







目录
梯度下降:将代价函数J最小化
1.介绍
用梯度下降算法最小化任意函数J,梯度下降可以在一般问题(多参数)最小化函数
![]()
为了简化符号,下面只用2个参数简化梯度下降的思路
2.思路
给定![]() 的初始值,通常将他们初始化为0,梯度算法中要做的是不停一点点改变这2个参数来使代价函数J变小,直到我们找到J的最小值或者局部最小值。
的初始值,通常将他们初始化为0,梯度算法中要做的是不停一点点改变这2个参数来使代价函数J变小,直到我们找到J的最小值或者局部最小值。
特点:如果起始点偏一点,可能会得到一个完全不同的局部最优解。
3.数学原理
反复执行这一步,直到收敛


4.简化函数理解过程
1)假设最小化函数只有1个参数
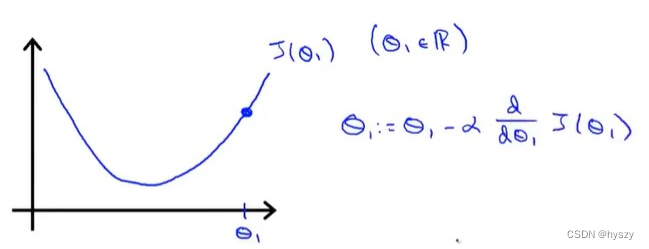
2)![]() 初始化在最低点右边:
初始化在最低点右边:

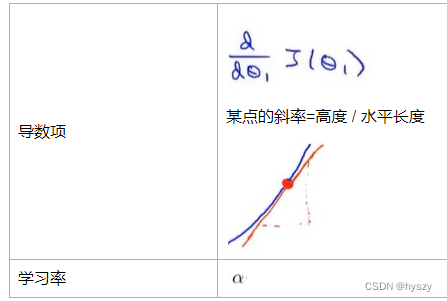
导数项>0,表示正斜率,则学习率*导数项>0
那么新的![]() 变小了,则表示
变小了,则表示![]() 向左移动,变小了。
向左移动,变小了。
这的确是往左边的最小点靠近。
3)![]() 初始化在最低点左边:
初始化在最低点左边:
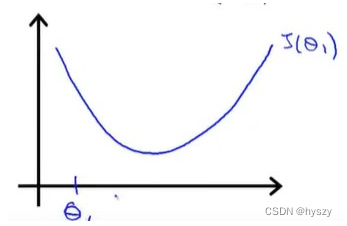
导数项<0,则学习率*导数项<0
那么新的![]() 变大了,则表示
变大了,则表示![]() 向右移动,变大了。
向右移动,变大了。
这的确是往右边的最小点移动。
4)如果已经处于局部最优处(局部最低点),此时导数项为0,那么梯度下降不会更新参数的值。

5)局部最优点的导数项为0,我们从初始值开始,到最优点这个过程,导数项会越来越小,参数![]() 变更幅度会越来越小。所以实际上没有必要在这个过程中减小【学习率】。
变更幅度会越来越小。所以实际上没有必要在这个过程中减小【学习率】。
5.线性回归的梯度下降
5.1 定义
1)

2)梯度下降与代价函数结合,将梯度下降应用于最小化平方差代价函数J

3)当j=0和j=1时,这两种情况的偏导数(代价函数J的斜率)为:

4)将导数代入梯度下降算法,重复直到收敛 (注意是同时更新2个参数)

5.2 线性回归的代价函数
| 一般梯度下降 | 线性回归的代价函数 |
| 可能得到局部最优解 | 总是一个弓状函数——凸函数 没有局部最优解,只有一个全局 |
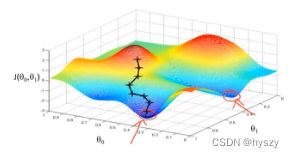 |  |
梯度下降的过程
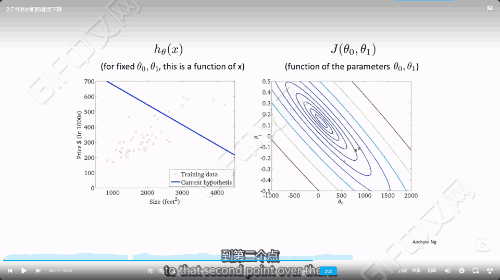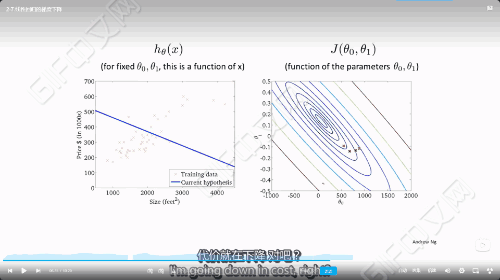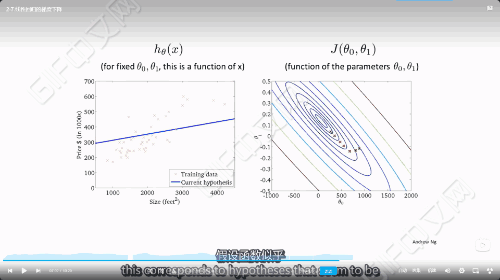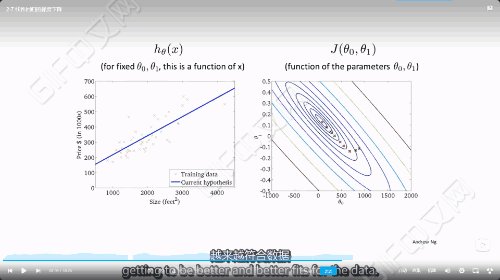















 237
237











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









