






文本分析
停用词
在信息检索中,为节省存储空间和提高搜索效率,在处理自然语言数据(或文本)之前或之后会自动过滤掉某些字或词,这些字或词即被称为Stop Words(停用词)。
网上有很多现成的停用词表
中文停用词表
TF-IDF
TF-IDF 是一种统计方法,用以评估一个词对于一个语料库中的其中一份文件的重要程度。

文本分析
语料清洗(数据预处理)
去掉停用词,筛选重复的话
分词(用分词器)
句子A:我/喜欢/看/电影
句子B:我/不/喜欢/看/电影
语料库(构造语料库)
我,喜欢,看,电影,不
词频(统计词频)
句子A:我1,喜欢1,看1,电影1,不1
句子B:我1,喜欢1,看1,电影1,不0
词频向量(字符串转换成向量,根据词频构造向量)gensim
句子A:[1, 1, 1, 1, 1]
句子B:[1, 1, 1, 1, 0]
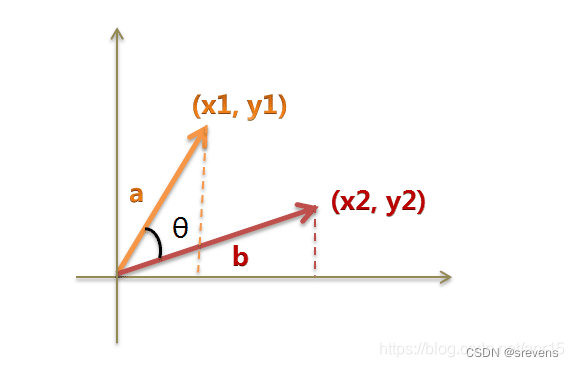
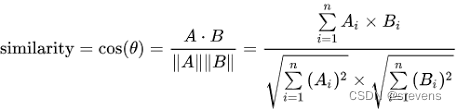
计算相似度
用余弦计算相似度

















 1307
1307

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









