






NER的基础概念
命名实体识别(Named Entity Recognition)
旨在识别文本中感兴趣的实体,如位置、组织和时间。
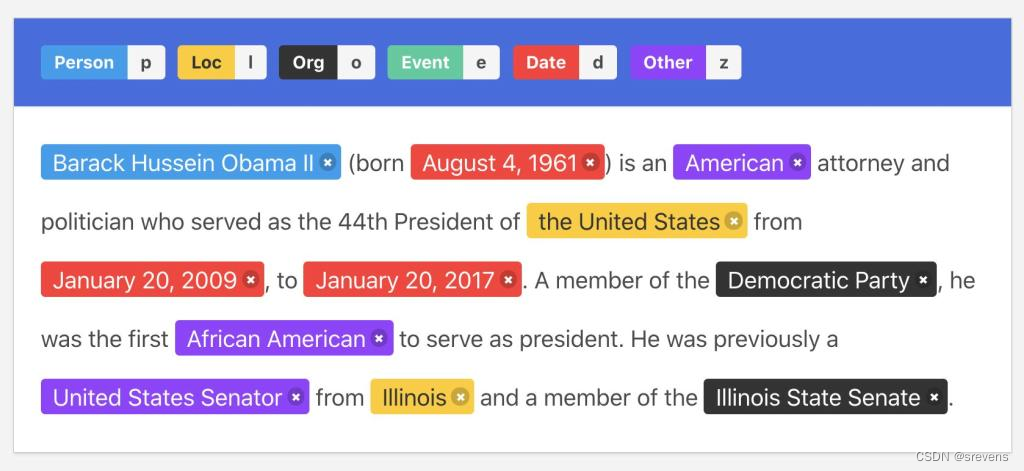
一个较完善的中文NER数据集
one-hot
- 机器学习算法无法直接用于数据分类。数据分类必须转换为数字才能进一步进行。
- One-Hot编码,又称为一位有效编码,主要是采用N位状态寄存器来对N个状态进行编码,每个状态都由他独立的寄存器位,并且在任意时候只有一位有效。
假设我们有两个特征:
- 颜色和大小
- 颜色特征的状态(取值)有红色和蓝色
- 大小特征的状态(取值)有小、中和大
使用one-hot编码时,我们会为每个特征分别创建相应的二进制特征向量。
- 对于颜色特征,我们创建两个新的二进制特征,分别表示红色和蓝色。
- 对于大小特征,我们创建三个新的二进制特征,分别表示小、中和大。
- 两个特征,每个特征分别有两、三个状态,使用One-Hot编码后会产生总共五个独立的特征。
然后,根据每个样本的实际取值,将相应的二进制特征设置为1,其余特征设置为0。
颜色:[红色,蓝色]
红色=>[1, 0]
蓝色=>[0, 1]
大小:[小,中,大]
小=>[1, 0, 0]
中=>[0, 1, 0]
大=>[0, 0, 1]
如果一个样本的颜色是蓝色,大小是中 => [蓝色,中]
- 那么对应的one-hot编码可以表示为:颜色特征编码为[0, 1],大小特征编码为[0, 1, 0]。
- 完整的特征数字化的结果为[0, 1, 0, 1, 0]
如果一个序列是 ‘蓝色,中’, ‘红色,小’, ‘红色,大’,One-Hot编码就为
[0, 1, 0, 1, 0]
[1, 0, 1, 0, 0]
[1, 0, 0, 0, 1]
优点:
- 扩充了特征
- 保留了特征的无序性,避免了数值比较:One-Hot编码将一个离散特征转换为一组二进制特征,每个特征代表一种可能的状态。这样不会引入特征值之间的大小或顺序关系,而是将它们视为平等且独立的选项。它们被表示为二进制向量,而不是具有数值含义的连续变量。
- 假设我们有一个特征是"季节",可能的取值是{“春季”, “夏季”, “秋季”, “冬季”}。
- 使用One-Hot编码时,"春季"可以表示为[1, 0, 0, 0],"夏季"可以表示为[0, 1, 0, 0],"秋季"可以表示为[0, 0, 1, 0],"冬季"可以表示为[0, 0, 0, 1]。这些二进制向量表示了特征的各个状态,每个季节之间的距离相等。
- 如果我们使用连续变量来表示季节,例如使用1表示春季,2表示夏季,3表示秋季,4表示冬季。每个季节之间的距离不同,算法可能会将季节之间的数值关系当作一种有序性,而进行不必要的数值比较和排序。但实际上,季节是一种离散特征,它们之间没有大小关系,只是不同的状态而已。
缺点:
- 维度灾难:如果特征的状态数量非常大,One-Hot编码会导致特征空间的维度急剧增加。这会增加模型的复杂度,并且对计算资源的要求也会增加。
- 冗余性:One-Hot编码可能会引入冗余性,特别是在特征具有大量状态时。它会使用多个二进制位来表示每个状态,其中一个位始终为0。这样会浪费存储空间和计算资源。
- 忽略了特征之间的相似性:One-Hot编码将每个特征都视为独立的,忽略了特征之间可能存在的某种相似性或相关性。这可能导致丢失一些有用的信息,影响模型的表达能力。
通过这种方式,我们可以将多个离散的特征都转换为二进制特征向量,使得机器学习算法可以处理和理解这些特征。每个特征的one-hot编码都是相互独立的,不会混淆特征之间的关系,同时保留了每个特征的信息。
word2vec
*One-hot representation用来表示词向量非常简单,但是却有很多问题。最大的问题是我们的词汇表一般都非常大,比如达到百万级别,这样每个词都用百万维的向量来表示简直是内存的灾难。这样的向量其实除了一个位置是1,其余的位置全部都是0,表达的效率不高,不能很好地刻画词与词之间的相似性,能不能把词向量的维度变小呢?
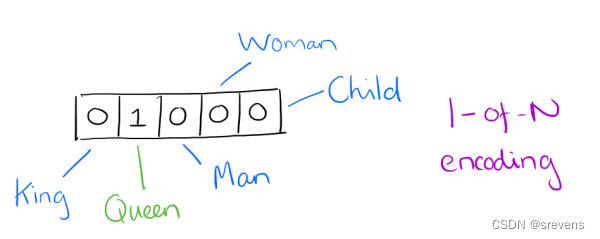
Distributed representation
Distributed representation可以解决One-hot representation的问题,它的思路是通过训练,将每个词都映射到一个较短的词向量上来(这里的“短”是相对于 one-hot representation 的“长”而言的)。将所有这些向量放在一起形成一个词向量空间,而每一向量则为该空间中的一个点,在这个空间上引入“距离”,则可以根据词之间的距离来判断它们之间的(词法、语义上的)相似性了。这个较短的词向量维度是多大呢?这个一般需要我们在训练时自己来指定。
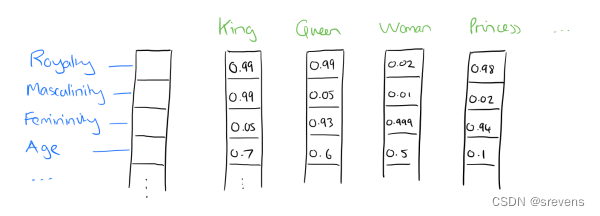
比如下图我们将词汇表里的词用"Royalty",“Masculinity(阳刚之气)”, "Femininity(女性气质)"和"Age"4个维度来表示,King这个词对应的词向量可能是(0.99,0.99,0.05,0.7)。当然在实际情况中,我们并不能对词向量的每个维度做一个很好的解释。
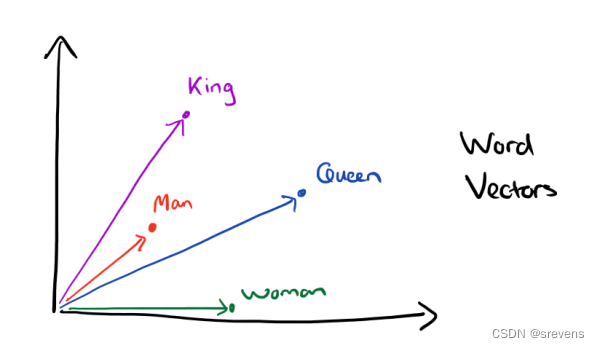
有了用Distributed Representation表示的较短的词向量,我们就可以较容易的分析词之间的关系了,比如我们将词的维度降维到2维,有一个有趣的研究表明,用下图的词向量表示我们的词时,我们可以发现:

在word2vec出现之前,已经有用神经网络DNN来用训练词向量进而处理词与词之间的关系了。采用的方法一般是一个三层的神经网络结构(也可以多层),分为输入层,隐藏层和输出层(softmax层)。
关于定义数据的输入和输出,一般分为CBOW(Continuous Bag-of-Words)与Skip-Gram两种模型。
CBOW模型的训练输入是某一个特征词的上下文相关的词对应的词向量,输出就是这特定的一个词的词向量。
比如下面这段话,我们需要的输出词向量(learning)上下文对应的词有8个,前后各4个,这8个词是我们模型的输入。由于CBOW使用的是词袋模型(即不考虑词语的顺序),因此这8个词都是平等的,也就是不考虑他们和关注的词之间的距离大小,只要在我们上下文之内即可。
这样我们的输入是8个词向量,输出是所有词的softmax概率(训练的目标是期望训练样本特定词对应的softmax概率最大),对应的CBOW神经网络模型输入层有8个神经元,输出层有词汇表大小个神经元。隐藏层的神经元个数我们可以自己指定。通过DNN的反向传播算法,我们可以求出DNN模型的参数,同时得到所有的词对应的词向量。这样当我们有新的需求,需要求出某8个词对应的最可能的输出中心词时,我们可以通过一次DNN前向传播算法并通过softmax激活函数找到概率最大的词对应的神经元即可。
Skip-Gram模型和CBOW的思路是反着来的,输入是特定的一个词的词向量,而输出是特定词对应的上下文词向量。还是上面的例子,我们的上下文大小取值为4, 特定的这个词"Learning"是我们的输入,而这8个上下文词是我们的输出。
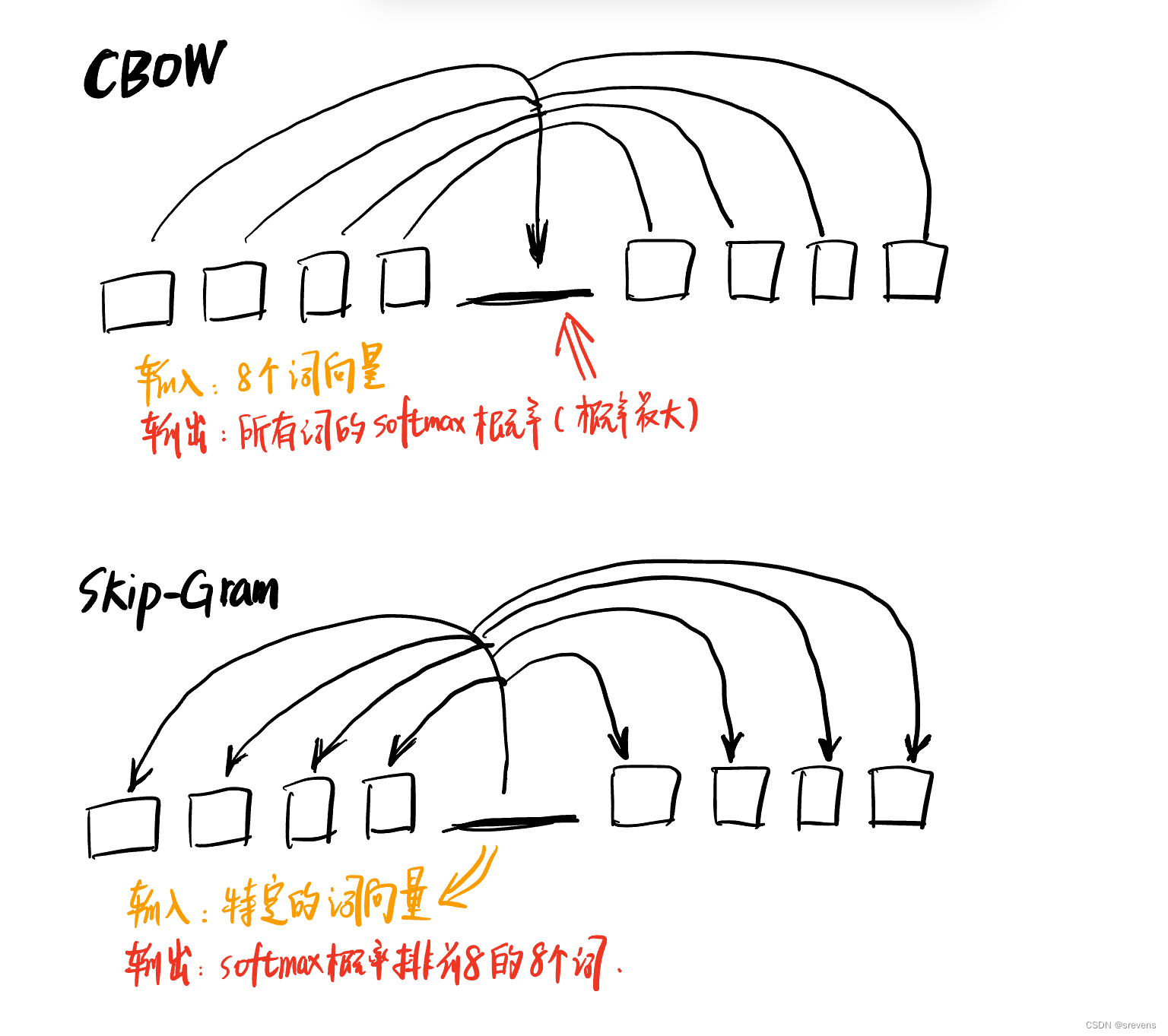
这样我们这个Skip-Gram的例子里,我们的输入是特定词, 输出是softmax概率排前8的8个词,对应的Skip-Gram神经网络模型输入层有1个神经元,输出层有词汇表大小个神经元。隐藏层的神经元个数我们可以自己指定。通过DNN的反向传播算法,我们可以求出DNN模型的参数,同时得到所有的词对应的词向量。这样当我们有新的需求,要求出某1个词对应的最可能的8个上下文词时,我们可以通过一次DNN前向传播算法得到概率大小排前8的softmax概率对应的神经元所对应的词即可。
以上就是神经网络语言模型中如何用CBOW与Skip-Gram来训练模型与得到词向量的大概过程。但是这和word2vec中用CBOW与Skip-Gram来训练模型与得到词向量的过程有很多的不同。
word2vec为什么不用现成的DNN模型,要继续优化出新方法呢? 最主要的问题是DNN模型的这个处理过程非常耗时。我们的词汇表一般在百万级别以上,这意味着我们DNN的输出层需要进行softmax计算各个词的输出概率的的计算量很大。有没有简化一点点的方法呢?
(本人大四,有一定的python和pytorch基础,今天开始学习NER,希望坚持下去。)














 794
794











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









