






ApplicationMaster实际上是特定计算框架的一个实例,每种计算框架都有自己独特的ApplicationMaster,负责与ResourceManager协商资源,并和NodeManager协同来执行和监控Container。Spark只是可以运行在YARN上一种计算框架。
spark 用户向 YARN 集群提交应用程序时,提交程序中应该包含 ApplicationMaster,用于向资源调度器申请执行任务的资源容器 Container,运行用户自己的程序任务 job,监控整个任务的执行,跟踪整个任务的状态,处理任务失败等异常情况。说的简单点就是,ResourceManager(资源)和 Driver(计算)之间的解耦合靠的就是ApplicationMaster。
初始化
UGI
使用UGI的用户作为当前ApplicationMaster的运行用户。
jar包加载
spark.yarn.archive > spark.yarn.jars > local jars
说明一下,在没有配置 spark.yarn.archive,spark.yarn.jars的时候,系统会不停的上传本地的jar包到hdfs,这个过程是很耗时的。spark.yarn.archive或spark.yarn.jars来缩小spark应用的启动时间。而且spark.yarn.archive 的优先级高于 spark.yarn.jars.
startUserApplication
main()方法运行之后,主要是一些鉴权的操作,最主要的就是startApplication方法。
启动用户application,启动的用户的main-class, 新建一个单独的线程跑。driver和applicationMaster共享container.
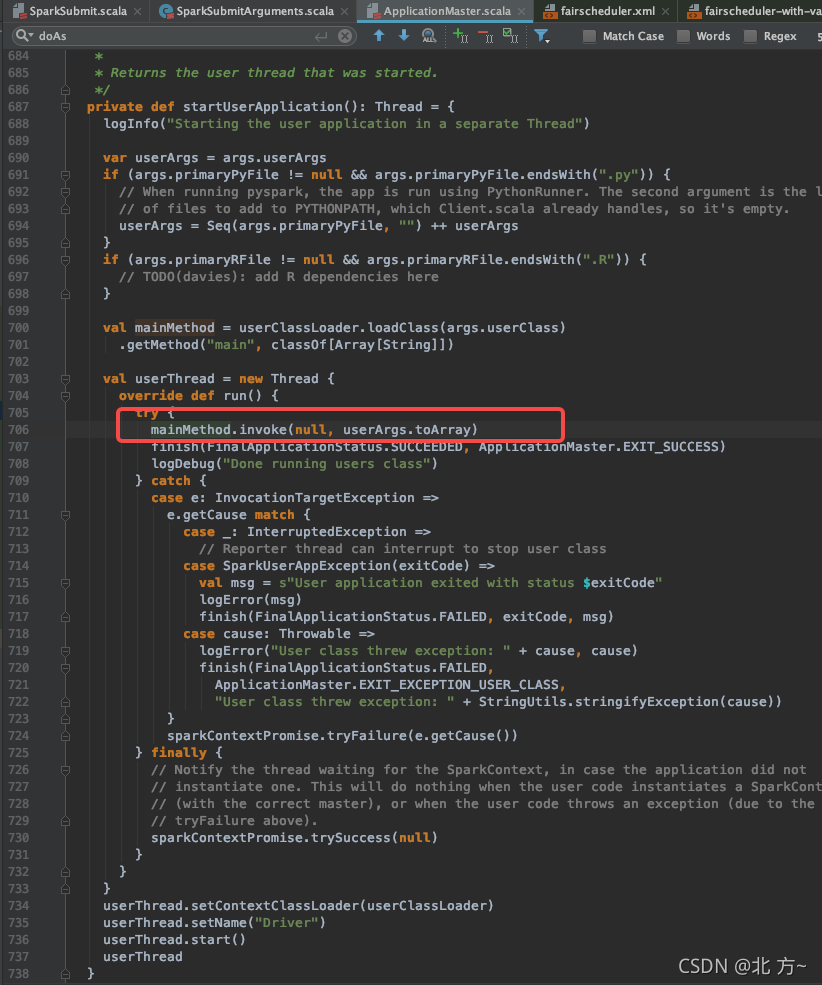
main-class
用户主类在后面再介绍。
SparkContext 初始化
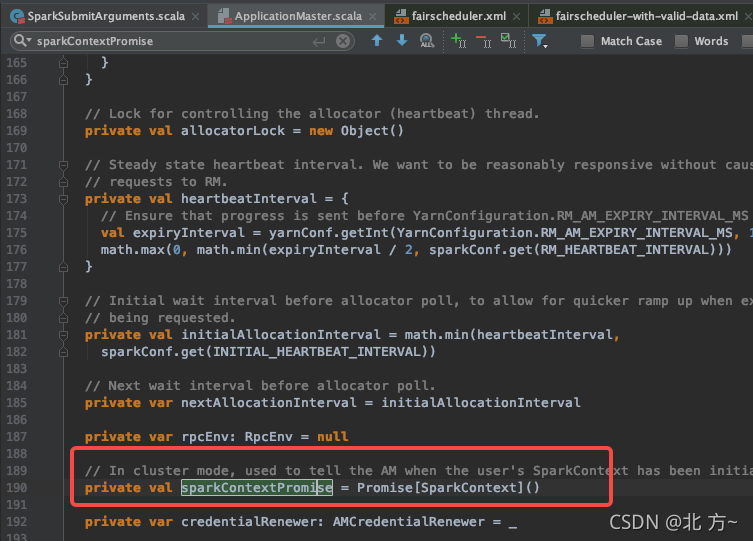
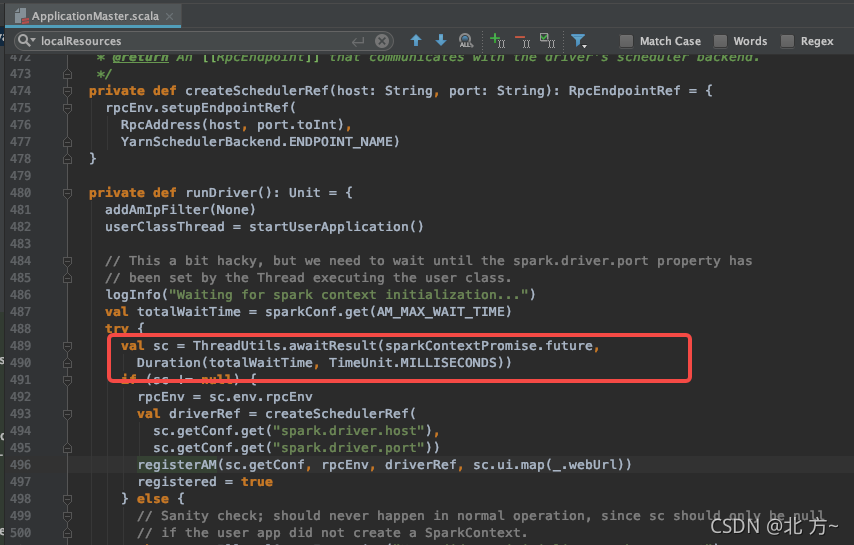
注册ApplicationMaster到yarn
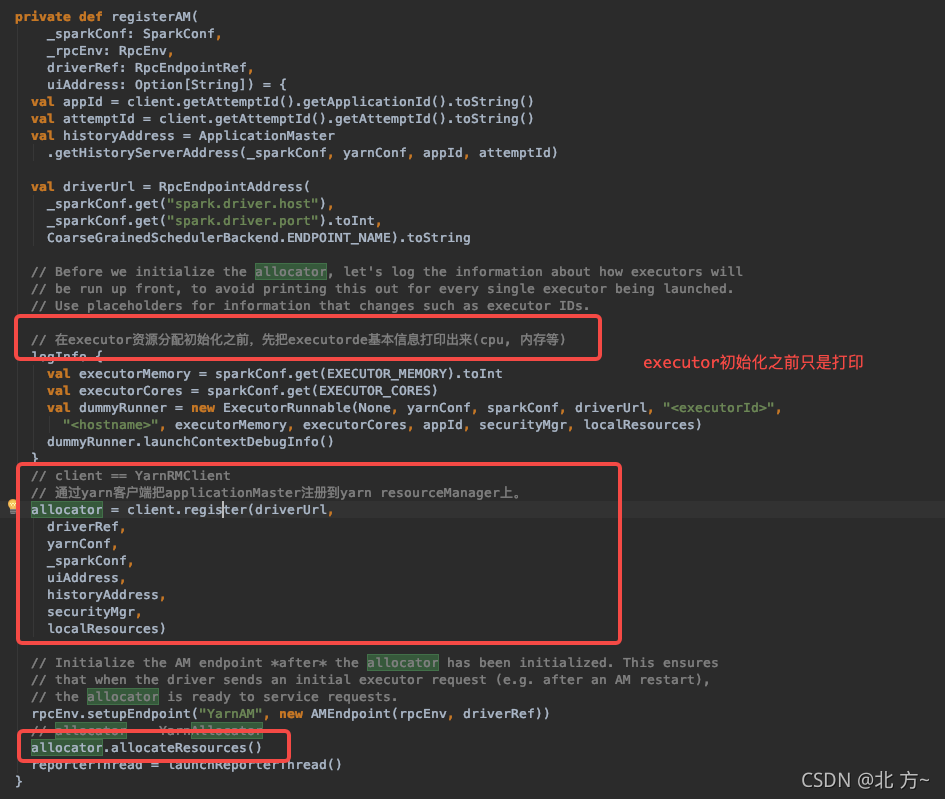
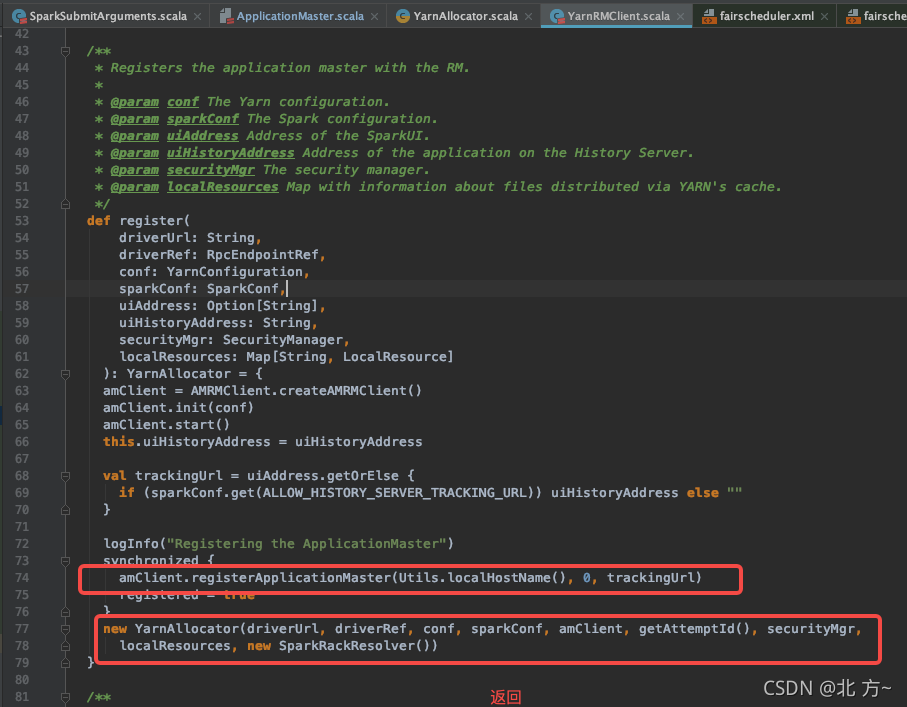
初始化YarnAllocator
初始化executor的数量。
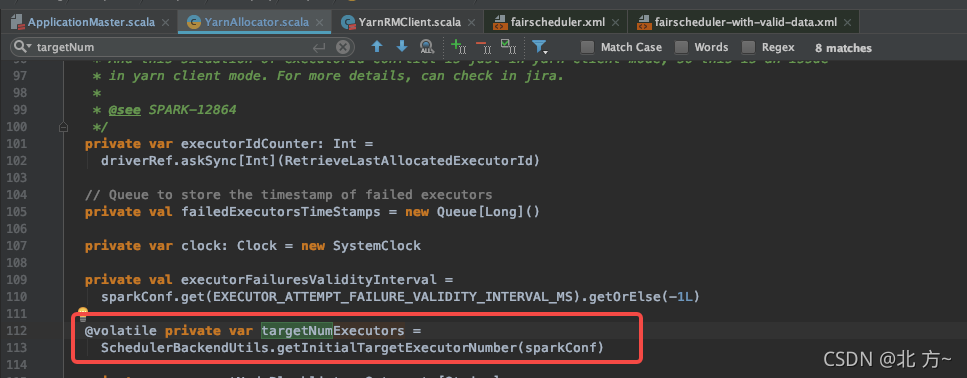
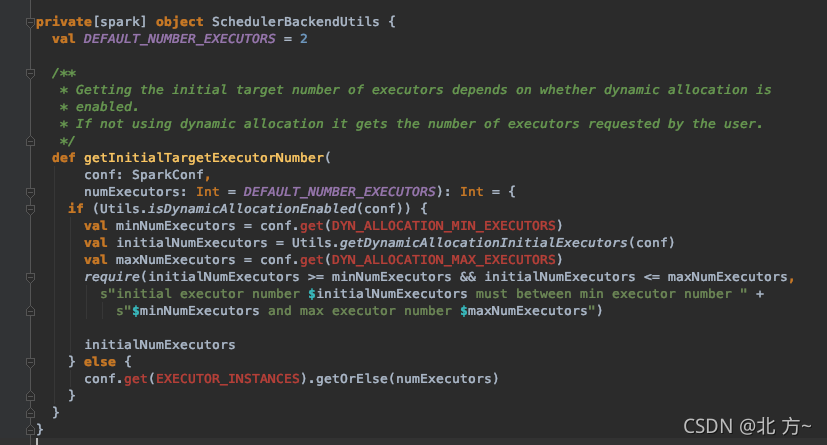
在动态资源分配场景下,初始化executor的数量=max(spark.dynamicAllocation.minExecutors, spark.dynamicAllocation.initialExecutors,spark.executor.instances)
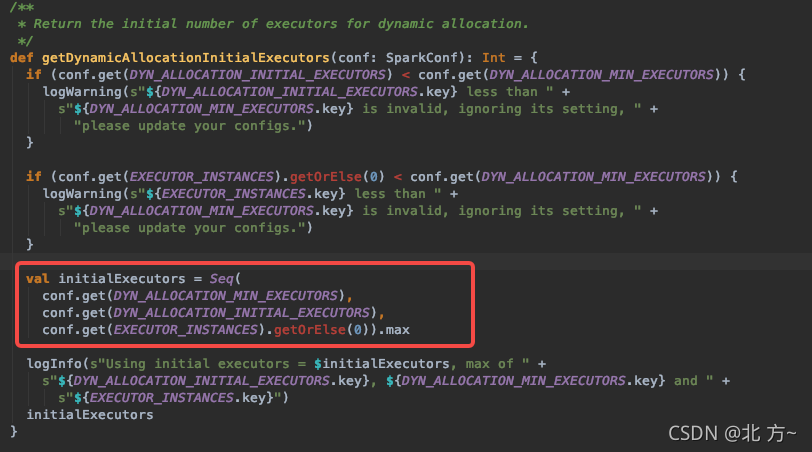
关于动态资源分配的一些参数,关于最小和初始化参数其实可以设置默认值,对于最大executor数量,可以根据自己的集群情况,已经并发情况设置,一般而言需要设置最大executors,以避免某些任务对资源的不合理利用。
- spark.dynamicAllocation.enabled
- spark.dynamicAllocation.minExecutors = 0
- spark.dynamicAllocation.initialExecutors = spark.dynamicAllocation.minExecutors
- spark.dynamicAllocation.maxExecutors
allocateResource
ApplicationMaster向Driver注册之后,会创建一个YarnAllocator实例用来向YARN ResourceMananger请求containers资源,并决定如何分配这些container资源。
YarnAllocator负责向YARN ResourceManager请求containers资源,并决定如何处理YARN返回containers资源。YarnAllocator类的主要实现其实都是通过调用AMRMClient APIs,向AMRMClient告知所需要的containers资源,并更新本地关于containers资源的记录, 并返回YARN给予我们的containers资源。
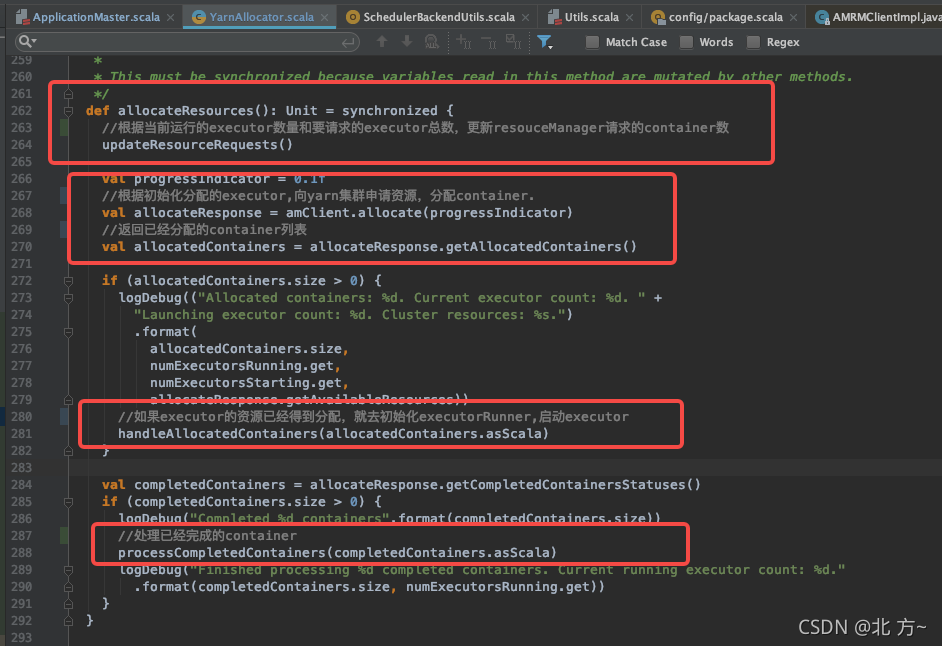
updateResourceRequests
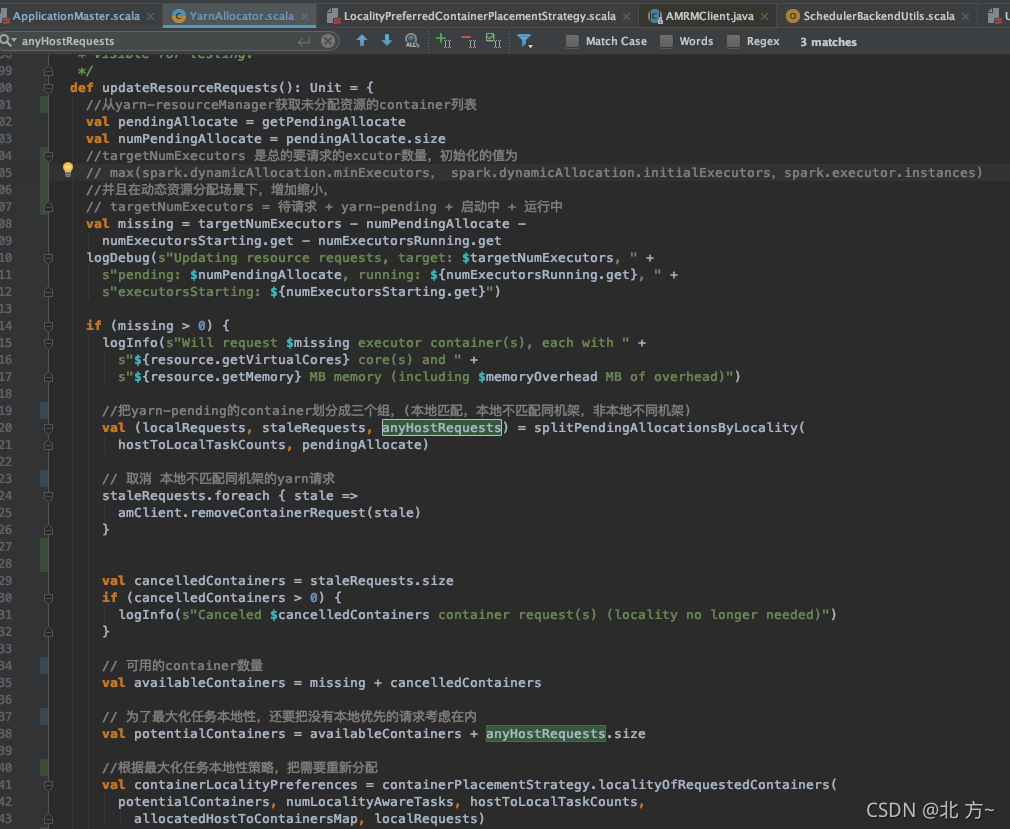
根据当前运行的executor数量和要请求的executor总数,来更新向ResourceManager请求的containers数。在更新container的同时,使用本地化策略,尽量让大部分的请求都能在同一台node上面运行,以提升效率。
总的containers数量=待请求的(missing) + pending(已请求待分配) + running(已请求已分配)
- localRequests 本地匹配的请求,可以在当前node上分配资源并且运行。
- staleRequests 不能将任务在当前节点执行,但是可以在与当前节点同一机架的其他节点上执行的container请求
- anyHostRequests 只能将任务在其他机架上执行的container请求
对于除localRequests之外的两种请求,会进行取消并重新发起请求,然后,根据container放置策略来重新计算本地性,以最大化任务的本地性执行。
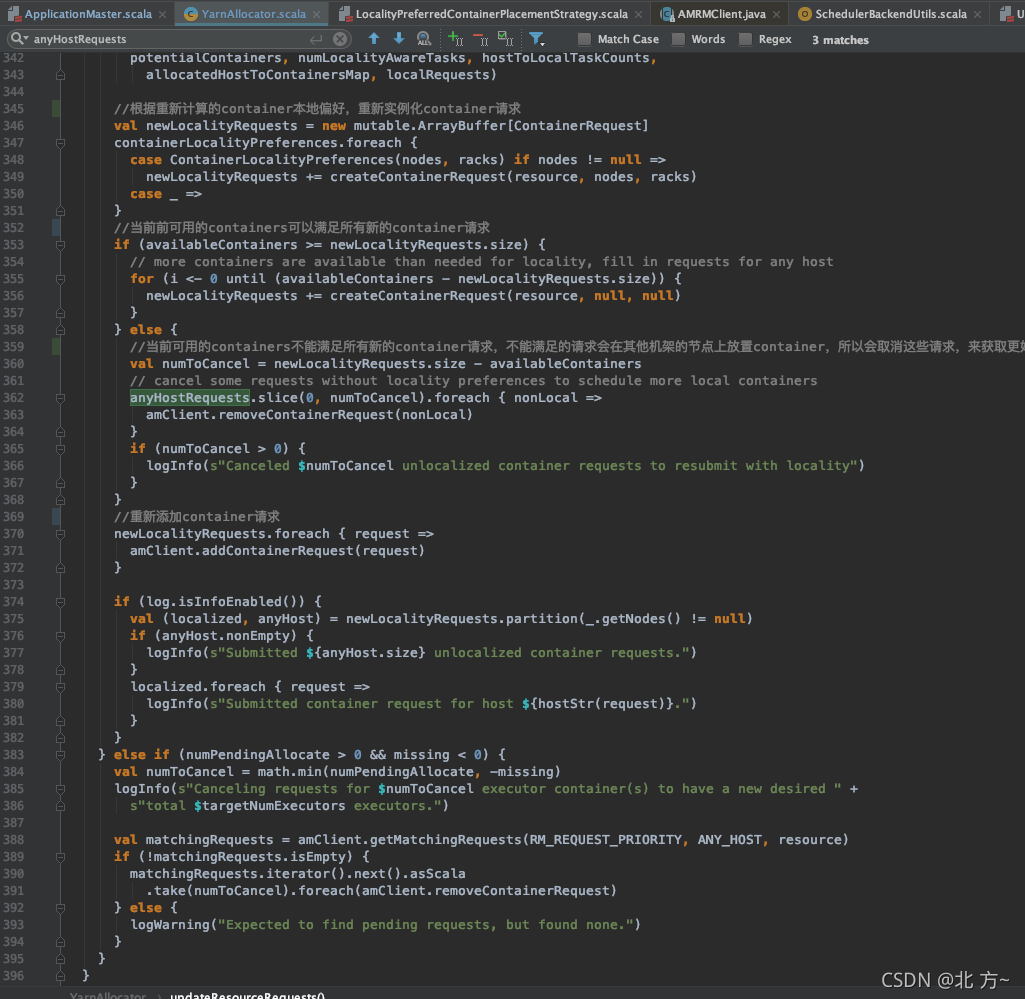
启动executorRunner
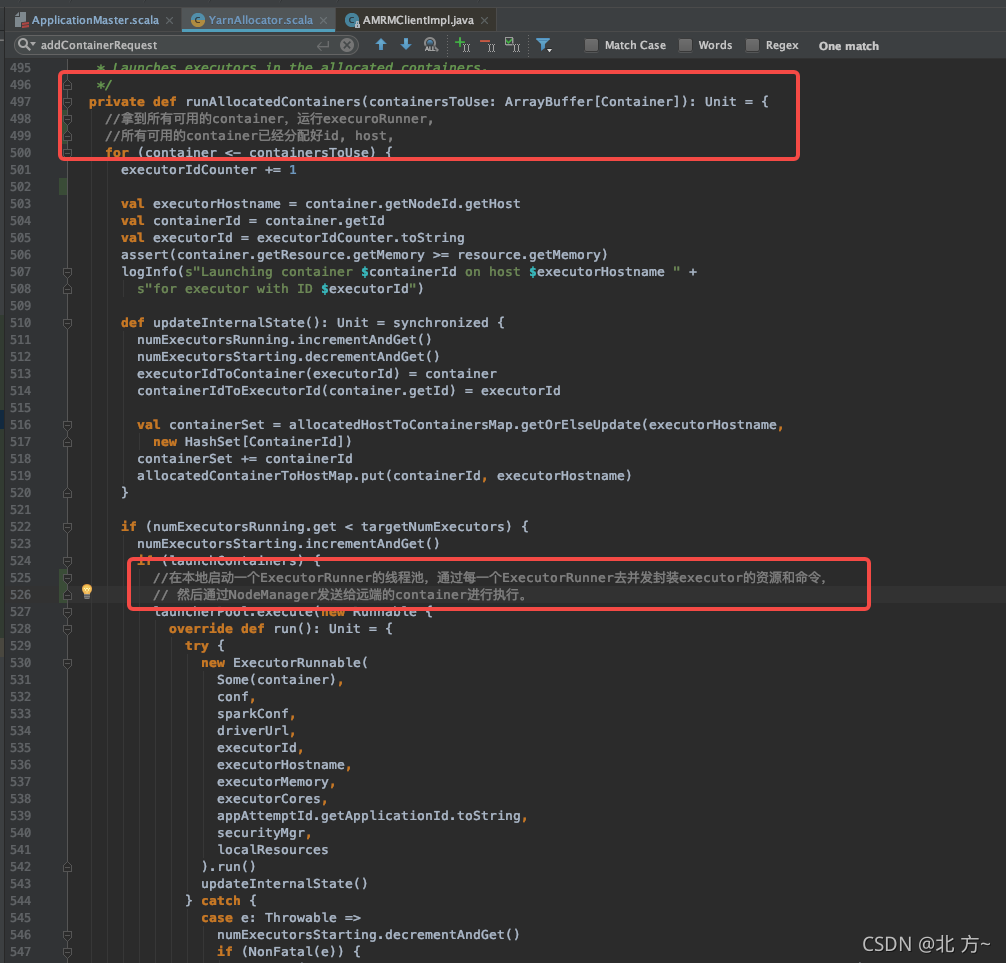
启动executor
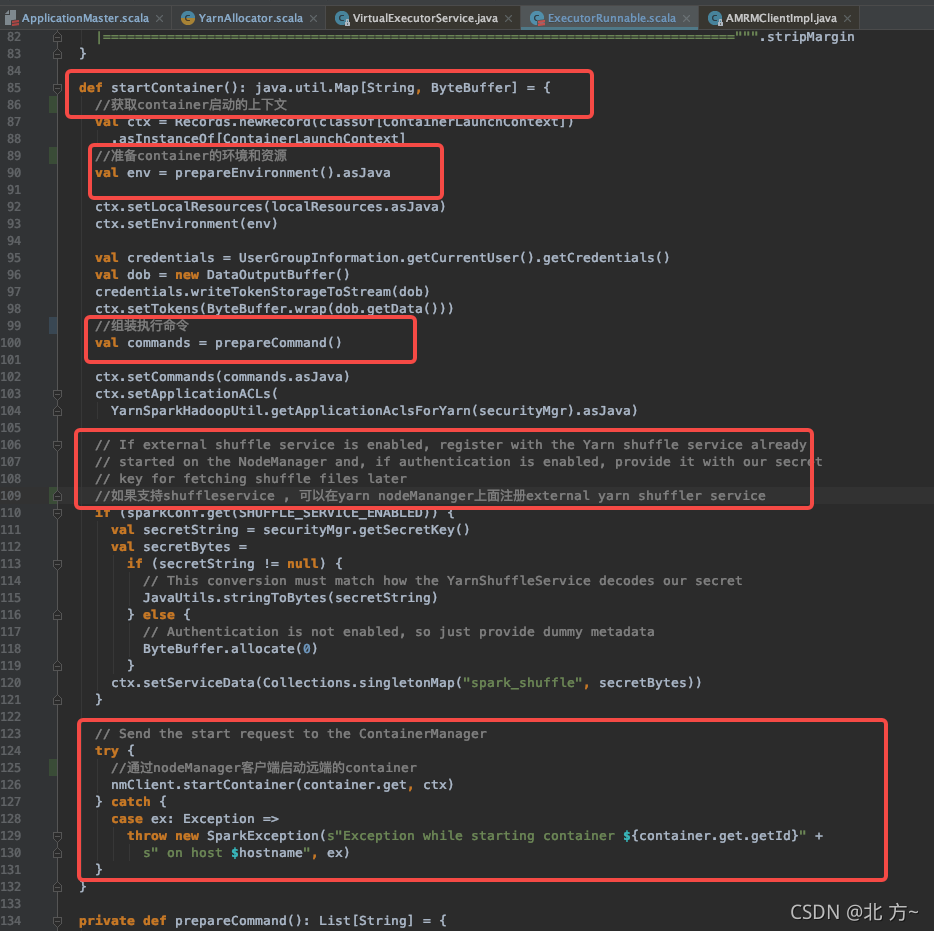
启动executor脚本如下:
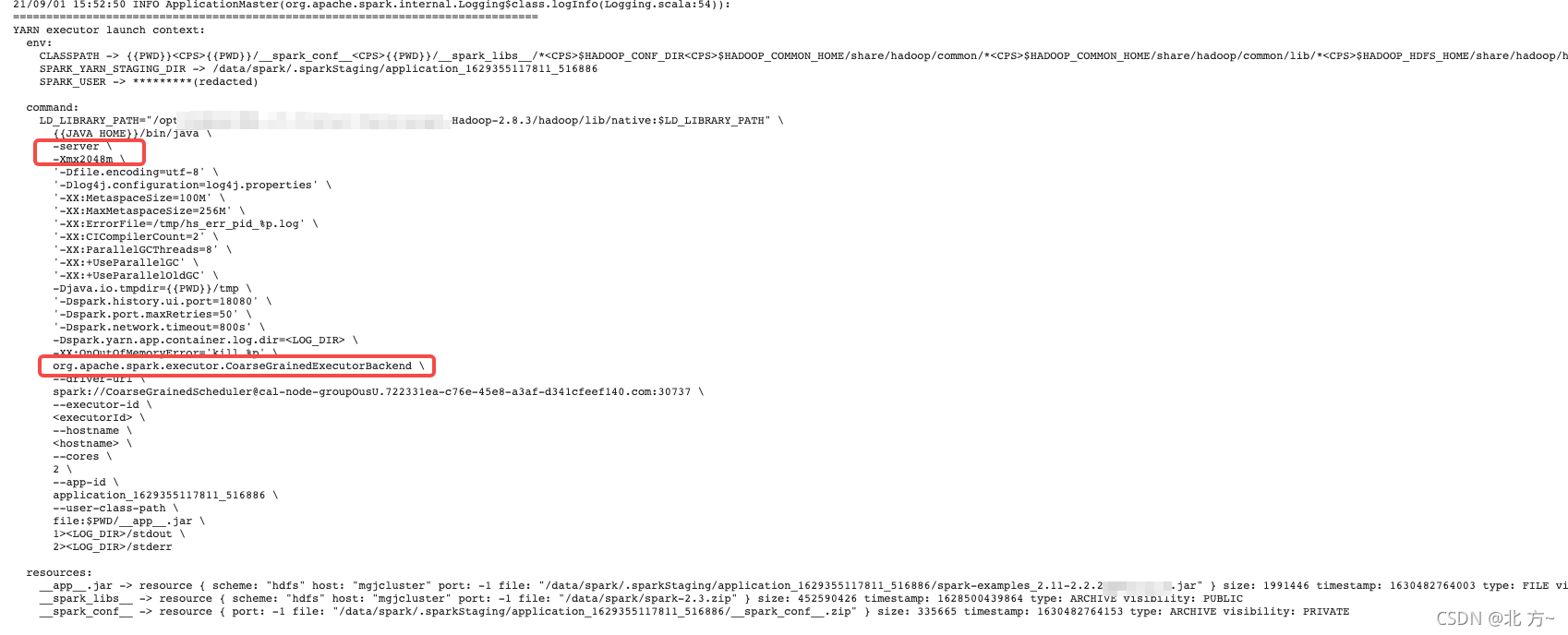
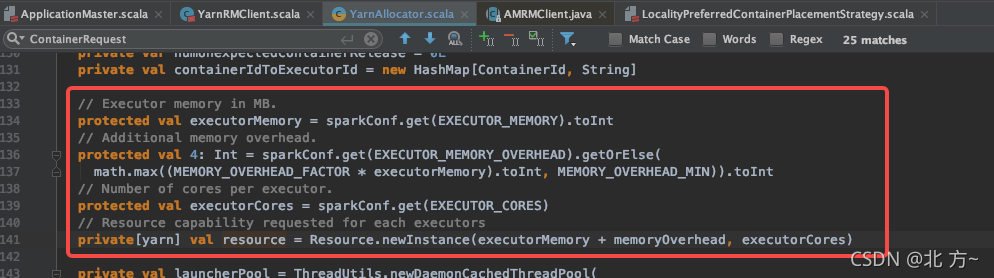
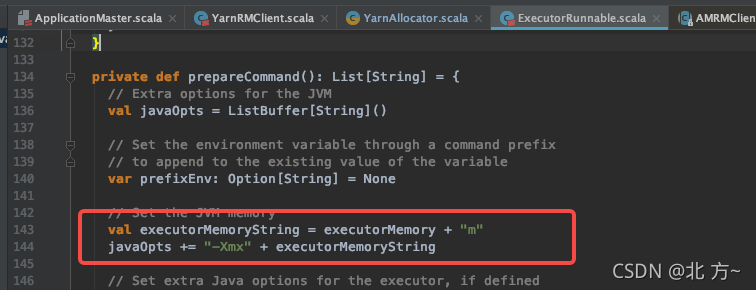
关于executor的资源
executor申请的资源=executorMemory+memoryOverhead.
jvm申请的最大堆内存=executorMemory
一些重要的参数
spark.yarn.executor.memoryOverhead
用于虚拟机的开销、内部的字符串、还有一些本地开销(比如python需要用到的内存)等。其实就是额外的内存,spark并不会对这块内存进行管理
spark.memory.offHeap.size
这个参数指定的内存(广义上是指所有堆外的)。这部分内存的申请和释放是直接进行的不通过jvm管控所以没有GC。
spark.executor.memory
spark.executor.cores
通常意义上每个exector的并发度由spark.executor.cores来决定,有多少个core就有多少的并发,有多少个core就最大有多少个task。spark.executor.cores共享executor的内存。在我们使用中需要清晰的知道自己的程序是内存型还是io型。一般而言我们的task的数据量要大于 spark.executor.cores。这个才能最大化的利用我们的资源。
spark.executor.extraJavaOptions
spark.executor.extraLibraryPath
spark.yarn.app.container.log.dir
-Djava.io.tmpdir=
参考
https://mallikarjuna_g.gitbooks.io/spark/content/yarn/spark-yarn-YarnAllocator.html
https://blog.csdn.net/lovetechlovelife/article/details/112723766

















 520
520

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









