







前言
图像风格迁移是近几年研究的热点问题,近期看了几篇相关文章和大家分享下。欢迎大家一起讨论~
图像风格迁移
非在线迭代式图像风格迁移
在Gatys的论文1中提出了对该问题的一个简单定义,即对图像的内容和风格进行分离和再结合。如下图,左图代表了待融合图像的风格类型,中间的图像代表了内容,最右边的是融合的结果。

那怎么去刻画图像的内容及风格呢?对于风格的提取,在Gatys的另一篇文章2中提出把待提取风格的图像输入进预训练好的VGG网络中,同时输入随机化的白点噪声图像,使得两张图像的top n层输出的Gram矩阵( 1.1 1.1 1.1)的平方误差最小( 1.3 1.3 1.3),l指的是第l层,a指的是待提取风格的图像,x指的是生成的图像。最终训练的时候通过最优化( 1.3 1.3 1.3),从而使得白点噪声图像逐渐变成了待提取风格图像中的风格图像,那为什么Gram矩阵就能够刻画图像的风格呢?首先得说明一点,这个并不是唯一的方案,也有其他的刻画方法(例如Julesz ensemble),其次Gram矩阵其实就是各个feature map间的向量内积,描述的是各层间feature map的相似度,我们可以认为当各层的feature map间的相似度相近的两张图片,他的风格是一致的。
(1.1) G i j l = ∑ k F i k l F j k l G^l_{ij} = \sum_k{F^l_{ik}F^l_{jk}} \tag{1.1} Gijl=k∑FiklFjkl(1.1)
(1.2) E l = 1 4 N l 2 M l 2 ∑ i , j ( G i j l − G i j l ^ ) 2 E_{l} = \frac{1}{4N^2_lM^2_l}\sum_{i,j}{(G^l_{ij} - \hat{G^l_{ij}}})^2 \tag{1.2} El=4Nl2Ml21i,j∑(Gijl−Gijl^)2(1.2)
(1.3) L s t y l e ( a , x ) = ∑ l = 0 L w l E l L_{style}(a, x) = \sum^L_{l = 0}w_lE_l \tag{1.3} Lstyle(a,x)=l=0∑LwlEl(1.3)
对于内容的提取,他参考了3中的方法,也是类似于风格的提取,只不过损失函数不再是各层的Gram loss加和了,而是中间某一层的两个图像的feature map loss之和。其目的在于使得随机化的噪声图像能够在某一层的各个feature map等于待提取图像的各个feature map,从而达到提取内容的效果,内容的损失函数为( 1.4 1.4 1.4)。最终总的损失函数为( 1.5 1.5 1.5)。
(1.4) L c o n t e n t ( p , x , l ) = 1 2 ∑ i , j ( F i j l − P i j l ) 2 L_{content}(p, x, l) = \frac{1}{2}\sum_{i, j}(F^l_{ij} - P^l_{ij})^2 \tag{1.4} Lcontent(p,x,l)=21i,j∑(Fijl−Pijl)2(1.4)
L t o t a l ( p , a , x ) = α L c o n t e n t ( p , x ) + β L s t y l e ( a , x ) L_{total}(p, a ,x) = \alpha L_{content}(p, x) + \beta L_{style}(a, x) Ltotal(p,a,x)=αLcontent(p,x)+βLstyle(a,x)
这篇文章的问题就在于不能在线的生成融合图像,因为速度太慢了,输入一张内容图像一张风格图像,经过多轮迭代才能出结果。就有了下面的升级版。
特定风格的快速图像风格迁移
在李飞飞4的这篇文章中,他们加入了一个生成器,对于特定的一个图像风格,他们用一批图像数据放入到生成器中,通过优化生成器,使得最终的( 1.5 1.5 1.5)最小,在应用阶段,只需要输入内容图像,即可获得特定风格的融合图像。总体的结构如下图:
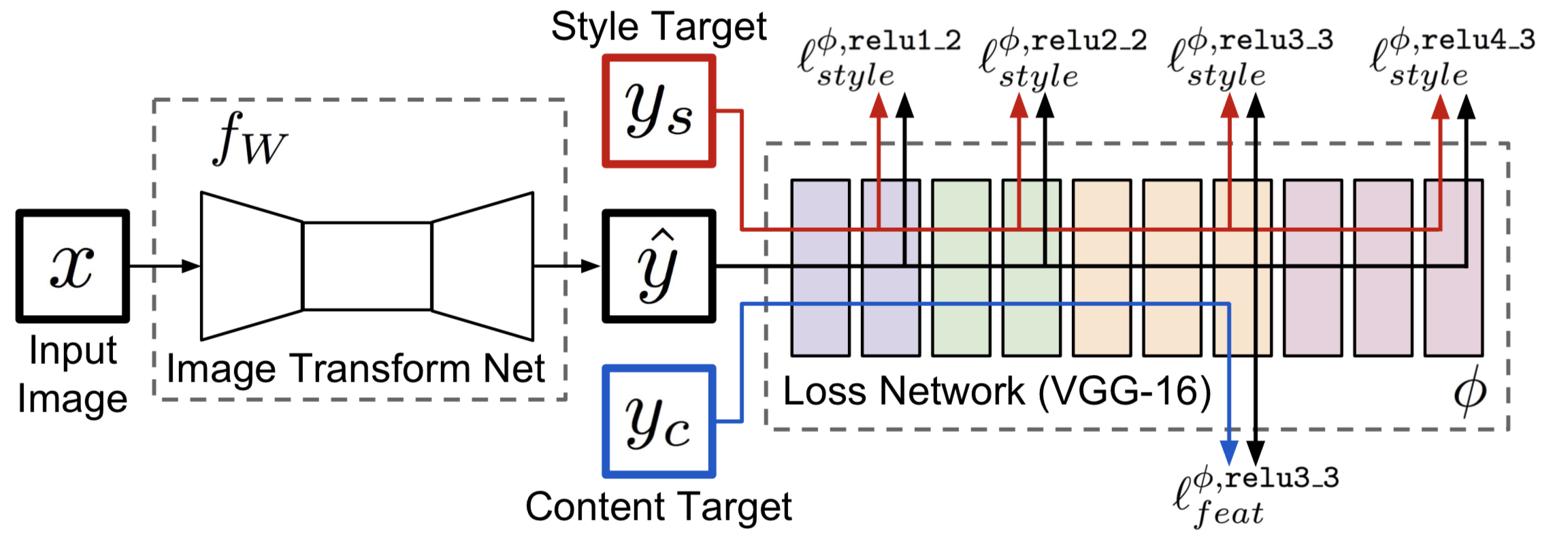
任意风格的快速图像风格迁移
在上面的那一篇中,缺点在于只能固定住图像的风格来训练一个特定的生成器。在这篇论文中5对上述进行了改进,如果我们在训练阶段只对生成器输入内容图像,而不输入风格图像,那肯定是不能对任意风格进行转换,在这篇文章中作者把风格图像也输入进了生成器中,其实这样牺牲的是融合图像的多样性以及质量,换来了速度和方便,总体的结构如下图:
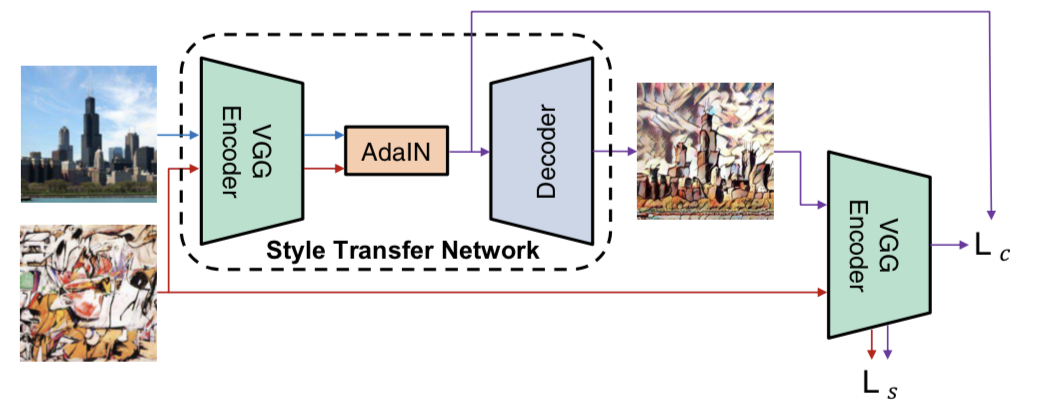
这篇文章还有另外一个很大的贡献,是解释清楚了instance normalization(IN)6为什么能提升图像迁移的效果以及训练速度,原因在于IN实际上是对训练集做了图像的风格标准化,他通过另外一种方法对待训练的图像进行了风格标准化,从而提升了最终的训练效果,来说明IN之所以好不是因为对训练集做了对比度的规范化,从而减轻了训练的"负担",而是由于IN带来的风格标准化提升了训练效果。另外这篇文章用了自己定义的AdaIN来进行规范化。
参考文献
Understanding Deep Image Representations by Inverting Them ↩︎
Perceptual Losses for Real-Time Style Transfer and Super-Resolution ↩︎
Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization ↩︎
Improved Texture Networks: Maximizing Quality and Diversity in Feed-forward Stylization and Texture Synthesis ↩︎














 998
998











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









