






1.在anaconda prompt中安装pytesseract和pillow: pip install pytesseract
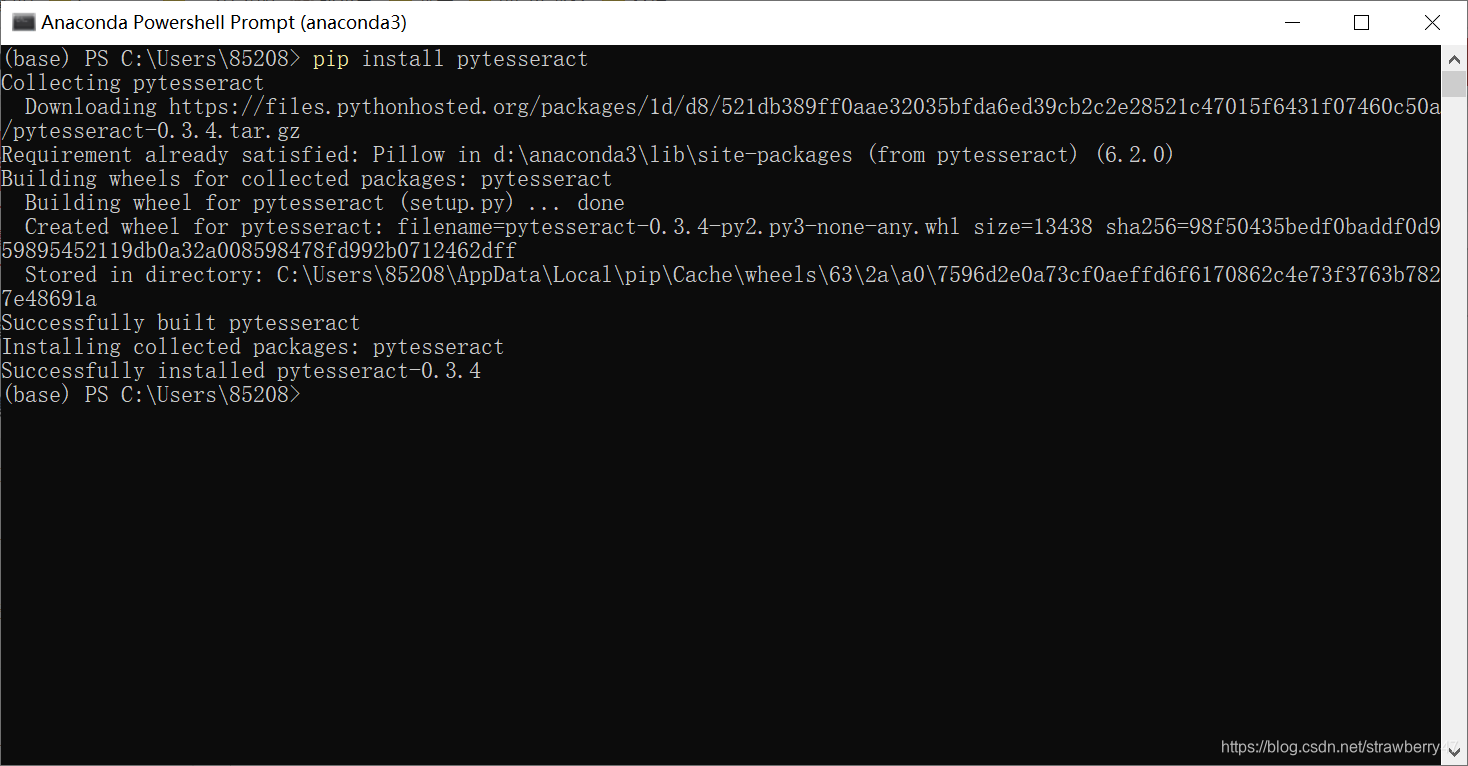 2.安装tesseract-ocr的识别引擎 https://github.com/UB-Mannheim/tesseract/wiki
2.安装tesseract-ocr的识别引擎 https://github.com/UB-Mannheim/tesseract/wiki
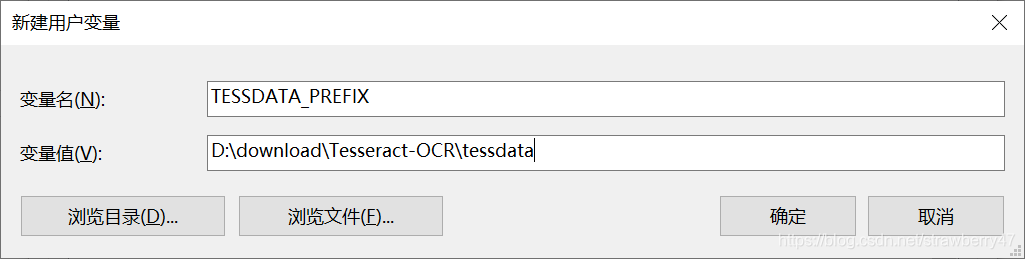
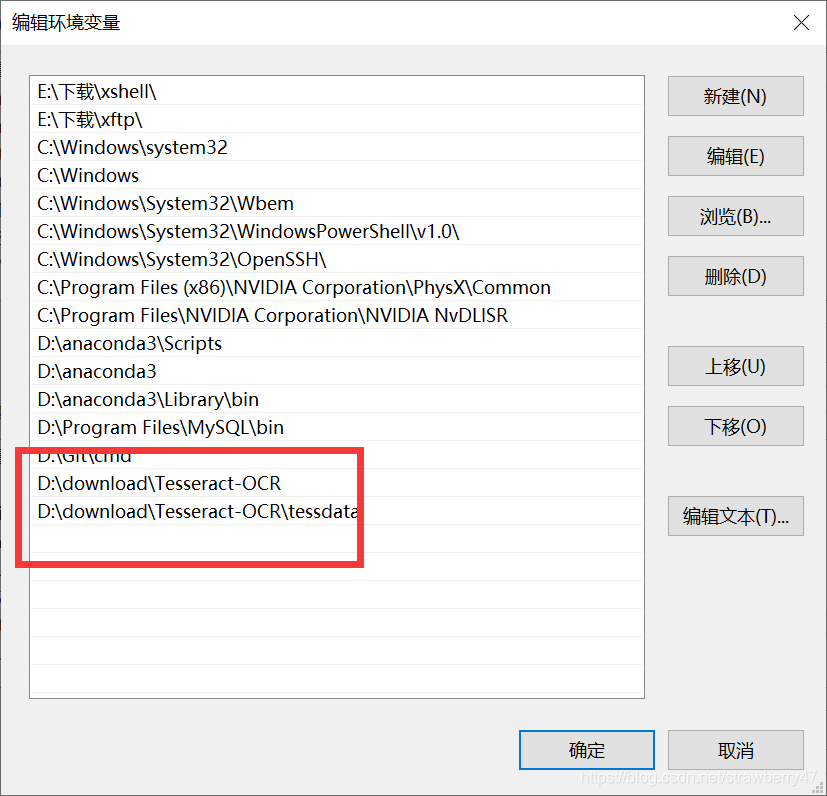
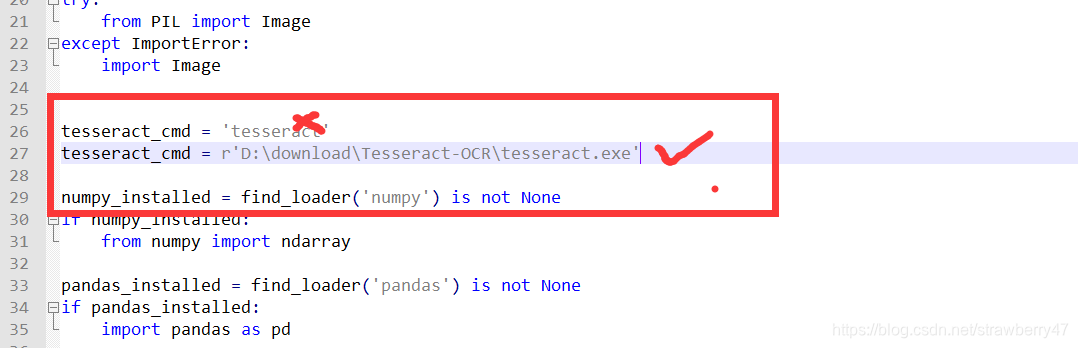
进行配置:需要在两个地方修改,参考https://www.cnblogs.com/chenshengkai/p/11318272.html
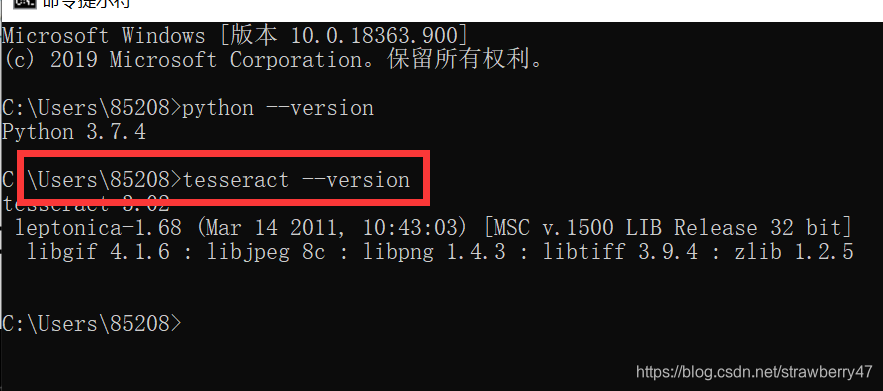
查看是否安装成功:tesseract --version
修改pytesseract.py文件,‘tesseract’修改为安装tesseract-ocrde的安装目录
3.在pycharm中编写代码
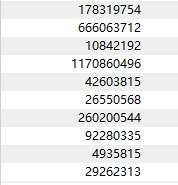
图片:
代码:
from PIL import Image
import pytesseract
image = Image.open('img/0.png')
content = pytesseract.image_to_string(image) # 解析图片
print(content)
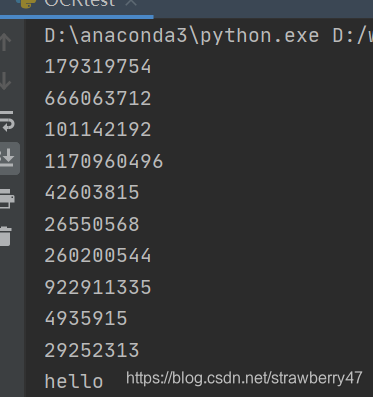
print("hello")运行截图:
4.使用其他语言包
先下载语言包,可参考:https://blog.csdn.net/qq_38161040/article/details/90727456
下载完,直接放到安装位置的tessdata文件夹里就好了
使用时要在pytesseract 库的 image_to_string() 方法里加个参数lang='chi_sim'


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









