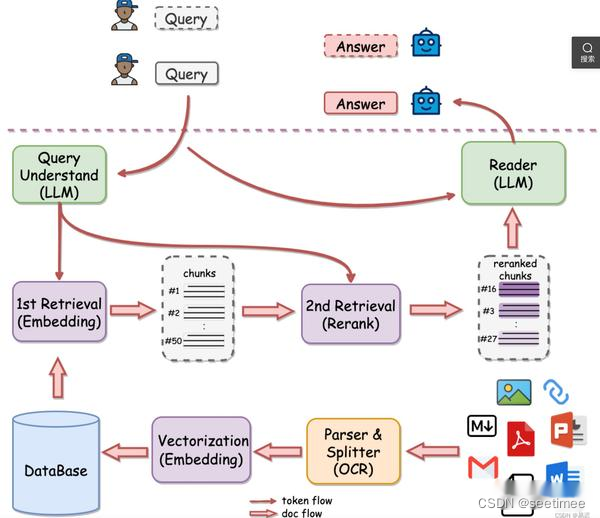
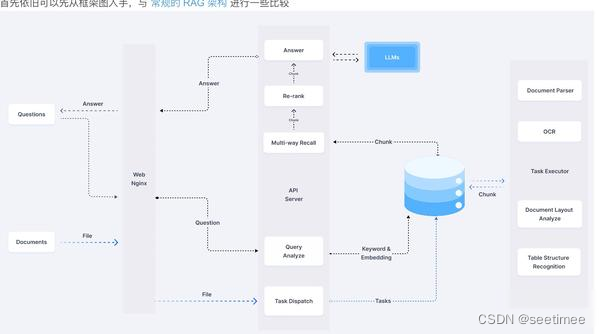
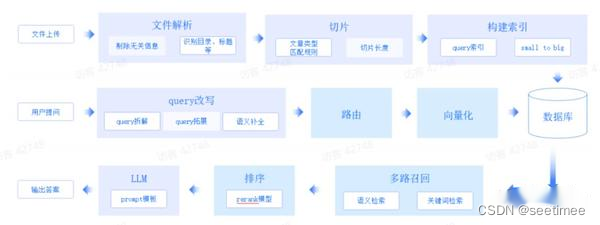
各家的技术方案 有道的QAnything 亮点在:rerank RAGFLow 亮点在:数据处理+index 智谱AI 亮点在文档解析、切片、query改写及recall模型的微调 FastGPT 优点:灵活性更高 下面分别按照模块比较各框架的却别 功能模块 QAnything RAGFLow FastGPT 智谱AI 知识处理模块 pdf文件解析是抑郁PyMUPDF实现的,目前效率最高的,解析文档的文字采用的是PyMuPDF的get









 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


 被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言






