






- 转载请注明原作者以及原文链接
- 作者:上官轩言
爬虫流程
-
爬虫中起始的url构造成request对象-->爬虫中间件-->引擎-->调度器
-
调度器把request-->引擎-->下载中间件--->下载器
-
下载器发送请求,获取response响应---->下载中间件---->引擎--->爬虫中间件--->爬虫
-
爬虫提取url地址,组装成request对象---->爬虫中间件--->引擎--->调度器,重复步骤2
-
爬虫提取数据--->引擎--->管道处理和保存数据
scrapy框架运行流程:
1.scrapy中模块的具体作用
| Scrapy Engiline(引擎) | 总指挥:负责数据和信号的在不同模块间的传递 | scrapy已经实现 |
|---|---|---|
| Scheduler(调度器) | 一个队列,存放引擎发过来的reuqests请求,并返回引擎 | scrapy已经实现 |
| Downloader(下载器) | 下载把引擎发过来的requests请求,并返回给引擎 | scrapy已经实现 |
| spider(爬虫) | 处理引擎带来的response,提取数据,提取url,并交给引擎 | 需要手写 |
| Item Pipeline(管道) | 处理引擎传过来的数据,比如存储 | 需要手写 |
| Downloader Middlewares(下载中间件) | 可以自定义的下载扩展,比如设置代理 | 一般不用手写 |
| Spidr MiddleswareSpider(中间件) | 可以自定义requests请求和进行response过滤 | 一般不用手写 |
2.scrapy入门
1.安装scrapy
命令:
sudo apt-get install scrapy或者(推荐):
Windows系统打开powershell或者命令提示符输入
安装之前需要修改(确定)镜像源
Python更换国内pip源详细教程_pip国内源配置-CSDN博客
pip/pip3 install scrapy2.项目开发流程
-
创建项目:scrapy startproject mySpider
-
生成一个爬虫:scrapy genspider baidu baidu.com
-
提取数据:根据网站结构在spider中实现数据采集相关内容
-
保存数据:使用pipeline进行数据后续处理和保存
request请求对象:由url,method,post_data,headers等构成; response响应对象:由url,body,status,headers等构成; item数据对象:本质是一个字典。
3.创建项目
创建scrapy项目的命令(下列命令均在power shell/cmd或者在vscode/pycharm中的终端中完成):
scrapy startproject <项目名字>示例:
scrapy startproject myspider生成的目录和文件结果如下:

可以通过tree myspider来展示
爬虫文件的创建:
在项目根目录下执行:
scrapy genspider <爬虫名字> <允许爬取的域名>实例(这里的实例是用师资力量|讲师介绍_黑马程序员网站资源做的):
cd myspider
scrapy genspider itcast https://www.itheima.com/teacher.html讲解:
-
爬虫名字:作为爬虫运行时的参数;
-
允许爬的域名:为对于爬虫设置的爬取范围,设置之后用于过滤要爬取的url地址,如果爬取的url地址与允许的域名不同,则被过滤掉。
运行scrapy爬虫:
命令:在项目目录下执行:
scrapy crawl <爬虫名字>示例:
scrapy crawl itcast编写爬虫文件
1.打开myspider目录查看scrapy.cfg文件
[settings] #settings主要表明项目配置的详细文件
default = myspider.settings #设置myspider目录下的settings文件作为详细配置文件
[deploy] #scrapy项目部署部分
#url = http://localhost:6800/
project = myspider #工作环境基于myspider这个目录2.打开爬虫文件itcast.py
import scrapy #导入scrapy库
class ItcastSpider(scrapy.Spider): #ItcastSpider爬虫类继承自scrapy.Spider
name = "itcast" #爬虫名字
allowed_domains = ["itcast.cn"] #允许的域名
start_urls = ["https://www.itheima.com/teacher.html"] #起始url地址,需自己修改
#默认时['https://itcast.cn/']
def parse(self, response): #response——发送出去的请求对应响应(定义对于start_urls的相关操作)
pass3.实现爬取逻辑parse
获取Xpath路径
1.右键需要爬取的数据点击检查打开开发者工具

2.选中所需的代码节点

3.复制Xpath
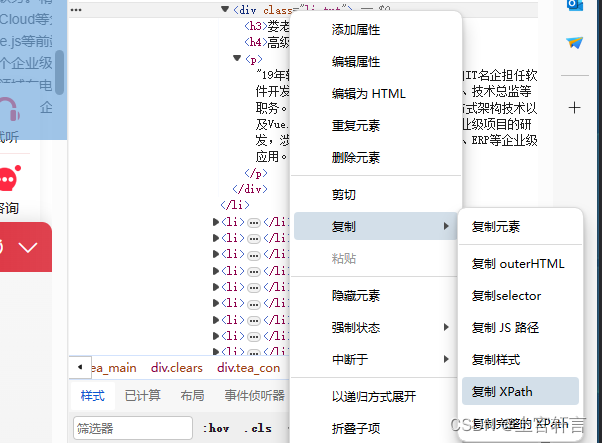
4.Xpath
/html/body/div[1]/div[6]/div/div[2]/div[6]/div/div[2]/div[1]/ul/li[1]/div
获取所有教师节点
def parse(self, response):
# with open('itcast.html','wb')as f:
# f.write(response.body)
# t_list=response.xpath('//div[@class="li_txt"]')
t_list=response.xpath('/html/body/div[1]/div[6]/div/div[2]/div[6]/div/div[2]/div/ul/li/div')
print(len(t_list))此时运行爬虫文件查看是否报错

-
注:如果不想查看日志文件可以使用 ——nolog

遍历教师节点
for node in t_list: #遍历教师节点
temp={} #创建一个字典
temp['name'] = node.xpath('./h3/text()') #xpath方法返回的时选择器对象列表
temp['title'] = node.xpath('./h4/text()')
temp['desc'] = node.xpath('./p/text()')
print(temp) #打印遍历的结果
break #只打印一个1.照样先查看是否报错

2.不查看日志文件直接显示结果

temp['name'] = node.xpath('./h3/text()')[0].extract() #如果想获取某个对象可以直接使用索引
temp['title'] = node.xpath('./h4/text()')[0].extract() #extract()从选择器对象中提取数据
temp['desc'] = node.xpath('./p/text()')[0].extract()-
extract()和extract_first()
extract()返回一个包含所有匹配结果的列表,不抛出异常,适用于需要批量提取数据的情形。
extract_first()返回第一个匹配项的单一结果,或者在无匹配时返回 None 或空字符串,提供了更稳健的无匹配 处理方式,适用于期望单个结果或进行条件检查的场景。
4.保存数据
for node in t_list:
temp={}
temp['name'] = node.xpath('./h3/text()')[0].extract()
temp['title'] = node.xpath('./h4/text()')[0].extract()
temp['desc'] = node.xpath('./p/text()')[0].extract()
yield temp date_list = []
for node in t_list:
temp={}
temp['name'] = node.xpath('./h3/text()')[0].extract()
temp['title'] = node.xpath('./h4/text()')[0].extract()
temp['desc'] = node.xpath('./p/text()')[0].extract()
date_list.append(temp)
return date_list
-
这里不能直接使用return temp,否则只会返回一个数据
-
数据返回形式:
-
第一段代码最终返回的是一个包含所有提取数据的 列表。
-
第二段代码使用
yield返回一个 生成器,该生成器在迭代时逐个产出字典。
-
-
内存占用与性能:
-
第一段代码需先将所有数据存入列表
date_list,然后一次性返回。如果t_list很大,可能导致内存占用较高,尤其是在处理大量数据时。 -
第二段代码通过生成器逐个返回字典,无需一次性加载所有数据到内存。这对于处理大规模数据或需要节省内存的情况更为友好,因为它实现了“按需生成”和“流式处理”。
-
-
使用场景:
-
如果下游代码需要一次性处理所有提取到的字典(如直接写入文件、构建数据结构等),第一段代码返回的列表可能更方便。
-
如果下游代码可以接受逐个处理字典(如逐条插入数据库、实时处理数据等),或者需要节省内存,第二段代码的生成器方式更为合适。
-
-
定位元素以及提取数据、属性值的方法

解析并获取scrapy爬虫中的数据:利用xpath规则字符串进行定位和提取
-
response.xpath方法的返回结果是一个类似list的类型,其中包含的是selector对象,操作和列表一样,但是有一些额外的方法
-
额外方法extract():返回一个包含有字符串的列表
-
额外方法extract_first():返回列表中的第一个字符串,列表为空没有返回None














 969
969











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









