 token。
from lmdeploy import pipeline
from lmdeploy.vl import load_image
from lmdeploy.vl.constants import IMAGE_TOKEN
pipe = pipeline('deepseek-ai/deepseek-vl-1.3b-chat')
image = load_image('https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/tests/data/tiger.jpeg')
response = pipe((f'describe this image{IMAGE_TOKEN}', image))
print(response)
2.3 在线服务
2.3.1 启动服务
2.3.1.1 方式一:使用 lmdeploy cli 工具
lmdeploy serve api_server OpenGVLab/InternVL2-8B
此命令将在本地主机上的端口 23333 启动一个与 OpenAI 接口兼容的模型推理服务。你可以使用 --server-port 选项指定不同的服务器端口。更多参数的说明请参考章节api_server参数
2.3.1.2 方式二:使用 docker
docker run --runtime nvidia --gpus all \
-v ~/.cache/huggingface:/root/.cache/huggingface \
--env "HUGGING_FACE_HUB_TOKEN=<secret>" \
-p 23333:23333 \
--ipc=host \
openmmlab/lmdeploy:latest \
lmdeploy serve api_server OpenGVLab/InternVL2-8B
2.3.1.3 api_server 参数
root@lmdeploy-on-121:~/lmdeploy# lmdeploy serve api_server -h
usage: lmdeploy serve api_server [-h] [--server-name SERVER_NAME] [--server-port SERVER_PORT]
[--allow-origins ALLOW_ORIGINS [ALLOW_ORIGINS ...]] [--allow-credentials]
[--allow-methods ALLOW_METHODS [ALLOW_METHODS ...]]
[--allow-headers ALLOW_HEADERS [ALLOW_HEADERS ...]] [--qos-config-path QOS_CONFIG_PATH]
[--backend {pytorch,turbomind}]
[--log-level {CRITICAL,FATAL,ERROR,WARN,WARNING,INFO,DEBUG,NOTSET}]
[--api-keys [API_KEYS ...]] [--ssl] [--model-name MODEL_NAME]
[--chat-template CHAT_TEMPLATE] [--revision REVISION] [--download-dir DOWNLOAD_DIR]
[--adapters [ADAPTERS ...]] [--tp TP] [--session-len SESSION_LEN]
[--max-batch-size MAX_BATCH_SIZE] [--cache-max-entry-count CACHE_MAX_ENTRY_COUNT]
[--cache-block-seq-len CACHE_BLOCK_SEQ_LEN] [--enable-prefix-caching]
[--model-format {hf,llama,awq,gptq}] [--quant-policy {0,4,8}]
[--rope-scaling-factor ROPE_SCALING_FACTOR] [--num-tokens-per-iter NUM_TOKENS_PER_ITER]
[--max-prefill-iters MAX_PREFILL_ITERS] [--vision-max-batch-size VISION_MAX_BATCH_SIZE]
model_path
- model_path
- –server-name SERVER_NAME: 服务的主机IP地址。默认: 0.0.0.0。
- –server-port SERVER_PORT: 服务端口。默认: 23333。
- –allow-origins ALLOW_ORIGINS: 允许CORS的来源列表。默认: [‘*’]。
- –allow-credentials: 是否允许CORS的凭证。默认: False。
- –allow-methods ALLOW_METHODS: 允许的HTTP方法列表。默认: [‘*’]。
- –allow-headers ALLOW_HEADERS: 允许的HTTP头部列表。默认: [‘*’]。
- –backend {pytorch,turbomind}: 设置推理后端。默认: turbomind。
- –log-level {LEVELS}: 设置日志级别。默认: ERROR。
- –api-keys [API_KEYS]: 可选的API密钥列表。
- –ssl: 启用SSL。需要操作系统环境变量’SSL_KEYFILE’和’SSL_CERTFILE’。
- –model-name MODEL_NAME: 模型的服务名称。可以通过RESTful API /v1/models访问。如果未指定,将采用model_path。
- –chat-template CHAT_TEMPLATE: 当它为字符串时,表示内置的对话模板名称。当它为JSON文件路径时,表示自定义对话模板。
- –revision REVISION: 使用的特定模型版本。可以是分支名、标签名或提交ID。
- –download-dir DOWNLOAD_DIR: 下载和加载权重的目录,默认为huggingface的默认缓存目录。
和 TurboMind 引擎相关的参数
- –tp TP: 在张量并行中使用的GPU数量
- –session-len SESSION_LEN: 序列的最大会话长度
- –max-batch-size MAX_BATCH_SIZE: 最大批量大小。默认:128
- –cache-max-entry-count CACHE_MAX_ENTRY_COUNT: KV 缓存占用的空闲GPU内存的百分比,不包括权重。默认:0.8
- –cache-block-seq-len CACHE_BLOCK_SEQ_LEN: KV 缓存块容纳的token数量。对于Turbomind引擎,如果GPU compute_capability >= 8.0,应该是32的倍数,否则应该是64的倍数。默认:64。
- –enable-prefix-caching: 是否启用前缀匹配KV缓存。默认:False。
- –model-format {hf,llama,awq,gptq}: 输入模型的格式。hf 表示 hf_llama,llama 表示 meta_llama,awq 表示 awq 量化模型,gptq 表示 gptq 量化模型
- –quant-policy {0,4,8}: 是否量化kv。0: 不量化;4: 4位kv;8: 8位kv。默认:0
- –rope-scaling-factor ROPE_SCALING_FACTOR: Rope缩放因子。默认:0.0
- –num-tokens-per-iter NUM_TOKENS_PER_ITER: 前向传递中处理的令牌数量。默认:0
- –max-prefill-iters MAX_PREFILL_ITERS: prefill阶段的最大前向传递数量。默认:1
和 PyTorch 引擎相关的参数
- –adapters [ADAPTERS …]: 用于设置 lora 模型的路径。可以输入多个lora的键值对格式xxx=yyy。如果只有一个适配器,可以只输入适配器的路径。默认:无。类型:字符串。
- –tp TP: 在张量并行中使用的GPU数量
- –session-len SESSION_LEN: 序列的最大会话长度
- –max-batch-size MAX_BATCH_SIZE: 最大批量大小。默认:128
- –cache-max-entry-count CACHE_MAX_ENTRY_COUNT: KV 缓存占用的空闲GPU内存的百分比,不包括权重。默认:0.8
- –cache-block-seq-len CACHE_BLOCK_SEQ_LEN: KV 缓存块容纳的token数量。如果指定了Lora适配器,此参数将被忽略。默认:64
- –enable-prefix-caching: 是否启用前缀匹配KV缓存。默认:False。
视觉模型参数:
- –vision-max-batch-size VISION_MAX_BATCH_SIZE: 视觉模型批量大小。默认:1。
2.3.2 访问服务
推荐使用 openai client package 接口访问服务
- 图像 url
from openai import OpenAI
client = OpenAI(
api_key='YOUR_API_KEY', # dummy key to pass openai checking key
base_url='http://0.0.0.0:23333/v1')
model_name = client.models.list().data[0].id
response = client.chat.completions.create(
model=model_name,
messages=[{
'role': 'user',
'content': [{
'type': 'text',
'text': 'Describe the image please',
}, {
'type': 'image_url',
'image_url': {
'url':
'https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/tests/data/tiger.jpeg',
},
}],
}],
temperature=0.8,
top_p=0.8)
print(response)
如模型支持多图,可以在messages中 user 的content列表中追加图像
- 图像base64编码
from openai import OpenAI
client = OpenAI(
api_key='YOUR_API_KEY', # dummy key to pass openai checking key
base_url='http://0.0.0.0:23333/v1')
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
# Path to your image
image_path = "path_to_your_image.jpg"
# Getting the base64 string
base64_image = encode_image(image_path)
model_name = client.models.list().data[0].id
response = client.chat.completions.create(
model=model_name,
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "What’s in this image?"},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}",
},
},
],
}
],
max_tokens=300,
)
- 加入额外信息
from openai import OpenAI
client = OpenAI(
api_key='YOUR_API_KEY', # dummy key to pass openai checking key
base_url='http://0.0.0.0:23333/v1')
model_name = client.models.list().data[0].id
response = client.chat.completions.create(
model=model_name,
messages=[{
'role': 'user',
'content': [{
'type': 'text',
'text': 'Describe the image please',
}, {
'type': 'image_url',
'image_url': {
'url':
'https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/tests/data/tiger.jpeg',
},
}],
}],
temperature=0.8,
top_p=0.8,
extra_body={"repetition_penalty": 1.02}
)
print(response)
2.4 模型量化
2.4.1 权重量化
- 4bit 权重量化。量化算法 AWQ,只对 VLM 中的语言模型部分做量化,视觉部分不做量化
- 支持的显卡型号:
- V100(0.6.0 支持,尚未发版)
- Turing(sm75): 20 系列,T4
- Ampere(sm80): A100
- Ampere(sm86): 30 系列,A10, A16, A30 等
- Ada Lovelace(sm89): 40 系列
- Hopper(sm90): H100, H800(尚未深度优化)
lmdeploy lite auto_awq OpenGVLab/InternVL2-8B
2.4.2 KV Cache 量化
设置 TurbomindEngineConfig 中的参数 quant_policy。详细介绍请参考前文推理引擎配置章节中关于quant_policy的说明
03
推理性能
关于 VLM 推理性能评测方法暂无统一标准,LLM有
评测 LLM pipeline 的方式如下,测试指标 RPS(Request Per Second)
python benchmark/profile_pipeline_api.py \
ShareGPT_V3_unfiltered_cleaned_split.json \
meta-llama/Meta-Llama-3-8B-Instruct \
--num-prompts 5000
在A100-SMX4-80G显卡上,测试结果如下:
--------------------------------------------------
concurrency: 256
elapsed_time: 208.390s
first token latency(s)(min, max, ave): 0.068, 3.880, 0.378
per-token latency(s) percentile(50, 75, 95, 99): [0, 0.09, 0.153, 0.207]
number of prompt tokens: 1136185
number of completion tokens: 1008966
token throughput (completion token): 4841.723 token/s
token throughput (prompt + completion token): 10293.932 token/s
RPS (request per second): 23.993 req/s
RPM (request per minute): 1439.609 req/min
--------------------------------------------------
测试 LLM serving 性能,推荐使用 vLLM 的测试脚本 https://github.com/vllm-project/vllm/blob/main/benchmarks/benchmark_serving.py。该脚本的测试指标是:TTFT、TPOT
# 首先启动服务
lmdeploy api_server meta_llama/Meta-Llama-3-8B-Instruct --max-batch-size 256
# 打开新的终端,使用 vLLM 的测试脚本 benchmark_serving.py 测试
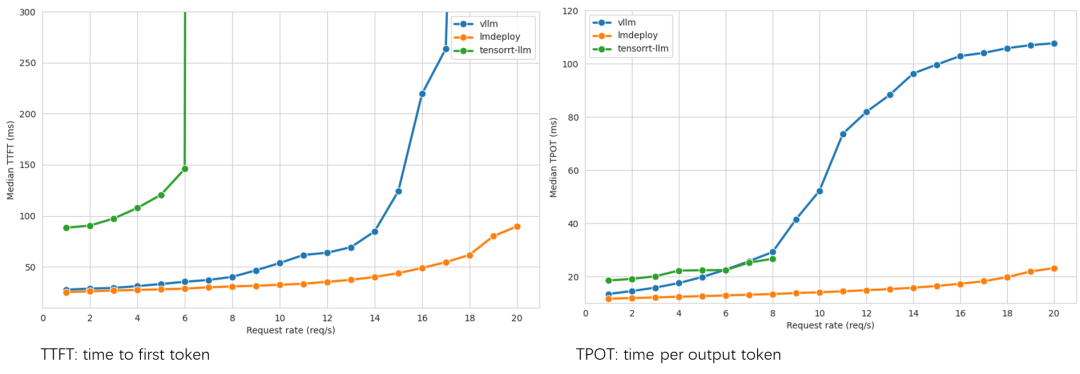
| vllm 0.4.2lmdeploy 0.4.1tensorrt-llm v0.9.0 |
|---|
04
VLM推理实现方式
初始化 pipeline

prompt 预处理

在离线推理章节的示例 1,模型为 OpenGVLab/InternVL2-8B,pipe推理的请求为(‘describe this image’, image)
经过"转GPT4V请求格式"后,请求变成:
{
"role": "user",
"content": [
{
"type": "text",
"text": "describe this image"
},
{
"type": "image_data",
"image_data": {
"data": image
}
}
]
}
经过 “加image标记符”,请求变成:
{'role': 'user', 'content': '<img><IMAGE_TOKEN></img>\ndescribe this image'}
| InternVL2-8B 是把 image放到text前的 |
|---|
经过 “装饰对话模板 message2prompt”,请求变成:
<|im_start|>system\n你是由上海人工智能实验室联合商汤科技开发的书生多模态大模型,英文名叫InternVL, 是一个有用无害的人工智能助手。<|im_end|>\n<|im_start|>user\n<img><IMAGE_TOKEN></img>\ndescribe this image<|im_end|>\n<|im_start|>assistant\n
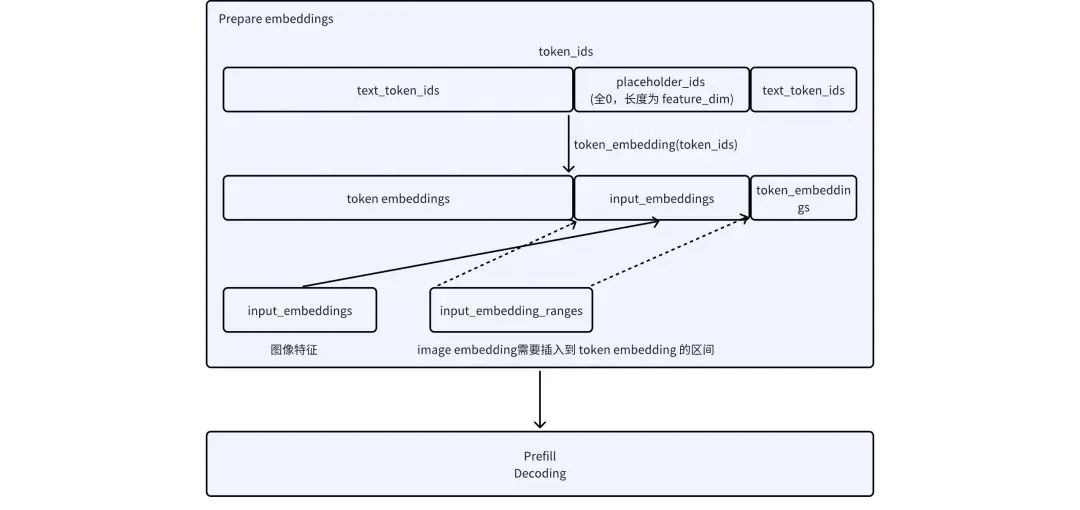
图像编码
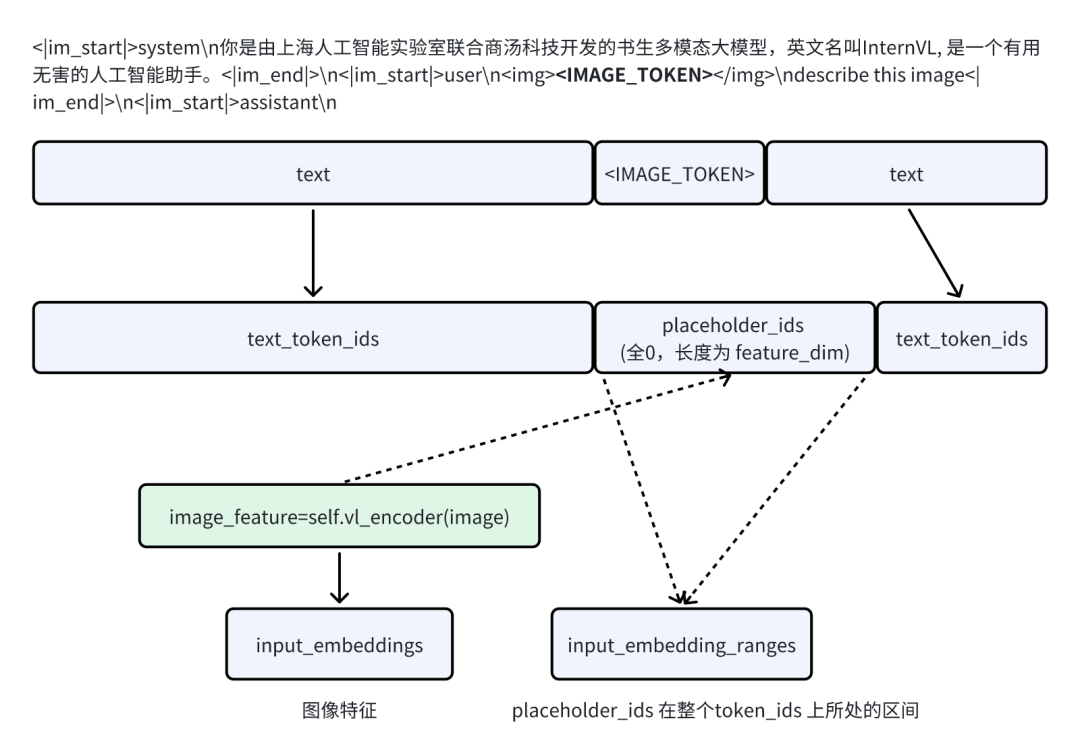
self.vl_encoder 复用上游库的图像预处理和vision模型推理
推理
- TurboMind 推理
- PyTorch 推理
TODO
05
未来规划
06
附录
6.1 内置对话模板
| 模型 | 模型类型 | 模型结构 | 内置对话模板名称 | 说明 |
|---|---|---|---|---|
| InternLM-XComposer2 | MLLM | InternLMXComposer2ForCausalLM | internlm-xcomposer2 | |
| InternLM-XComposer2.5 | MLLM | InternLMXComposer2ForCausalLM | internlm-xcomposer2d5 | |
| Qwen-VL | MLLM | QWenLMHeadModel | qwen | |
| DeepSeek-VL | MLLM | MultiModalityCausalLM | deepseek-vl | |
| Phi-3-vision | MLLM | Phi3VForCausalLM | phi-3 | |
| CogVLM-Chat | MLLM | CogVLMForCausalLM | cogvlm | |
| CogVLM2-Chat | MLLM | CogVLMForCausalLM | cogvlm2 | |
| Yi-VL | MLLM | LlavaLlamaForCausalLM | yi-vl | |
| LLaVA-v1.5 | MLLM | LlavaLlamaForCausalLM | llava-vl | |
| LLaVA-v1.6-vicuna | MLLM | LlavaLlamaForCausalLM | llava-v1 | |
| llava-v1.6-34b | MLLM | LlavaLlamaForCausalLM | llava-chatml | |
| llava-v1.6-mistral-7b | MLLM | LlavaMistralForCausalLM | mistral | |
| InternVL-Chat-V1-5 | MLLM | InternLM2ForCausalLM | internvl-internlm2 | InternVL系列需要看llm_config中的architectures |
| Mini-InternVL-Chat-2B-V1-5 | MLLM | InternLM2ForCausalLM | internvl-internlm2 | |
| Mini-InternVL-Chat-4B-V1-5 | MLLM | Phi3ForCausalLM | internvl-phi3 | |
| InternVL2 (2B、8B、26B) | MLLM | InternLM2ForCausalLM | internvl2-internlm2 | |
| InternVL2 (4B) | MLLM | Phi3ForCausalLM | internvl2-phi3 | |
| InternVL2 (40B) | MLLM | LlamaForCausalLM | internvl2-internlm2 | |
| InternVL2-Llama3-76B | MLLM | LlamaForCausalLM | internvl2-internlm2 | |
| MiniCPM-Llama3-V-2_5 | MLLM | MiniCPMV | llama3 | llm的种类在代码里面才能看出来 |
| MiniGeminiLlama | MLLM | MiniGeminiLlamaForCausalLM | mini-gemini-vicuna | |
| GLM-4V | MLLM | ChatGLMModel | glm4 |


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









