









[Paper]JoJoGAN:One Shot Face Stylization
[Code]mchong6/JoJoGAN

摘要
虽然最近在少镜头图像风格化方面取得了进展,但这些方法未能捕捉到人类显而易见的风格细节。眼睛的形状、线条的粗细等细节对于模型来说尤其难以学习,尤其是在有限的数据设置下。在这项工作中,我们的目标是执行使细节正确的 oneshot 图像风格化。给定参考样式图像,我们使用 GAN 反演近似配对真实数据,并使用该近似配对数据对预训练的 StyleGAN 进行微调。然后我们鼓励 StyleGAN 进行泛化,以便将学习到的风格应用于所有其他图像。
介绍
停止花时间收集数据! 我们展示了 JoJoGAN(以最好的动漫 JoJo 的奇妙冒险命名,这是本作品的灵感),一个任意单镜头面部风格化的框架。给定一个输入样式参考,我们可以将样式应用到任何输入图像,仔细保留详细的样式特征,例如眼睛外观、比例等。
仅给定一个参考风格图像,熟练的艺术家就可以复制忠实地捕捉风格的新艺术作品。然而,这对于我们当前的机器学习框架来说仍然很困难。训练图像翻译框架的最佳方法是使用成对的训练数据。然而,这在现实世界设置下是不现实的。很多时候我们无法获得大量的训练数据,更不用说配对数据了。因此,重点放在未配对的图像到图像的转换上,这显着减少了这种限制。尽管如此,仍需要大量数据,从数百到数千不等。虽然在少数镜头翻译方面有一些工作 [1, 2, 3],但结果未能捕捉到不同的风格细节、多样性或缺乏图像质量。
JoJoGAN 旨在通过首先逼近成对的训练数据集,然后微调 StyleGAN 来执行一次性面部风格化来解决这个问题。我们表明我们的方法在零监督的情况下密切关注样式细节,并且可以很好地概括各种不同的样式。训练和演示代码可在 https://github.com/mchong6/JoJoGAN 获得。
方法

JoJoGAN 通过使用单个参考样式图像对预训练的 StyleGAN2 [4] 进行微调来工作。 管道中有几个步骤,
- 我们通过 GAN 反转参考风格图像 y y y 来准备近似配对训练数据,为我们提供风格代码 w w w,它生成一个合理的对应真实人脸图像 x x x。
- 然后我们找到一个 W W W 族,它生成一个真实的人脸图像 $X $族,该族应该与参考风格图像 y y y 匹配。 形成 ( w i , y ) (w_i , y) (wi,y) 对作为我们的配对训练集。
- 根据这些成对的训练数据对 StyleGAN 进行微调。
- 使用微调的 StyleGAN 生成新样本。
数据准备
使用配对数据进行训练是图像风格化任务的最佳选择。然而,它们通常很难获得,需要大量的时间和金钱投资。目前没有适合我们任务的好的开源配对数据集。我们旨在通过生成如图 3 所示的近似配对训练数据集来克服这个问题。给定样式参考图像
y
y
y,我们使用 e4e [5] 执行 GAN 反演以获得
w
w
w。由于 e4e 是在真实人脸图像上训练的,它无法泛化到我们的分布外风格图像,因此给了我们一个近似于
y
y
y 的“真实”人脸图像的
w
w
w,形成了一个成对的
(
w
,
y
)
(w, y)
(w,y) 训练集。

仅使用单个数据点进行训练导致对其他图像的泛化能力较差,请参见图 4。我们通过生成更多的训练数据点来克服这个问题。这个想法很简单,许多真实的人脸图像应该与相同风格的参考图像相匹配。例如,眼睛大小或头发质地略有不同的人脸可以合理地匹配到相同的参考图像。通过在某些选定的层上执行样式混合,在 StyleGAN 中生成这些相似的样本是微不足道的。对于具有 18 个样式调制层的 1024 分辨率 StyleGAN2,我们的样式代码是
w
∈
R
18
×
512
w∈R ^{18×512}
w∈R18×512。我们定义了一个掩码
M
∈
{
0
,
1
}
18
M ∈ \{0, 1\} ^{18}
M∈{0,1}18,它有选择地掩饰了我们想要为数据增强进行风格混合的部分风格代码,FC 作为 StyleGAN 的风格映射层,
z
i
∼
N
(
0
,
I
)
z_i ∼ N (0, I)
zi∼N(0,I) 作为 我们的随机噪声向量,以及
α
∼
U
(
0
,
1
)
α ∼ U(0, 1)
α∼U(0,1) 一个控制风格混合强度的随机标量值。 我们的新样式代码
w
i
w_i
wi 是这样的,
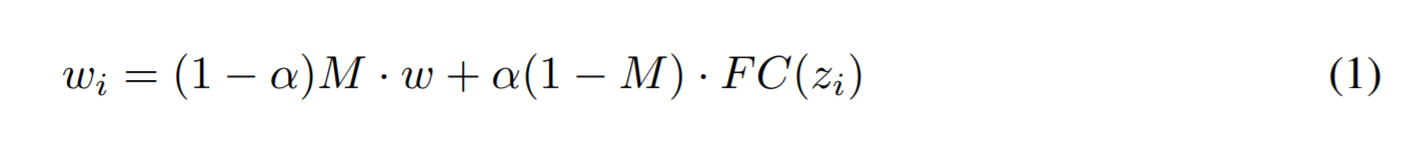
我们对
M
M
M 的选择决定了我们选择进行风格混合的层。这种层的选择使我们能够生成一系列相似的人脸图像
X
X
X 并控制它们的颜色配置文件。例如,我们通过样式混合层 7 到 18,保留姿势和发型,同时改变颜色、眼睛形状等来生成图 3 中的数据集
X
X
X。通过样式混合 7 到 9,我们可以保留样式图像的颜色,为我们提供子集
C
C
C。

微调
生成配对数据后,我们可以微调预训练的 StyleGAN G。让训练对为
(
w
i
,
y
)
(w_i , y)
(wi,y),其中
w
i
w_i
wi 是我们之前获得的风格代码,
y
y
y 是参考风格图像。 然后我们将损失定义为使用 LPIPS [6] 作为我们的感知损失。 我们对训练数据集的不同选择会导致不同的结果,如图 4 所示。

不出所料,仅使用单个示例
x
x
x 进行训练会导致结果不佳,无法捕捉到正确的风格。 由于训练数据集
C
C
C 与参考图像具有相同的颜色,我们微调的 StyleGAN 学会在微调过程中不会大幅改变图像的颜色。 这导致我们的微调模型保留了输入图像的颜色,不受样式参考的强烈影响。 使用 X 进行训练反而完全捕捉了原始风格,包括颜色。
生成
我们的 fintuned StyleGAN 现在生成具有参考风格的图像。 为了执行图像翻译,我们只需对输入图像执行 GAN 反演,并在微调后的 StyleGAN 上执行推理。
多发
请注意,我们的方法可以通过简单地最小化公式 (2) w.r.t 对应于更多样式参考的样式代码,轻松扩展到多镜头样式化。
实验
设置
我们使用 Adam 优化器 [7] 以 2 × 10−3 的学习率对 JoJoGAN 进行 500 次迭代。在 Nvidia A40 上进行微调大约需要 1 分钟。 我们将非保色 JoJoGAN 与最先进的一次/少数镜头风格化方法 StyleGAN-NADA [8] 和 BlendGAN [2] 进行比较。与它们相比,JoJoGAN 可以捕捉定义风格的小细节,同时从输入中保持清晰的面部识别。 在图 5(a) 中,我们的方法完美地捕捉了眼睛的形状和细节,以及来自样式参考的发饰,而在图 5(d) 中,我们准确地捕捉了复杂的面部彩绘。 相比之下,虽然 StyleGAN-NADA 在图 5(e) 中捕捉到了小丑的整体妆容,但它未能捕捉到眼睛和眉毛等细节。 身份也受到很大影响。 BlendGAN 未能捕捉到有意义的风格细节,甚至连发型的颜色都弄错了。

展望
虽然 JoJoGAN 允许简单的一次性人脸样式化,但由于 GAN 反转步骤,执行视频推理是不切实际的。 执行推理的一种直接方法是首先微调我们的 JoJoGAN,并使用它为真实和风格化的人脸生成新的训练数据集。 然后,我们可以以有监督的方式训练一个简单的编码器解码器网络,并对其进行有效的推理。
附录
















 3538
3538











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









