







实现简单的搜索——Lucene的搜索流程
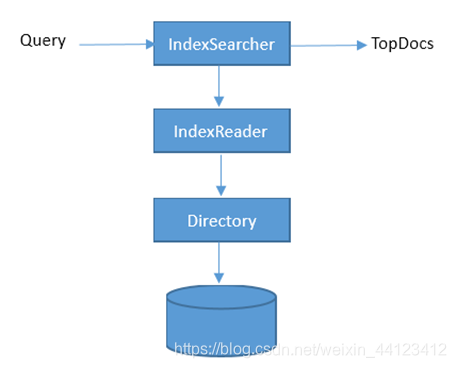
● 初始化Lucene的检索工具类----IndexSearch类,这是Lucene中最基本的检索工具,使用它之前要对IndexReader进行初始化 (需要传入一个保存索引文件的目录参数到其构造方法 ), IndexReader实例对象就可以使用对应的API与存储在索引中的文档document进行交互,在接受Query对象以用于搜索后,并返回TopDocs对象展现搜索结果。
实现简单的搜索——核心API:Index Searcher介绍
● Lucene搜索相关的API多数被包含在org.apache.lucene.search包中。其中最重要的是IndexSearcher类,在lucene中,所有相关搜索的操作都需要使用这个类。下面是这个类的构造方法介绍。
IndexSearcher(Directory path)
使用 Directory对象作为参数,readOnly属性默认为true。
IndexSearcher(Directory path, boolean readOnly)
IndexSearcher(IndexReader r)
使用 IndexReader对象作为参数
IndexSearcher(IndexReader reader, IndexReader[] subReaders, int[] docStarts)
直接指定IndexReader数组中指定位置的IndexReader对象作为参数

NOTE:使用Directory构造的IndexSearcher实例各自持有一个IndexReader实例,若系统中存在多个IndexSearcher实例时,将影响系统的性能(打开IndexReader需要较大的系统开销)。理想的做法应该是一份索引用一个IndexReader实例打开,因为IndexSearcher实例对象本质是由IndexReader进行构造。
实现简单的搜索———— 实现搜索功能:search()方法
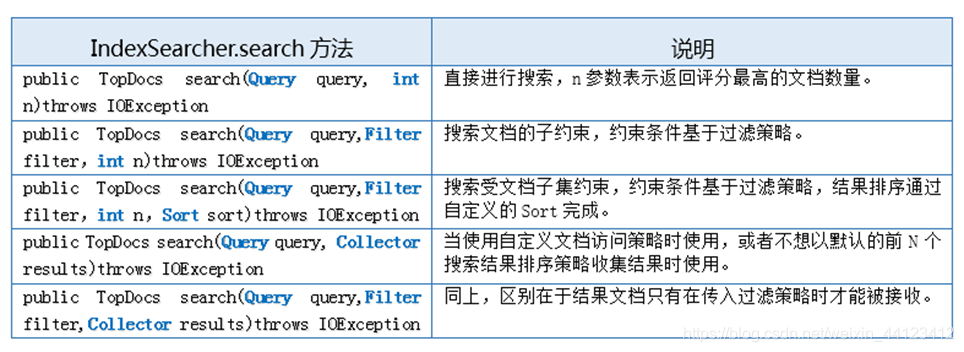
● 获取到 IndexSearcher实例后,可以通过search方法实现搜索,并返回搜索结果·(一般为TopDocs类对象),下表的search方法的主要重载形式。
实现简单的搜索———— 搜索结果的访问:TopDocs类
● search方法调用后会获得其返回的TopDocs类,这个类是Lucene3.X版本后变化比较大的地方,用来替代原来Lucene2.X版本使用Hits类。
TopDocs类中常用的方法与属性如下:
属性:
totalHits ——匹配搜索条件的文档数量
scoreDocs[ ]——包含搜索结果的ScoreDoc对象数组
方法:
getMaxScore()——如果已完成排序(当通过域进行排序时,程 序需要分别控制是否对该域进行评分计算)就返回最大的评分。
实现简单的搜索———— 程序实例:一个最基本的搜索程序
public class BasicSearchingTest {
public static void main(String[] args) throws Exception {
String indexDir = “D:/Workspaces/MyEclipse 9/mylucene/src/lab02/index”;
//打开指定目录下的索引
Directory dir = FSDirectory.open(new File(indexDir));
IndexReader reader=IndexReader.open(dir);
//显示索引中的所有文档
System.out.println(“索引里面document列表:”);
for(int i=0;i<reader.numDocs();i++)
{
System.out.println(reader.document(i));
}
//输出索引中文档数目
System.out.println(“索引里面document数量是:”+reader.numDocs());
reader.close();
IndexSearcher searcher = new IndexSearcher(dir); //构建IndexSerchercher对象
实现简单的搜索———— 程序实例:一个最基本的搜索程序
Term t = new Term("bookname", "book3"); //构建Term对象,域名为"bookname",域值为"book3"
Query query = new TermQuery(t);
//按照指定的query查询,获得评分最高的10个文档
TopDocs hits= searcher.search(query, 10);
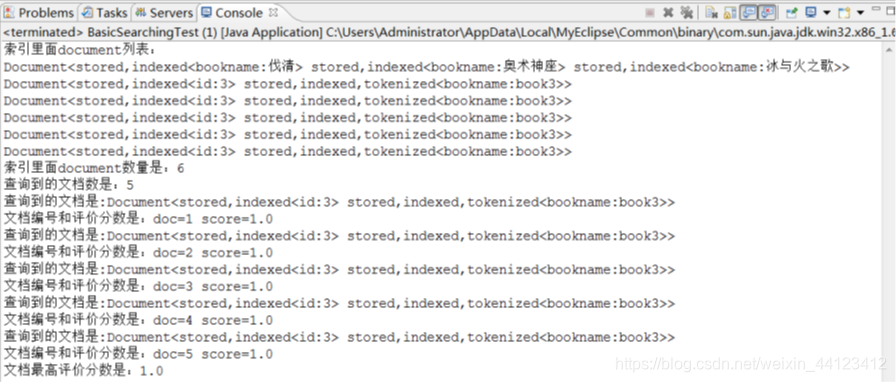
System.out.println("查询到的文档数是:"+hits.totalHits);
for(int i=0;i<hits.totalHits;i++){
//获取查询到的文档
Document doc=searcher.doc(hits.scoreDocs[i].doc);
System.out.println("查询到的文档是:"+doc);
System.out.println("文档编号和评价分数是:"+hits.scoreDocs[i].toString());
}
System.out.println("文档最高评价分数是:"+hits.getMaxScore());
}
}
● 示例使用了Lab04中建立的索引,演示如何查询书名为“book3”的过程。
下面是测试的结果:
近实时搜索———— 一种减少索引&搜索翻转时间的方案
● 近实时搜索:可以使用一个打开的IndexWriter快速搜索索引的变更内容,而不必首先关闭writer,或者向该writer提交;这是2.9版本之后推出的新功能。应用这种技术意味着不需要调用writer中的commit方法,然后再重新打开reader,这样可以节省大量的系统资源,因为调用commit方法必须对索引中的所有文件进行同步,这个同步操作对某些操作系统和文件系统来说通常是负担很重的。近实时搜索其实就是提供了一种方案允许用户对新创建但还未完成提交的段进行搜索。
近实时搜索———— 近实时搜索示例(1)
public class NearRealTimeTest extends TestCase {
public static void main(String[] args) throws Exception {
new NearRealTimeTest().testNearRealTime();
}
IndexReader reader;
IndexSearcher searcher;
IndexWriter writer;
public void testNearRealTime() throws Exception {
Directory dir = new RAMDirectory();//索引存放在内存RAM中
writer = new IndexWriter(dir, new StandardAnalyzer(Version.LUCENE_30), IndexWriter.MaxFieldLength.UNLIMITED);
//建立10个文档加到索引中
for(int i=0;i<10;i++) {
Document doc = new Document();
doc.add(new Field(“id”, “”+i, Field.Store.YES, Field.Index.NOT_ANALYZED_NO_NORMS));
doc.add(new Field(“text”, “aaa”, Field.Store.YES, Field.Index.ANALYZED));
writer.addDocument(doc);
}
近实时搜索———— 近实时搜索示例(2)
writer.deleteDocuments(new Term(“id”, “7”)); // 删除域名id为7的文档
// 创建近实时reader,IndexWriter返回的reader能够对索引中所有有价值的变更进行搜索,包括未提及的变更,返回的reader是只读的。
reader = writer.getReader();
searcher = new IndexSearcher(reader); //将reader封装在IndexSearcher中
Query query = new TermQuery(new Term(“text”, “aaa”)); //建立查询Term
TopDocs docs = searcher.search(query, 10); //查询索引
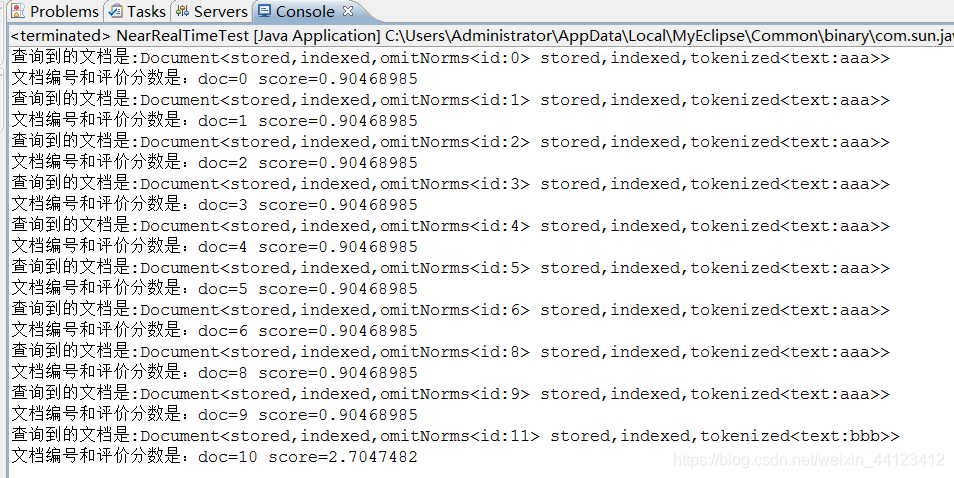
DisplayHits(docs); //显示查询结果
assertEquals(9, docs.totalHits); // 测试查询结果是否为9
Document doc = new Document(); //新建id:11text:bbb的文档
doc.add(new Field(“id”,
“11”,
Field.Store.YES,
Field.Index.NOT_ANALYZED_NO_NORMS));
doc.add(new Field(“text”,
“bbb”,
Field.Store.YES,
Field.Index.ANALYZED));
writer.addDocument(doc);
近实时搜索———— 近实时搜索示例(3)
IndexReader newReader = reader.reopen(); // 重新启动reader
assertFalse(reader == newReader); // 测试验证newreader不是原reader
reader.close(); //关闭旧reader
searcher = new IndexSearcher(newReader);
TopDocs hits = searcher.search(query, 10); // 查询包含<text:aaa>的文档
assertEquals(9, hits.totalHits); // 测试验证是否能查询到9个文档
query = new TermQuery(new Term("text", "bbb"));
hits = searcher.search(query, 1); // 查询包含<text:bbb>的文档
DisplayHits(hits);
newReader.close();
writer.close();
}
近实时搜索———— 近实时搜索示例(4)
● 示例使用了IndexWriter.getReader方法,它会讲缓存中的所有变更刷新到索引目录中,然后通过reopen方法创建一个包含变更的IndexReader。
Lucene评分机制 ——————— Lucene如何评分
● 每当搜索到匹配的文档,该文档都会被赋予一个分值,用于反映匹配的程度。这个分值会计算文档与查询语句之间的相似程度,更高的分数意味着更强的相似程度与匹配程度。在介绍算法之前,要介绍一下数学的向量空间知识。
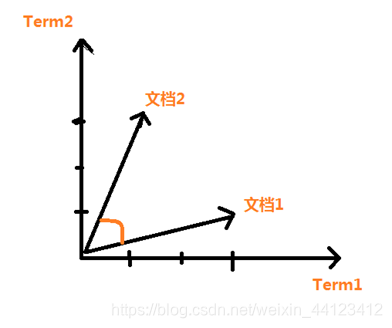
文档(document)与词条(Term)之间的关系是视为一个向量形式D(term1,term2,…term N)。现假设某篇文档中都出现了term1与term2,就可以使用下图所示的二维坐标来表示。
在这个图中,文档1出现Term1的次数为
3,出现Term2的次数为1;文档2出现Term1
的次数为1,出现Term2的次数为3.
所以,可以用向量D1(3,1)D2(1,3)来
表示这两篇文档。以此类推,一个包含N个Term
的搜索引擎的索引库可以看成是一个N维空间向
量,每一篇文档均为其中的一个向量,每一个词
条是向向量空间中的一条轴。
在这个模型中,文档的内容相近的时候,意
味它们的词条也差不多,从逻辑上推理可知它们
在向量空间中的位置会很接近,这两个向量的夹
角就会比较小。
Lucene评分机制 ——————— Lucene如何评分
●现在假设对Term2进行一次检索,检索Q
也作为一个向量,表示为Q(0,1)。在
这个二维坐标轴上,这个检索对应的向量
是与Term2重合的,这就意味着Q与文档2
的夹角要比文档1的夹角要小,所以在本次
检索中,文档2的评分会比文档1的评分要
高。


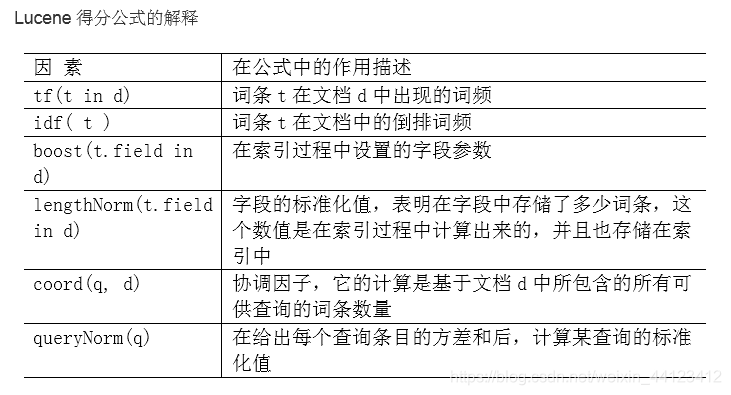
Lucene评分机制 ——————— Lucene的文档得分算法
文档的得分是在用户进行检索时实时计算出来的。如果在建立索引时就已经将每个文档的得分计算好,那么当用户输入任何关键字时,得分最高的文档都会被排在返回结果的最前面,这显然是不合理的。Lucene文档得分公式如下:(推导过程见附件“Lucene评分公式的推导.docx”)😘😘
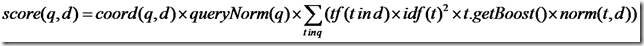
Lucene评分机制 ——使用explanin()方法理解搜索结果评分
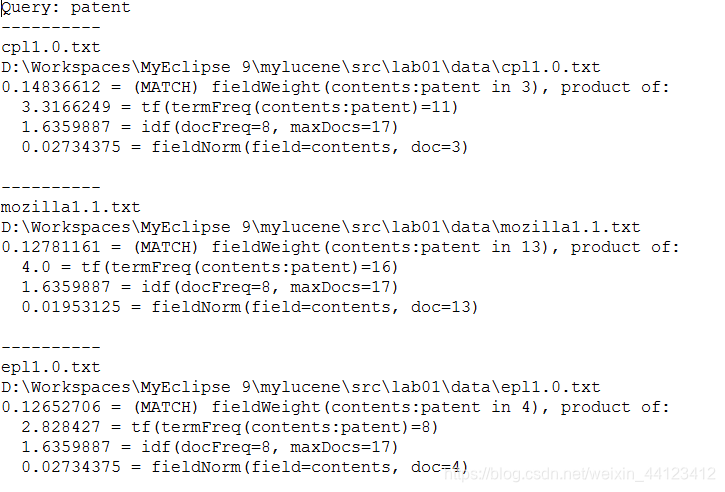
用户如果想了解Lucene得分公式的因子的信息,可以通过Explanation类来获得。Lucene中,IndexSearcher类包含一个explain方法,这个方法通过传入一个Query对象和一个文档ID来返回一个Explanation对象。下面的示例:
// 获取文档得分相关因子的信息
public class Explainer {
public static void main(String[] args) throws Exception {
//使用第一讲中使用TXT文档生成的索引
String indexDir =“D:/Workspaces/MyEclipse 9/mylucene/src/lab01/index” ;
//查询包含"patent"的文档
String queryExpression = “patent”;
Directory directory = FSDirectory.open(new File(indexDir));
QueryParser parser = new QueryParser(Version.LUCENE_30,
“contents”, new SimpleAnalyzer());
//解析生成query对象
Query query = parser.parse(queryExpression);
System.out.println("Query: " + queryExpression);
IndexSearcher searcher = new IndexSearcher(directory);
TopDocs topDocs = searcher.search(query, 10);
for (ScoreDoc match : topDocs.scoreDocs) {
//生成Explanation对象
Explanation explanation
= searcher.explain(query, match.doc); System.out.println("----------");
Document doc = searcher.doc(match.doc);
System.out.println(doc.get(“filename”));
System.out.println(doc.get(“fullpath”));
System.out.println(explanation.toString()); //输出Explanation对象信息
}
searcher.close();
directory.close();
}
}
Lucene多样化查询———————— Query类
● 前面的例子我们已经知道,Lucene查询操作最终需要调用IndexSearch类的search方法,同时传入Query实例对象作为参数。要获取Query实例对象,可以通过Query的子类可以直接实例化,也可以使用用后面介绍的解析查询表达式类QueryParser来得到。Lucene内置的Query类型有:
TermQuery
TermRangeQuery
NumericRangeQuery
PrefixQuery
BooleanQuery
WildcardQuery
FuzzyQuery
MatchAllQuery
Lucene多样化查询——通过词条项进行搜索:TermQuery
● 这是最基本的搜索方式,Term是最小的索引片段,每个Term包含了一个域名和一个文本值。如:
//构建Term对象,域名为"bookname",域值为"book3“
Term t = new Term(“bookname”, “book3");
//构建query对象,TermQuery构造方法语序一个单独的Term对象作为参数
Query query = new TermQuery(t);
NOTE:1、查询值是区分大小写的;
2、不同的分析器采取的索引方式可能不同
Lucene多样化查询——通过字符串进行搜索:PrefixQuery
● 搜索程序可以使用PrefixQuery来搜索指定字符串开头的项的文档
(示例一)
public void testPrefix() throws Exception {
Directory dir = TestUtil.getBookIndexDirectory();
IndexSearcher searcher = new IndexSearcher(dir);
//构建category域的词条
Term term = new Term(“category”,
“/technology/computers/programming");
//以词条项的前缀作为查询字符串的项,所以可以查询这个类别子类的数据
PrefixQuery query = new PrefixQuery(term);
//获取查询结果在文档数
TopDocs matches = searcher.search(query, 10);
int programmingAndBelow = matches.totalHits;
//仅以词条项作为查询字符串的项,所以只可以查询这个类别数据
matches = searcher.search(new TermQuery(term), 10);
//获取查询结果在文档数
int justProgramming = matches.totalHits;
//验证用前缀查询查到的结果文档数多与仅仅以词条项查询到的文档数
assertTrue(programmingAndBelow > justProgramming);
searcher.close();
dir.close();
例子(二):
//创建四个文档Document,其中每个中都保存Field.Text(“name”, “David/Darwen/Smith/Smart”);
//创建写入器…
//创建搜索器,然后构造Term对象
Term pre1 = new Term(“name”, “Da”);//大写D和小写a
Term pre2 = new Term(“name”, “da”);//纯小写
PrefixQuery query = null; //分别构造PrefixQuery对象
query = new PrefixQuery(pre1);
hits = search.search(query);
//打印…但是结果却没有找到,这是因为标准的分词器对数据进行分词的时候会把所有大写字母转换成小写所以"Da"找不到记录
//查询第二个"da"前缀,因为正好标准分词器分词时将数据改成小写所以"da"才能找到结果
query = new PrefixQuery(pre2);
hits = search.search(query);
//打印…但是结果找到
Lucene多样化查询——在指定范围进行搜索:TermRangeQuery
● 索引中的Term对象会按照字典顺序进行排序(通过String.compareTo方法)
,lucene允许使用TermRangeQuery的提供范围内进行文档的直接查询。
示例如下:
Directory dir = TestUtil.getBookIndexDirectory();
IndexSearcher searcher = new IndexSearcher(dir);
//建立title2域中从字符d到字符j的查询
TermRangeQuery query = new TermRangeQuery(“title2”, “d”, “j”, true, true);
TopDocs matches = searcher.search(query, 100);
NOTE: TermRangeQuery构造方法中的两个布尔型参数表示是否包含范围的起点和终点,如果设置为false以为不包含上限或者下限。
Lucene多样化查询——在指定范围进行搜索:NumericRangeQuery
● 如果使用NumericField对象来索引域,就可以使用NumericRangeQuery
类在指定范围搜索该域 。示例如下:
Directory dir = TestUtil.getBookIndexDirectory();
IndexSearcher searcher = new IndexSearcher(dir);
// 查询2013年5月~2013年9月的出版的书籍
NumericRangeQuery query = NumericRangeQuery.newIntRange(“pubmonth”,
201305,
201309,
true,
true);
TopDocs matches = searcher.search(query, 10);
NOTE: NumericRangeQuery构造方法中的两个布尔型参数也是表示范围的起点和终点,如果设置为false以为这无上限或者无下限。
Lucene多样化查询——组合查询:BooleanQuery
● BooleanQuery可以将多种查询组合成为复杂的查询方式。BooleanQuery是作为一个Boolean子句(clauses)的容器存在的,这些子句可以是表示逻辑
“与”“或”“非”的一个子查询,这些属性运行进行逻辑And、OR和NOT的
组合。使用 add方法将查询子句加入到BooleanQuery对象中。
Add方法有2种重载:
Public void add(Query query,BooleanClause.Occur occur)
第一个参数表示子查询的query对象;第二个参数表示子查询的逻辑关系,可以设置为BooleanClause.Occur.MUST表示与(AND)、BooleanClause. Occur.SHOULD表示或(OR)、BooleanClause.Occur.NOT表示非(NOT)
Public void add(BooleanClause booleanclause)
参数的BooleanClause 类型对象是作为Query对象BooleanClause.Occur对象的容器
Lucene多样化查询——组合查询:
BooleanQuery
● BooleanQuery可以将多种查询组合成为复杂的查询方式。BooleanQuery是作为一个Boolean子句(clauses)的容器存在的,这些子句可以是表示逻辑
“与”“或”“非”的一个子查询,这些属性运行进行逻辑And、OR和NOT的
组合。使用 add方法将查询子句加入到BooleanQuery对象中。
Add方法有2种重载:
Public void add(Query query,BooleanClause.Occur occur)
第一个参数表示子查询的query对象;第二个参数表示子查询的逻辑关系,可以设置为BooleanClause.Occur.MUST表示与(AND)、BooleanClause. Occur.SHOULD表示或(OR)、BooleanClause.Occur.NOT表示非(NOT)
Public void add(BooleanClause booleanclause)
参数的BooleanClause 类型对象是作为Query对象BooleanClause.Occur对象的容器
Lucene多样化查询——组合查询:BooleanQuery
示例:
//查询subject域中的包含“search”的所有数据
TermQuery searchingBooks =
new TermQuery(new Term(“subject”,“search”));
//查询2010年出版的书籍
Query books2010 =
NumericRangeQuery.newIntRange(“pubmonth”, 201001,
201012,
true, true);
//构建BooleanQuery对象
BooleanQuery searchingBooks2010 = new BooleanQuery();
//2个查询合并为一个查询,两个查询子句的都是必须的,逻辑关系是与
searchingBooks2010.add(searchingBooks, BooleanClause.Occur.MUST);
searchingBooks2010.add(books2010, BooleanClause.Occur.MUST);
Directory dir = TestUtil.getBookIndexDirectory();
IndexSearcher searcher = new IndexSearcher(dir);
TopDocs matches = searcher.search(searchingBooks2010, 10);
Lucene多样化查询————通过短语查询:PhraseQuery
● 如果建立索引时没有调用Filed.setOmiTermFreqAndPostiopns(true),即没有跳过对该词条项的出现频率与出现位置进行索引(建立纯Boolean域索引)的话,就意味索引中会默认设置包括各个Term的位置信息。
例如,一个域包含短语”the quick brown fox jumped over the lazy”,就算不清楚这个短语的完整拼写,也可以通过PhraseQuery来查询域中与quick fox相关并且相距很近的文档。
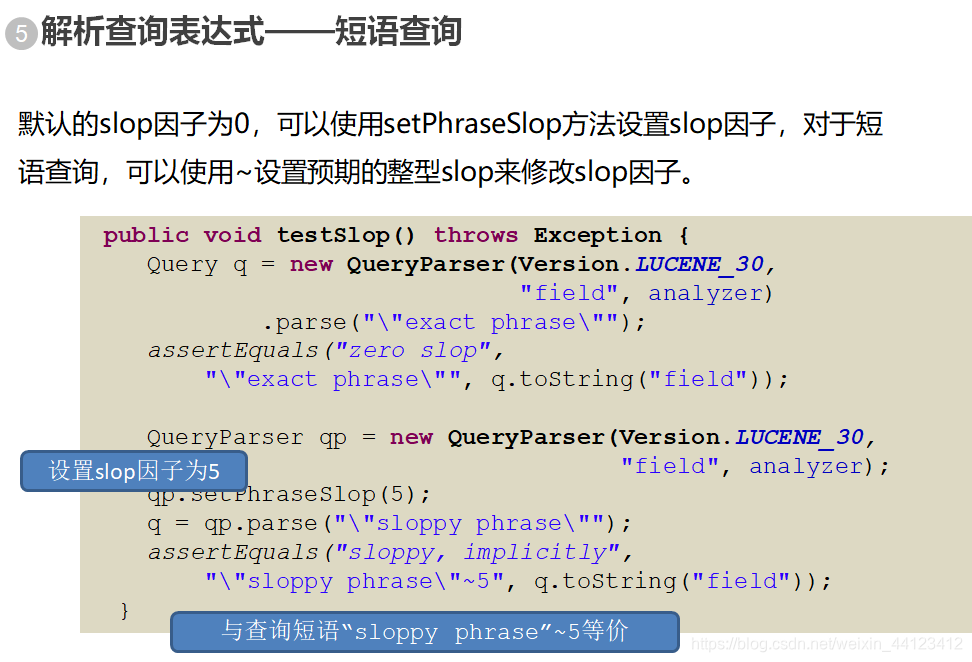
在匹配的情况下,两个项之间所允许的最大间隔距离称为slop。这里的距离指的是若要按照顺序组成给定短语所需要移动位置的次数。
还是匹配”the quick brown fox jumped over the lazy”字符串,像这个组合{“quick”“ fox”},因为查询目标是这样的“…quick 【brown】 fox …”就应该设置slop为不小于1,而{“ fox”“quick”}就应该设置slop为
不小于3.
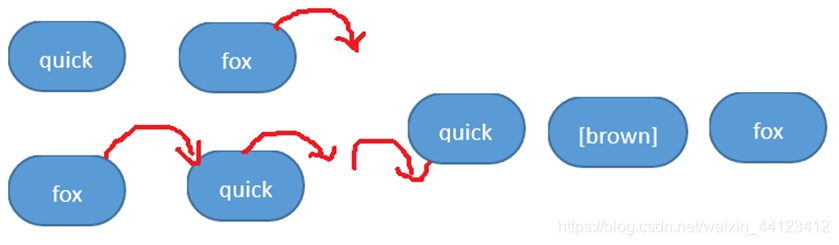
Lucene多样化查询————复合短语查询
示例:matched方法用于构建短语查询对象
private boolean matched(String[] phrase, int slop)
throws IOException {
// 构建短语查询
PhraseQuery query = new PhraseQuery();
query.setSlop(slop);
//添加短语序列
for (String word : phrase) {
query.add(new Term(“field”, word));
}
现在假设还是查询包含短语”the quick brown fox jumped over the lazy”的文档,分别使用语句创建短语查询,无论短语中包含多少项,slop因子规定了按顺序一定的最大值。
matched(new String[] {“quick”, “jumped”, “lazy”}, 3)); // slop值不够,查不到
matched(new String[] {“quick”, “jumped”, “lazy”}, 4)); // slop值足够,查得到
matched(new String[] {“lazy”, “jumped”, “quick”}, 7)); // slop值不够,查不到
matched(new String[] {“lazy”, “jumped”, “quick”}, 8)); // slop值足够,查得到
Lucene多样化查询————短语查询评分
短语查询是根据匹配所需要编辑的距离进行评分的,项之间的距离越小,具有的权重值就越大,评分与距离成反比关系,距离越大的匹配其评分就越低。
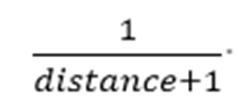
Lucene多样化查询————通配符查询:WidcardQuery
通配符查询允许用户使用不完整的的项进行查询,Lucene使用标准的
通配符如下:(0个或者任意个字符),?(0个或者1个任意字符),其实
WidcardQuery 完全可以看作更通用的PrefixQuery。
Term t = new Term(“contents”, “?Ild");
//构建Widcardquery对象
Query query = new WildcardQuery(t);
NOTE: 使用通配符查询可能会降低系统性能。较长的前缀
(第一个通配符前面的字符)可以有效减少用于查询匹配枚举
项目的个数。以通配符为首的模糊查询模式会强制枚举所有索引中的项来进行匹配。
Lucene多样化查询————搜索类似项:FuzzyQuery
FuzzyQuery用于查询与制定项类似的项,使用Levenshtein距离算法来决
定索引文件的项与指定项的相似程度。例如,“three”与“tree”两个字符
串编辑距离为1,因为只要删除一个字符就一样了。
Term t = new Term(“contents”, “tree");
//构建FuzzyQuery对象
Query query = new FuzzyQuery(t);
WARNING: FuzzyQuery类会尽可能枚举索引中的所有项,应尽量少用此类查询
Lucene多样化查询——匹配所有文档:MatchAllDocsQuery
MatchAllDocsQuery类就是匹配索引中的所有文档,这个类对匹配的文档分配一个固定的评分,该文档具体的查询加权默认值为1.0
如果使用这种查询作为顶层查询,除了使用默认的相关性排序外,建议通过域来进行排序。
示例:
Term t = new Term(“contents”, “tree");
//构建FuzzyQuery对象
Query query = new MatchAllDocsQuery(t);
NOTE: 执行完这种查询会根据特定域的加权情况来被评分。
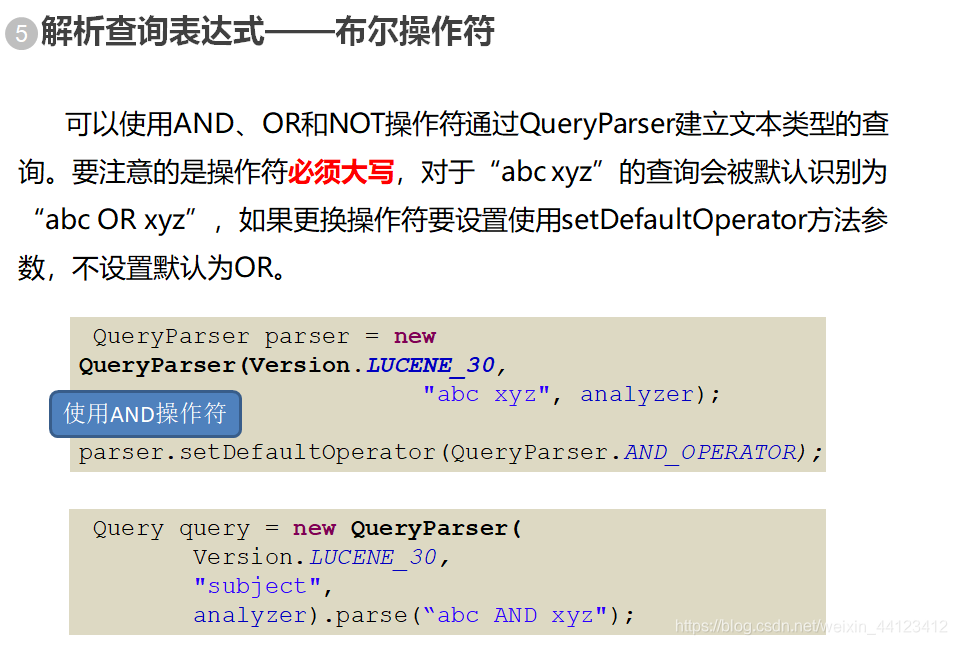
解析查询表达式——QueryParser
完全通过API来创建查询对象在有些场景下显得过于麻烦,所以Lucene支持使用自然语言来表示查询表达式。如前面例子里面出现的:
………
//查询包含"patent"的文档
String queryExpression = “patent”;
Directory directory = FSDirectory.open(new File(indexDir));
QueryParser parser = new QueryParser(Version.LUCENE_30,
“contents”, new SimpleAnalyzer());
//解析生成query对象
Query query = parser.parse(queryExpression);
System.out.println("Query: " + queryExpression);
IndexSearcher searcher = new IndexSearcher(directory);
TopDocs topDocs = searcher.search(query, 10);
……




















 294
294











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









