







这三个命令是正式release的1.2新加入的命令,三个命令一起介绍,是因为三个命令配合使用可以实现节点的维护。在1.2之前,因为没有相应的命令支持,如果要维护一个节点,只能stop该节点上的kubelet将该节点退出集群,是集群不在将新的pod调度到该节点上。如果该节点上本生就没有pod在运行,则不会对业务有任何影响。如果该节点上有pod正在运行,kubelet停止后,master会发现该节点不可达,而将该节点标记为notReady状态,不会将新的节点调度到该节点上。同时,会在其他节点上创建新的pod替换该节点上的pod。这种方式虽然能够保证集群的健壮性,但是任然有些暴力,如果业务只有一个副本,而且该副本正好运行在被维护节点上的话,可能仍然会造成业务的短暂中断。
1.2中新加入的这3个命令可以保证维护节点时,平滑的将被维护节点上的业务迁移到其他节点上,保证业务不受影响。
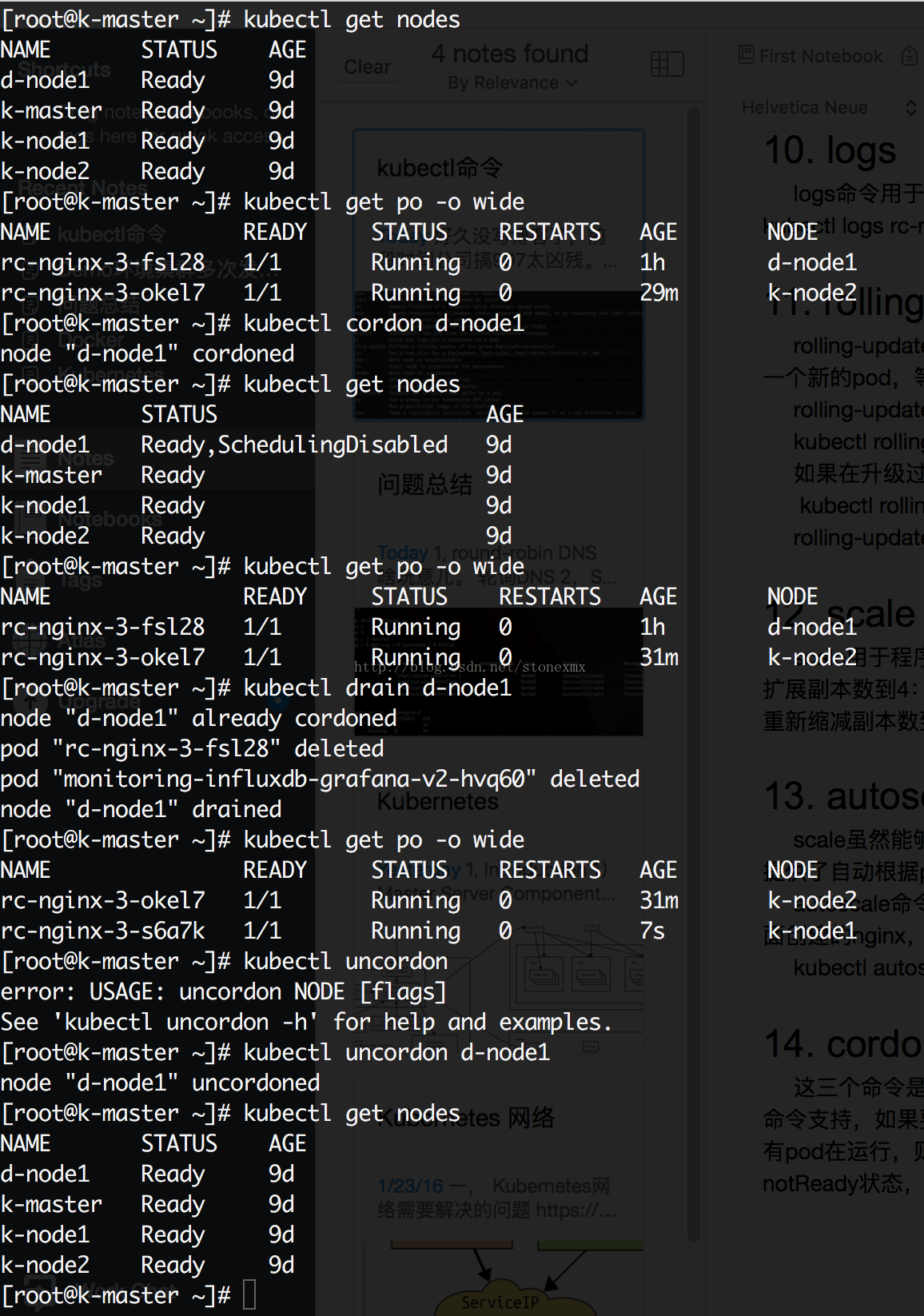
如下图所示是一个整个的节点维护的流程(为了方便demo增加了一些查看节点信息的操作):
1)首先查看当前集群所有节点状态,可以看到共四个节点都处于ready状态;
2)查看当前nginx两个副本分别运行在d-node1和k-node2两个节点上;
3)使用cordon命令将d-node1标记为不可调度;
4)再使用kubectl get nodes查看节点状态,发现d-node1虽然还处于Ready状态,但是同时还被禁能了调度,这意味着新的pod将不会被调度到d-node1上。
5)再查看nginx状态,没有任何变化,两个副本仍运行在d-node1和k-node2上;
6)执行drain命令,将运行在d-node1上运行的pod平滑的赶到其他节点上;
7)再查看nginx的状态发现,d-node1上的副本已经被迁移到k-node1上;这时候就可以对d-node1进行一些节点维护的操作,如升级内核,升级Docker等;
8)节点维护完后,使用uncordon命令解锁d-node1,使其重新变得可调度;
9)检查节点状态,发现d-node1重新变回Ready状态。
若想去掉某个节点,可以直接 只有kubectl delete node ip 则就会直接把节点删除了。
若想把这个节点再从新加入,只需要重启节点的kubelet kube-proxy 就可以了

















 603
603

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









