






之前写的《SQL表关联中的逻辑与效率》一开始计划的是还要写group by在关联中的效率问题的,结果写到一半被人叫走了给忘了……于是在这里补充一篇
接上一篇文章http://blog.csdn.net/strangerzz/article/details/45746621
二、关联中的group by
考虑下面两条语句
语句1
SELECT
t1.oid,
SUM(t2.f0007)
FROM
wrnophq.ne_cell_w t1
INNER JOIN
wrnophq.PERF_CELL_W_TRAFFIC_3 t2
ON
t1.oid = t2.oid
GROUP BY
t1.oid;
对比
语句2
SELECT
t1.oid,
t2.f0007
FROM
xxxx t1
INNER JOIN
(
SELECT
oid,
SUM(f0007) f0007
FROM
yyyy
GROUP BY
oid) t2
ON
t1.oid = t2.oid;
语句2的执行顺序已经很明显了,这里仅贴出语句1的执行计划如下:
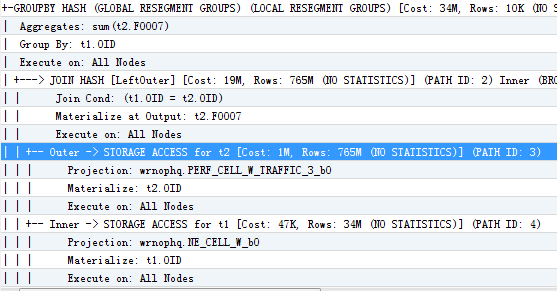
可以看到,在这种语句中,语句1是先做关联,再做group by的。而语句2中先对t2做group by减少了结果的数量,再与t1做关联,这种方式的效率明显比t1的执行效率要高很多。
但是可以简单地用语句2代替语句1来提高查询效率吗?答案是否定的。因为根据处理的数据以及表关联的方式不同,语句1、2得到的结果并不总是相同的。比如,当t1和t2的关联为多对多的关联(即t1、t2中的oid都存在重复的时候,当然这种场景可能不多),或者当做JOIN的关键字段并没有全都出现在group by子句的时候(这种时候需要看具体情况了),以及其他一些我暂时没想到的情况。
总而言之,在一条语句中同时需要做group by和关联的时候,可以根据具体的情况来使用语句2的形式优化查询效率。















 4057
4057

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









