







Lucene是Apache开源的全文检索框架, 是单纯的搜索工具, 简单易用. 现在已经出到5.2.1的版本, 只需在项目中导入必需的几个jar包就能使用. 使用的过程可以概括为,
1) 建立索引
2) 搜索查找, 获取搜索结果
这里我们一起先来学习几个会用到的核心类:
Directory
该类在Lucene中用于描述索引存放的位置信息. 比如:
Directory dir = FSDirectory.open(Paths.get("c:\\lucene\\index")); Analyzer
Analyzer是Lucene的分词器, 可以说是分词解析技术也可以说是搜索引擎的核心技术之一. 一句话被断句分词分析, .使搜索结果更智能更精准. 中文词库分词, 可以使用IKAnalyzer等中文分词工具包.
Analyzer这个类的作用要结合IndexWriterConfig和IndexWriter这两个类去认识:
IndexWriterConfig, 从类名可知, 是一个保存参数配置的类, 用于生成IndexWriter. 比如:
IndexWriterConfig iwc = new IndexWriterConfig(luceneAnalyzer);
iwc.setOpenMode(OpenMode.CREATE);
IndexWriter indexWriter = new IndexWriter(dir,iwc); setOpenMode(...) 设置了IndexWriter的打开方式.
当然还有更多的参数设置, 可以参考这篇文章哦. IndexWriterConfig配置参数说明
上面的三行代码也是创建一个IndexWriter的过程. (dir这个参数就是第一个提及的类Directory.)
IndexWriter 是建立索引的核心类. 如果你也知道Android的SharePreference, SharePreference里面有一个Editor类. IndexWriter 就是类似Editor这样的类, 可以针对索引进行添加(创建新的索引并写入索引文档中), 删除(从索引文档删除索引)和更新(更新索引文档中的索引) 操作. 顺便提一下, Lucene的索引, 会生成对应的索引文档, 所以最好建立文件夹专门存放这些文档.
Document
Document类顾名思义是"文件"类, 其实它是用来存放Field集合. 可以理解为存放文件, 一般都是可转换的文本信息, 比如doc, txt等等. 当把用于被查找的文件信息加入Document后, 再通过
indexWriter.addDocument(document);
IndexReader
对应于IndexWriter, 就有IndexReader. 创建方法 :
IndexReader reader = DirectoryReader.open(FSDirectory.open(Paths.get(index)));它只读取索引文档. 然后交给检索工具IndexSearcher 去完成查找. 根据传进Query检索条件进行检索查找后, 会得到一个ScoreDoc类型的结果集, 然后读取它的Document信息, 就能获取检索结果的具体信息, 比如关键字包含在哪些内容中, 已经这些内容文档的存放路径等等. 这样就算是完成整个检索过程了.
OK, 下面我们来简单的例子体验下, 有兴趣可以自己去看文档详细了解哦.
注: 本例子的代码来自网络, 是很简单易懂的例子, 所以就不再另外写了, 这里只是体验学习, 我们直接学习别人的. 额, 原作者不知道是谁了, 在这里感谢一下.
经过上面的关键类的介绍, 相信看下面例子的代码会容易懂很多了, So 直接上代码.
1) 建立索引文档.
随便在本地建立一个文件夹, 比如C盘根目录创建index文件夹. 路径就是 C:\index . 而要检索的内容文档放在 C盘根目录的source文件夹中, 路径就是C:\source .
public class CreateIndex {
public static void main(String[] args) throws Exception {
/* 指明要索引文件夹的位置,这里是C盘的source文件夹下 */
File fileDir = new File("C:\\source");
/* 这里放索引文件的位置 */
//File indexDir = new File("c:\\index");
String indexPath = "c:\\index";
// Directory dir = FSDirectory.open(indexDir); //v3.6.0
Directory dir = FSDirectory.open(Paths.get(indexPath));
//Analyzer luceneAnalyzer = new StandardAnalyzer(Version.LUCENE_3_6_0);
Analyzer luceneAnalyzer = new StandardAnalyzer();
IndexWriterConfig iwc = new IndexWriterConfig(luceneAnalyzer);
iwc.setOpenMode(OpenMode.CREATE);
IndexWriter indexWriter = new IndexWriter(dir,iwc);
File[] textFiles = fileDir.listFiles();
long startTime = new Date().getTime();
//增加document到索引去
for (int i = 0; i < textFiles.length; i++) {
if (textFiles[i].isFile()
) {
System.out.println("File " + textFiles[i].getCanonicalPath()
+ "正在被索引....");
String temp = FileReaderAll(textFiles[i].getCanonicalPath(),
"GBK");
System.out.println(temp);
Document document = new Document();
Field FieldPath = new StringField("path", textFiles[i].getPath(), Field.Store.YES);
Field FieldBody = new TextField("body", temp, Field.Store.YES);
document.add(FieldPath);
document.add(FieldBody);
indexWriter.addDocument(document);
}
}
indexWriter.close();
//测试一下索引的时间
long endTime = new Date().getTime();
System.out
.println("这占用了"
+ (endTime - startTime)
+ " 毫秒来把文档增加到索引里面去!"
+ fileDir.getPath());
}
public static String FileReaderAll(String FileName, String charset)
throws IOException {
BufferedReader reader = new BufferedReader(new InputStreamReader(
new FileInputStream(FileName), charset));
String line = new String();
String temp = new String();
while ((line = reader.readLine()) != null) {
temp += line;
}
reader.close();
return temp;
}
}2) 执行检索查找的类:
public class ExecuteQuery {
public static void main(String[] args) throws IOException, ParseException {
String index="c:\\index";//搜索的索引路径
// IndexReader reader=IndexReader.open(FSDirectory.open(Paths.get(index)); //v3.6.0的写法
IndexReader reader = DirectoryReader.open(FSDirectory.open(Paths.get(index)));
IndexSearcher searcher=new IndexSearcher(reader);//检索工具
ScoreDoc[] hits=null;
String queryString="好"; //搜索的索引名称
Query query=null;
Analyzer analyzer= new StandardAnalyzer();
try {
//QueryParser qp=new QueryParser(Version.LUCENE_3_6_0,"body",analyzer);//用于解析用户输入的工具 v3.6.0
QueryParser qp=new QueryParser("body",analyzer);//用于解析用户输入的工具
query=qp.parse(queryString);
} catch (ParseException e) {
// TODO: handle exception
}
if (searcher!=null) {
TopDocs results=searcher.search(query, 10);//只取排名前十的搜索结果
hits=results.scoreDocs;
Document document=null;
for (int i = 0; i < hits.length; i++) {
document=searcher.doc(hits[i].doc);
String body=document.get("body");
String path=document.get("path");
String modifiedtime=document.get("modifiField");
System.out.println("BODY---"+body+" ");
System.out.println("PATH--"+path);
}
if (hits.length>0) {
System.out.println("输入关键字为:"+queryString+","+"找到"+hits.length+"条结果!");
}
// searcher.close();
reader.close();
}
}
}例子里面是搜索"好"字. 效果如图:
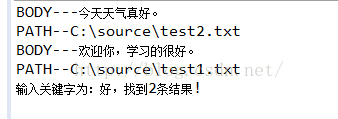
然后修改一下内容文档:

搜索"努力"

中文搜索ok~
当然这是很简单的例子. 本文只是体验学习, 让我们在以后实现全文检索时多一个学习研究的方向. 另外, 好的检索工具, 分词器是非常关键的. 同时英文和中文的词库又不一样. 所以在实现真正的检索时就要考虑这些影响搜索结果的因素.
参考文章















 800
800

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









